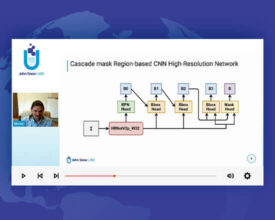
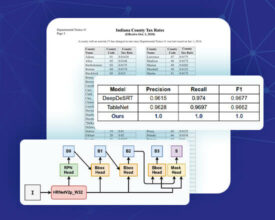
Extracting data formatted as a table (tabular data) is a common task — whether you’re analyzing financial statements, academic research papers, or clinical trial documentation. Table-based information varies heavily in...
Introduction to Table Extraction The amount of data collected is increasing every day with many applications, tools, and online platforms booming in the current digital age. To make sense of,...
How to detect signature in image-based documents For document comprehension pipelines in the healthcare and the financial area, we need some time to detect the signature of the document or...
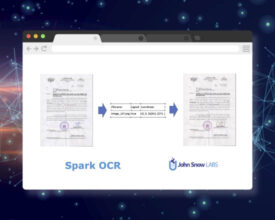
Motivation Spark OCR already contains an ImageToText transformer for recognising text on the image. It works fine for documents in general, but needs custom preprocessing to recognise text contained on...
Converting tables in scanned documents & images into structured data Motivation Extracting data formatted as a table is a common task - whether you’re analyzing financial statements, academic research papers,...





























 Demos
Demos






























 See More
See More