


























































Sequence classification with transformers refers to the task of predicting a label or category for a sequence of data, which can include text as well as other types of data such as audio, images, or time series. Many different transformer models have already been implemented in Spark NLP, and specifically for text classification, Spark NLP provides various annotators that are designed to work with pretrained language models.

Sequence classification with transformers is a powerful technique in the field of natural language processing (NLP) that involves predicting a label or category for a sequence of data. This sequence can be made up of text, as well as other types of data like audio, images, or time series.
Transformers are defined as a specific type of neural network architecture that have proven to be particularly effective for sequence classification tasks, thanks to their ability to capture long-term dependencies and contextual relationships in the data. This has led to significant advances in a variety of applications, from sentiment analysis and language translation to speech recognition and image captioning.
Text classification with NLP and transformers refers to the application of deep learning models based on the transformer architecture to classify sequences of text into predefined categories or labels. The transformer architecture was introduced by Vaswani et al. in 2017, and has since become a popular choice for NLP tasks due to its ability to capture long-range dependencies and context in sequential data.
Text classification with transformers involves using a pretrained transformer model, such as BERT, RoBERTa, or DistilBERT, to classify input text into one or more predefined categories or labels. The model is fine-tuned on a specific text classification task using labeled training data, adjusting the weights of the pretrained model to fit the new task. The model takes in the input text, preprocesses it, and encodes it through multiple layers of the transformer architecture, generating a representation of the input sequence. The final representation is then used to predict the probability distribution over the predefined categories or labels, and the category with the highest probability is selected as the predicted label for the input text.
BERT (Bidirectional Encoder Representations from Transformers) is a language model that was introduced by Google in 2018. It is based on the transformer architecture and is trained on large amounts of unlabeled text data to learn high-quality representations of language.
BERT is a “pre-trained” language model, which means it is first trained on a large corpus of text data in an unsupervised manner, without any specific task in mind. This allows it to learn general patterns and relationships in the language that can be useful for a wide range of downstream NLP tasks.
BERT-based Transformers are a family of deep learning models that use the transformer architecture. The table shows the language models and the corresponding annotators for text classification provided by Spark NLP.
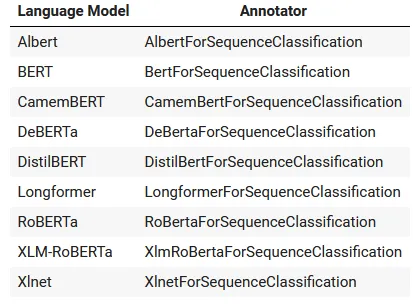
List of language models based on the transformer architecture and the annotators provided by Spark NLP
One of the key advantages of using BERT-based Transformers for sequence classification is their ability to capture the meaning and context of the input sequence in a more sophisticated way than traditional neural networks. This is because BERT is pretrained on a large corpus of text data, and the pre-training process involves learning to predict missing words or sentences in a given context. This allows the BERT model to understand the relationships between different words and phrases within the input sequence, and to generate a more informative representation of the sequence.
Spark NLP has multiple approaches for text classification. In this article, we will discuss using state-of-the-art BERT-based models or transformer-based models for this task.
Let us start with a short Spark NLP introduction and then discuss the details of sequence classification with some solid results.
Introduction to Spark NLP
Spark NLP is an open-source library maintained by John Snow Labs. It is built on top of Apache Spark and Spark ML and provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment.
Since its first release in July 2017, Spark NLP has grown in a full NLP tool, providing:
- A single unified solution for all your NLP needs
- Transfer learning and implementing the latest and greatest SOTA algorithms and models in NLP research
- The most widely used NLP library in industry (5 years in a row)
- The most scalable, accurate and fastest library in NLP history
Spark NLP comes with 17,800+ pretrained pipelines and models in more than 250+ languages. It supports most of the NLP tasks and provides modules that can be used seamlessly in a cluster.
