Natural Language Processing (NLP) algorithms and models are great at processing digital text, but many real-world applications use documents with more complex formats. Common examples include forms, lab results, academic papers, receipts, genomic sequencing reports, signed legal agreements, clinical trial documents, application forms, invoices, and scanned documents.

Despite the widespread use of pre-training models for NLP applications, they almost exclusively focus on text-level manipulation while neglecting layout and style information – which are vital for document image understanding. However, new advances in multi-modal learning – combining deep learning and transfer learning techniques from both NLP and computer vision – allows models to extract data from PDF and visual documents more accurately, along with a greater degree of efficiency.
John Snow Labs’ Spark OCR is the first software library to offer production-grade, scalable, and trainable implementations of these new techniques. This post summarizes the new capabilities that transition the library from “just” an accurate & scalable OCR solution into a modern Visual NLP solution.
Constraints of Traditional OCR
Traditional Object Character Recognition (OCR) solutions first translate an image to digital text. This then enables using NLP models to classify or extract information from that text. This approach often works but loses the visual information in the original image – for example, the difference between “look for text formatted as a date” and “look for text formatted as a date, which appears around the top right of the page.”
Although these models have made significant progress in the document AI area with deep neural networks, most of these methods confront two limitations:
- They rely on a few human-labeled training samples without fully exploring the possibility of using large-scale unlabeled training samples.
- They usually leverage either pre-trained CV models or NLP models but do not consider a joint training of textual and layout information. Therefore, it is vital to investigate how self-supervised pre-training of text and layout may help in the document AI.
The bottom line is that relying solely on traditional OCR + NLP pipelines limits the achievable accuracy – because the useful visual information is lost in translation.
Multimodal Learning Techniques
Nowadays, many companies extract data from business documents through manual efforts that are time-consuming and expensive, requiring manual customization or configuration. Rules and workflows for each document often need to be hard-coded and updated with changes to the specific format or when dealing with multiple formats. Document AI models and algorithms automatically identify, extract, and structuralize information from business documents, expediting automated document processing workflows to address these challenges. These machine learning techniques can take advantage of different modalities of data – in this case, combining natural language processing and computer vision – which are called multimodal learning techniques.
LayoutLM is a recent (2020) pre-training method for multimodal text and layout for document image understanding tasks. LayoutLM provides a powerful tool for modeling the interaction of text and layout information in scanned documents. Based on the Transformer architecture as the backbone, LayoutLM takes advantage of multimodal inputs, including token embeddings, layout embeddings, and image embeddings. Meanwhile, data scientists can efficiently train the model in a self-supervised way based on large-scale unlabeled scanned document images. Experiments show that LayoutLM substantially outperforms several state-of-the-art (SOTA) benchmarks in terms of accuracy – including form understanding and receipt understanding.
Visual Document Classification (Spark OCR 3.0)
Document classification is one of the most common NLP use cases in practice. It applies when you’re looking to sort incoming mail, invoices, faxes, or online files; filter websites based on language, inappropriate content, or category; or split academic papers based on whether they are theoretical or experimental, or at which stage of clinical trials they report on.
Spark OCR 3.0 is the first production model that combines text extraction and visual arrangement and provides the new VisualDocumentClassifier – a trainable, scalable, and highly accurate multi-modal document classifier. It is based on the deep-learning architecture proposed in LayoutLM. Spark OCR 3.0 also extended the support for Apache Spark 3.0.x and 3.1.x major releases on Scala 2.12 with both Hadoop 2.7. and 3.2.

GPU Optimized Image Enhancement (Spark OCR 3.1)
Real-world documents are often low-quality images. Faxed documents can be faded. Scanned documents can be rotated, upside down, or add noisy “salt” to the original text. Documents snapped with smartphone cameras can include shading, crumpled paper, distortion due to the camera being at an angle, or showing the hand holding the document in the photo. The form can include handwriting, manual annotations and corrections, checkboxes, and circled choices.