Spark NLP processes the data using Pipelines, structure that contains all the steps to be run on the input data:
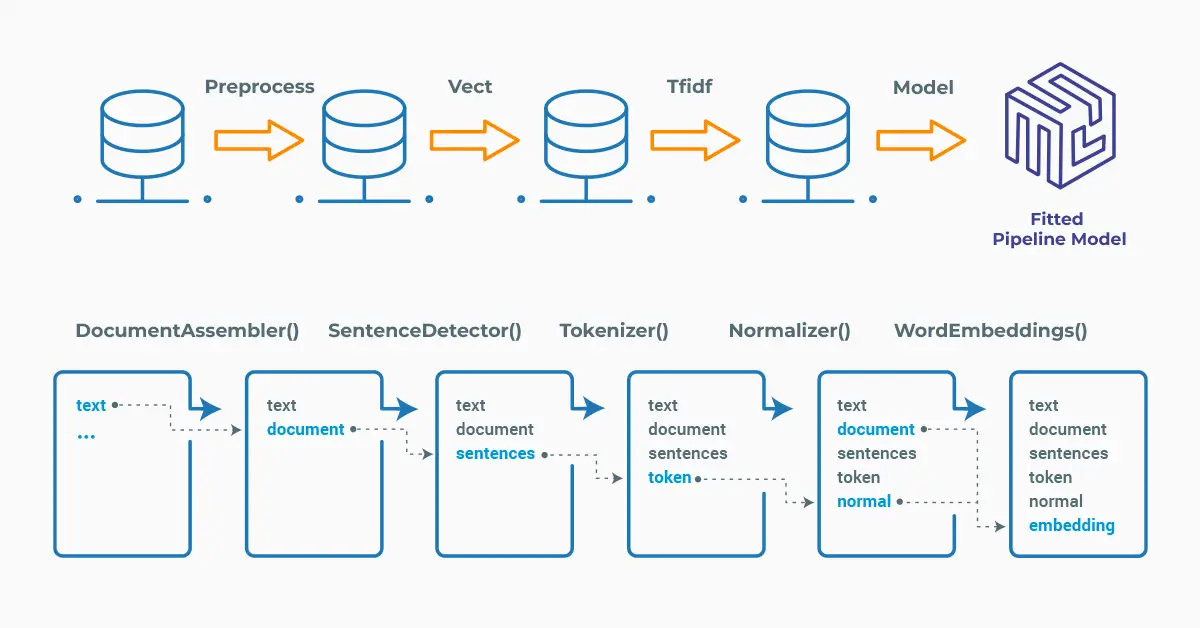
Spark NLP pipelines
Each step contains an annotator that performs a specific task such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
An annotator in Spark NLP is a component that performs a specific NLP task on a text document and adds annotations to it. An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. For example, a named entity recognizer annotator might identify and tag entities such as people, organizations, and locations in a text document, while a sentiment analysis annotator might classify the sentiment of the text as positive, negative, or neutral.
Setup
To install Spark NLP in Python, simply use your favorite package manager (conda, pip, etc.). For example:
pip install spark-nlp pip install pyspark
For other installation options for different environments and machines, please check the official documentation.
Then, simply import the library and start a Spark session:
import sparknlp # Start Spark Session spark = sparknlp.start()
BertForSequenceClassification
One of the tasks for which BERT can be fine-tuned is sequence classification, which involves assigning a label or category to a sequence of text. For example, sentiment analysis, which involves determining the sentiment of a piece of text as positive, negative, or neutral, can be framed as a sequence classification task.
BERT for sequence classification involves fine-tuning the pretrained BERT model on a specific sequence classification task. The process involves feeding a sequence of tokens (words, punctuation, and other symbols) into the BERT model, which generates a contextualized representation of each token. These token representations are then fed through a classification layer (such as a fully connected neural network) to predict the label or category of the sequence.
To understand the concept better, we will use the following model: Bert Base Movie Sentiment Analysis, where the model automatically determines whether a movie review has Positive or Negative sentiment using the BertForSequenceClassification annotator of Spark NLP. Model’s homepage will give you detailed information about the model, its size, data source used for training, benchmarking (metrics about the performance) and a sample pipeline showing how to use it.
The BertForSequenceClassification annotator expects DOCUMENT and TOKEN as input, and then will provide CATEGORY as output.
Please check the details of the pipeline below, where we define a short pipeline (just 3 stages) for text classification:
from sparknlp.base import DocumentAssembler
from sparknlp.annotator import Tokenizer, BertForSequenceClassification
from pyspark.ml import Pipeline
import pyspark.sql.functions as F
document_assembler = DocumentAssembler() \
.setInputCol('text') \
.setOutputCol('document')
tokenizer = Tokenizer() \
.setInputCols(['document']) \
.setOutputCol('token')
bert_cls = BertForSequenceClassification.pretrained("bert_classifier_fabriceyhc_base_uncased_imdb", "en") \
.setInputCols(['document', 'token']) \
.setOutputCol('class')
pipeline = Pipeline(stages=[document_assembler,
tokenizer,
bert_cls])
In Spark ML, we need to fit the obtained pipeline to make predictions (see this documentation page if you are not familiar with Spark ML).