Therefore, a strong OCR or Visual NLP library must include a set of image enhancement filters that implements image processing and computer vision algorithms that correct or handle such issues. Spark OCR includes over 15 such filters, and the 3.1 release implemented GPU image processing to speed up image processing – 3.5 times faster than on CPU. The GPUImageTransformer allows running image transformation on GPU in Spark OCR pipelines and combines the following features-
- GPUImageTransformer with support: scaling, erosion, delation, Otsu and Huang thresholding.
- Added display_images util function for display images from Spark DataFrame in Jupyter notebooks.
Visual Entity Recognition (Spark OCR 3.2)
Extracting named entities from documents is the core of most information extraction or question answering tasks. Which molecule is this paper about? What is the total liability in this legal contract? Which abnormal test results does this patient have? When does this lease start? What’s the sales tax paid as part of this invoice? What kind of drug adverse event happened here?
Spark 3.2 adds multimodal visual named entity recognition, inspired by the LayoutLM architecture. It achieves new state-of-the-art accuracy in several downstream tasks, including form understanding and receipt understanding. The following new features have been added in Spark OCR 3.2:
- VisualDocumentNER is the DL model for NER problems using text and layout data. This model is currently available as a pre-trained model on the scanned receipts OCR and information extraction (SROIE) dataset.
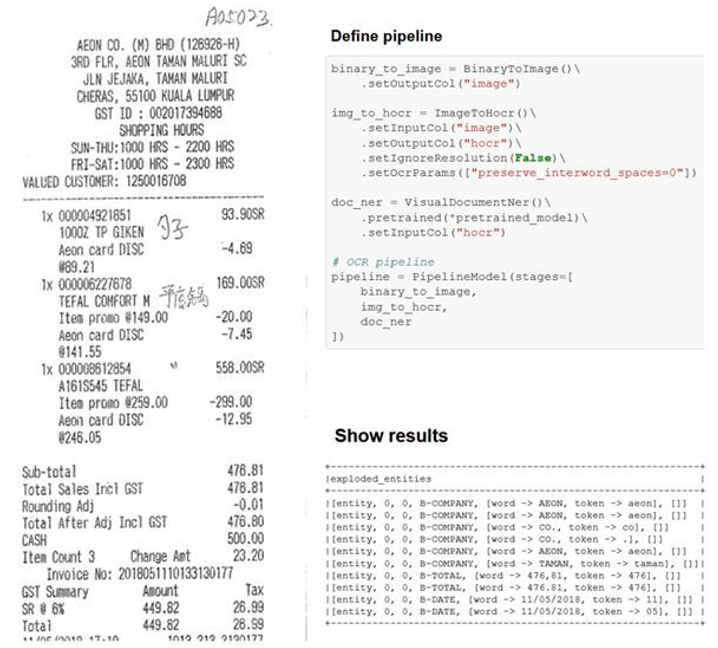
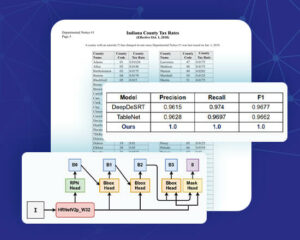
Table Detection and Extraction (Spark OCR 3.3)
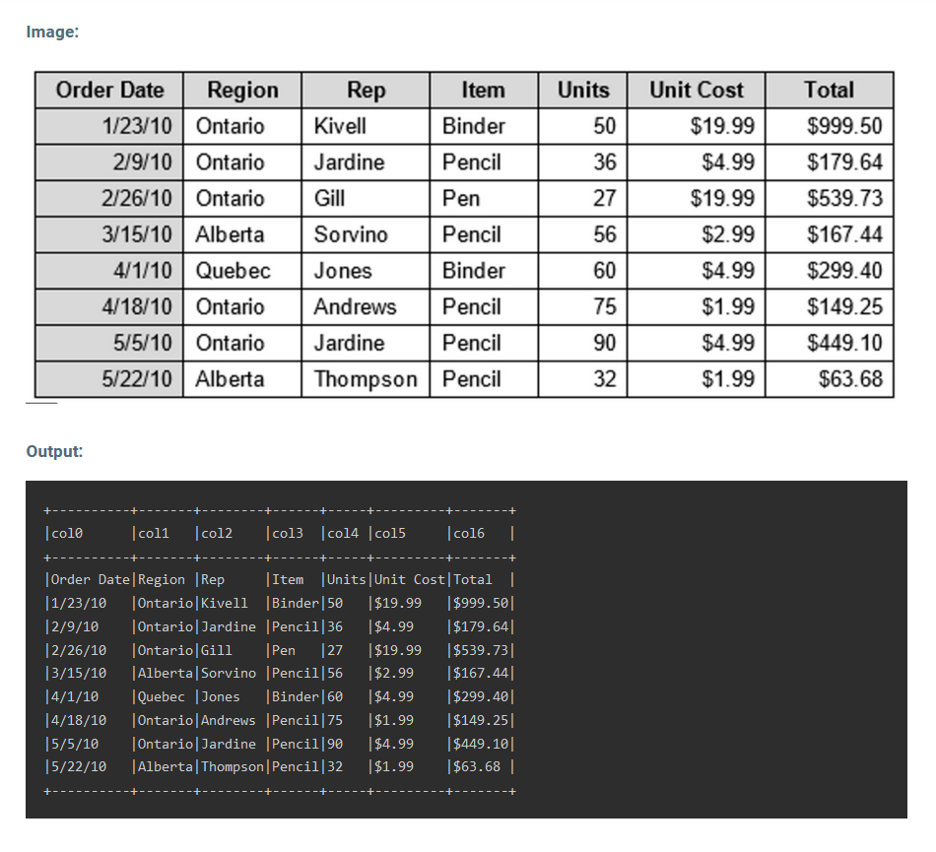
Another frequent requirement is to be able to extract whole data tables from visual documents. Tables are often optimized to be human-readable – including headers, pivots, summary rows, comments, bold and highlighted cells, and other visual features which make the data easier to read for people, but harder to extract for machines.
Earlier versions of Spark OCR already support extracting selectable-text tables from PDF and DOCX documents (PDF OCR). The 3.3 release adds the ability to add tables that are only available as images – meaning that computer vision deep-learning models are required to identify tables within the document; then identify rows, columns, and cells; and then extract the contents of each cell using local OCR.