After that, we define a movie review and we get predictions for this text by transforming the model.
text = "A heartwarming and funny movie about the secret lives of toys. A classic animated movie for all ages."
example_df = spark.createDataFrame([[text]]).toDF("text")
model = pipeline.fit(example_df)
result = model.transform(example_df)
Let’s see the probabilities of Positive and Negative sentiment in the text:
result.select("class").show(truncate=False)</code> <img class="size-full wp-image-82611 aligncenter" style="width: 50%;" src="https://www.johnsnowlabs.com/wp-content/uploads/2023/05/1_h0Z78RIElXedkGTSg1KeuQ.webp" alt="" /></pre>
</div>
We can also show the result directly:
<div class="oh">
<pre><code>result.select("class.result").show(truncate=False)
Using LightPipeline
LightPipeline is a Spark NLP specific Pipeline class equivalent to Spark ML Pipeline. The difference is that its execution does not hold to Spark principles, instead it computes everything locally (but in parallel) in order to achieve fast results when dealing with small amounts of data. This means, we do not input a Spark Dataframe, but a string or an array of strings instead, to be annotated.
Check this post to learn more about this class.
We can get predictions by running the following code:
text = "The film didn't make me cry, or laugh, or even think about it. I left the theater the same way I went in. What about the screenplay? Is it necessary to repeat the same situation ten times just to give the audience an idea of the hard time he had along with his kid? Also the relationship with his wife is weird. The film does not explain why she makes one of the most important decisions a woman can make in a lifetime. Is she bad, or just weak?" light_model= LightPipeline(model) light_result= light_model.fullAnnotate(text)[0]
We can show the results in a Pandas DataFrame by running the following code:
import pandas as pd
light_model = LightPipeline(model)
light_result = light_model.fullAnnotate(text)
results_tabular = []
for res in light_result[0]["class"]:
results_tabular.append(
(
text,
res.result
))
pd.DataFrame(results_tabular, columns=['text', "final_sentiment"])

LightPipeline sentiment prediction for the text
AlbertForSequenceClassification
AlbertForSequenceClassification annotator uses ALBERT (A Lite BERT), another BERT-based transformer model. It is a smaller and more efficient variation of BERT that was introduced by Google AI in 2019.
Let’s use this annotator and the Spark NLP model based on Albert to get sentiment analysis of a movie review:
from sparknlp.annotator import AlbertForSequenceClassification, SentenceDetector
document_assembler = DocumentAssembler() \
.setInputCol('text') \
.setOutputCol('document')
sentenceDetector = SentenceDetector()\
.setInputCols(["document"])\
.setOutputCol("sentence")
tokenizer = Tokenizer() \
.setInputCols(['sentence']) \
.setOutputCol('token')
albert_cls = AlbertForSequenceClassification \
.pretrained('albert_base_sequence_classifier_imdb', 'en') \
.setInputCols(['token', 'sentence']) \
.setOutputCol('class')\
.setCoalesceSentences(False)
pipeline = Pipeline(stages=[document_assembler,
sentenceDetector,
tokenizer,
albert_cls])
Next, we define a text involving a movie prediction and get predictions for this text by transforming the model.
text = "A timeless Disney classic with memorable characters and unforgettable songs."
example_df = spark.createDataFrame([[text]]).toDF("text")
model = pipeline.fit(example_df)
result = model.transform(example_df)
See the result for sentiment prediction:
result.select("class.result").show(truncate=False)
One-liner alternative
In October 2022, John Snow Labs released the open-source johnsnowlabs library that contains all the company products, open-source and licensed, under one common library. This simplified the workflow especially for users working with more than one of the libraries (e.g., Spark NLP + Healthcare NLP). This new library is a wrapper on all John Snow Lab’s libraries, and can be installed with pip:
pip install johnsnowlabs
Please check the official documentation for more examples and usage of this library. To run the Fake News Identification model with one line of code, we can simply use the following code:
from johnsnowlabs import nlp
result_nlp = nlp.load("en.classify.albert.imdb").predict("""A fun and exciting superhero movie with an all-star cast and impressive action sequences.""")
result_nlp[['sentence', 'classified_sequence']]
One-liner model sentiment prediction for the movie review
The one-liner is based on default models for each NLP task. Depending on your requirements, you may want to use the one-liner for simplicity or customizing the pipeline to choose specific models that fit your needs.
NOTE: when using only the johnsnowlabs library, make sure you initialize the spark session with the configuration you have available. Since some of the libraries are licensed, you may need to set the path to your license file. If you are only using the open-source library, you can start the session with spark = nlp.start(nlp=False). The default parameters for the start function includes using the licensed Healthcare NLP library with nlp=True, but we can set that to False and use all the resources of the open-source libraries such as Spark NLP, Spark NLP Display, and NLU.
DistilBertForSequenceClassification for French
DistilBertForSequenceClassification annotator uses DistilBERT, another BERT-based transformer model that was introduced by Hugging Face in 2019. DistilBERT is a small, fast, cheap and light transformer model trained by distilling the BERT base. Knowledge distillation is performed during the pre-training phase to reduce the size of a BERT model by 40%.
Let’s use this annotator and the Spark NLP model for texts in French, based on DistilBERT used for to getting sentiment analysis in a text:
from sparknlp.annotator import DistilBertForSequenceClassification
document_assembler = DocumentAssembler() \
.setInputCol('text') \
.setOutputCol('document')
tokenizer = Tokenizer() \
.setInputCols(['document']) \
.setOutputCol('token')
distilbert_cls = DistilBertForSequenceClassification.pretrained("distilbert_multilingual_sequence_classifier_allocine", "fr") \
.setInputCols(["document", "token"]) \
.setOutputCol("class")\
.setActivation("sigmoid")
pipeline = Pipeline(stages=[
document_assembler,
tokenizer,
distilbert_cls
])
Let’s use a long movie review in French to have an idea about the model’s efficiency for classification.
example_df = spark.createDataFrame([[
"""Deuxième long métrage de Pasolini, Mamma Roma contient déjà la plupart
des obsessions de son auteur et notamment la relation si importante
dans la construction de l’être humain entre la mère et son fils
adolescent. Anna Magnani est déchirante en figure presque universelle
de la maman putain représentative de la Ville éternelle. Le film avance
à travers des foules de symboles et la fin où le jeune homme termine
sa vie en crucifié martyr de la société est d’un implacable réalisme
poétique qui annonce les avancées extrêmes ultérieures de Salo.
La construction du récit est d’une puissance hors du commun et Pasolini
se montre déjà un grand cinéaste qui a assimilé la technique et les
possibilités de ce nouvel outil."""
]]).toDF("text")
model = pipeline.fit(example_df)
result = model.transform(example_df)
See the result for sentiment prediction in the movie review:
result.select("class.result").show()
One-liner alternative
Let’s see the one-liner alternative for the ‘DistilBERT Sequence Classification French — AlloCine’ model:
result_fr = nlp.load("fr.classify.distilbert_sequence.allocine").predict("""Une comédie dramatique touchante sur l'amitié improbable entre un aristocrate paralysé et son aide de camp d'origine sénégalaise.""")
result_fr[['sentence', 'classified_sequence', 'classified_sequence_confidence']]
One-liner model sentiment prediction for the movie review in French
For additional information, please consult the following references:
- Documentation: BertForSequenceClassification, AlbertForSequenceClassification, DistilBertForSequenceClassification.
- Python Docs: BertForSequenceClassification, AlbertForSequenceClassification, DistilBertForSequenceClassification.
- Scala Docs: BertForSequenceClassification,AlbertForSequenceClassification, DistilBertForSequenceClassification.
- For extended examples of usage, see the Spark NLP Workshop repository.
- For LightPipelines, check this post.
Conclusion
Using language models of the BERT-family for sequence classification tasks has become a popular and effective approach in NLP. Models such as BERT, RoBERTa, ALBERT, and DistilBERT have demonstrated state-of-the-art performance on a wide range of classification tasks, including sentiment analysis, spam detection, and text classification.
BERT-based Models for Advanced Text Classification are pretrained on large amounts of text data, allowing them to capture rich contextual information and produce high-quality representations of text. Moreover, they can be fine-tuned on specific downstream tasks using transfer learning techniques, making them adaptable to a wide range of classification tasks.
With the availability of pretrained models and tools in Spark NLP, it has become easier than ever to incorporate BERT-based language models into machine learning pipelines for sequence classification tasks.