The new ImageTableDetector is added based on CascadeTabNet, which uses Cascade mask Region-based CNN High-Resolution Network (Cascade mask R-CNN HRNet). The model was pre-trained on the COCO dataset and fine-tuned on ICDAR 2019 competitions dataset for table detection and demonstrates the state-of-the-art results for ICDAR 2013 and TableBank, besides holding top results for ICDAR 2019. Spark OCR 3.3 bundles the following new features and notebooks:
- ImageTableDetector is a DL model for detecting tables on the image.
- ImageTableCellDetector is a transformer for detecting regions of cells in the table image.
- ImageTableDetector is a transformer for extracting text from the detected cells.
New notebooks added to Spark OCR 3.3:
What’s Next?
Computer vision has brought impressive advances to numerous areas, including medical diagnostics, robotics, and autonomous driving. In this post, we’ve described how Visual NLP unlocks new document understanding capabilities – which are available today in a production-grade, scalable, and actively developed and supported codebase.
The functionality described here is already in use by our customers – enabling new applications that were never viable before. We are actively working on extending it in multiple areas:
- Adding more visual elements that can be accurately detected on a document or form (signature, dates, handwriting, checked boxes)
- Providing out-of-the-box support for forms and handwriting in more human languages
- Supporting the visual detection of more types of tables (borderless tables, multi-level tables, normalizing data elements like foreign currency or country-specific number formats)
These improvements and more will be released over the next few months, prioritized by our customers’ needs. We also keep improving the deep learning and transfer learning models – to improve accuracy, speed, and scale – and will continue reimplementing better models & algorithms as new research in this fast-moving field is published.
Visual NLP as an approach that marries computer vision and NLP has reached a level of maturity and real-world applicability that the industry is just starting to apply. You have our commitment that we will keep providing you with the state-of-the-art of this exciting new field.