



























































Extract Hidden Insights from Texts at Scale with Regex Patterns

Information extraction in natural language processing (NLP) is the process of automatically extracting structured information from unstructured text data. In Spark NLP, the RegexMatcher is a component that is used to perform pattern matching on text data using regular expressions.
Information extraction is a subfield of NLP that involves automatically extracting structured information from unstructured or semi-structured textual data. With the vast amounts of text data being generated every day, ranging from social media posts to scientific literature, information extraction has become an essential tool for efficiently and effectively processing this data. As a result, many organizations rely on Information Extraction techniques to use solid NLP algorithms to automate manual tasks.
Regular expressions can be used for information extraction from text data. Regular expressions are a powerful tool for searching and pattern matching in text, and can be used to identify specific patterns of interest, such as phone numbers, email addresses, dates, or other types of entities. For example, a regular expression can be used to extract all the mentions of product names in customer reviews, or to extract all the dates mentioned in news articles.
RegexMatcher s a powerful annotator in Spark NLP for extracting information from text using regular expressions. Regular expressions (regex) are sequences of characters that define a pattern for matching text. Regular expressions are used to search for and manipulate text data in a flexible and powerful way, allowing for the extraction of specific patterns or structures from unstructured or semi-structured text data.
RegexMatcher annotator of Spark NLP allows to extract information that may not be covered by other built-in annotators. For example, you can use it to extract specific types of information, such as email addresses or phone numbers, that are not extracted by the built-in named entity recognition annotators.
In this post, you will learn how to identify patterns in text data that correspond to specific entities or events of interest by the RegexMatcher annotator of the Spark NLP library.
Let us start with a short Spark NLP introduction and then discuss the details of information extraction by regular expressions with some solid results.
Introduction to Spark NLP
Spark NLP is an open-source library maintained by John Snow Labs. It is built on top of Apache Spark and Spark ML and provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment.
Since its first release in July 2017, Spark NLP has grown in a full NLP tool, providing:
- A single unified solution for all your NLP needs
- Transfer learning and implementing the latest and greatest SOTA algorithms and models in NLP research
- The most widely used NLP library in industry (5 years in a row)
- The most scalable, accurate and fastest library in NLP history
Spark NLP comes with 17,800+ pretrained pipelines and models in more than 250+ languages. It supports most of the NLP tasks and provides modules that can be used seamlessly in a cluster.
Spark NLP processes the data using Pipelines, structure that contains all the steps to be run on the input data:
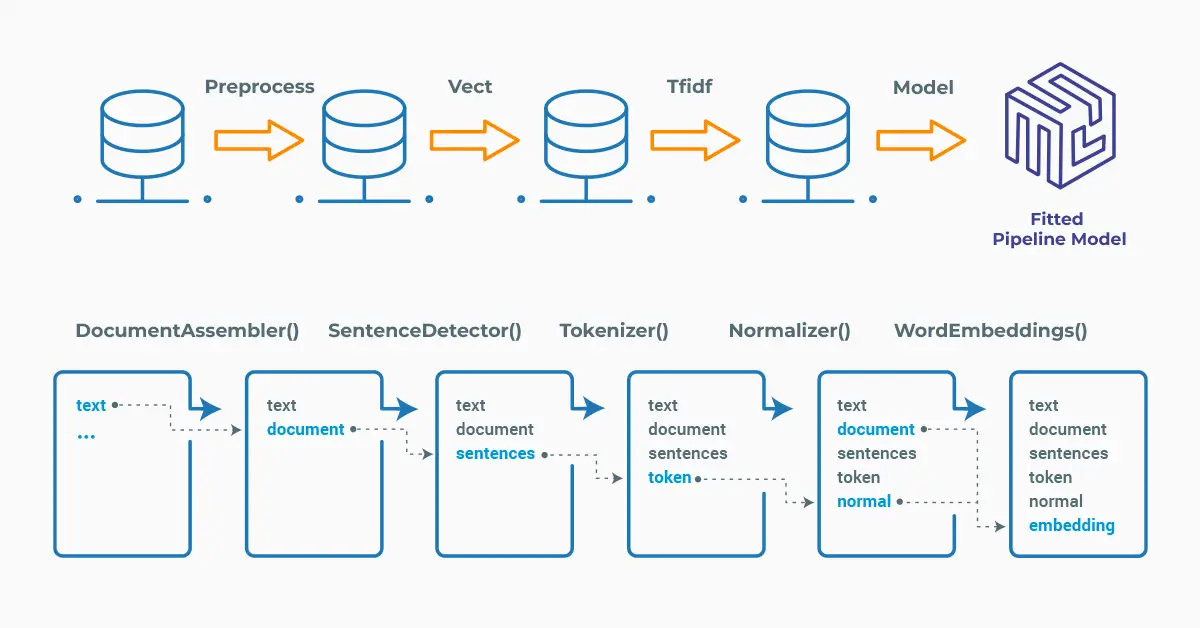
Spark NLP pipelines
Each step contains an annotator that performs a specific task such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
An annotator in Spark NLP is a component that performs a specific NLP task on a text document and adds annotations to it. An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. For example, a named entity recognizer annotator might identify and tag entities such as people, organizations, and locations in a text document, while a sentiment analysis annotator might classify the sentiment of the text as positive, negative, or neutral.
Setup
To install Spark NLP in Python, simply use your favorite package manager (conda, pip, etc.). For example:
pip install spark-nlp pip install pyspark
For other installation options for different environments and machines, please check the official documentation.
Then, simply import the library and start a Spark session:
import sparknlp # Start Spark Session spark = sparknlp.start()
RegexMatcher
Regex matching in Spark NLP refers to the process of using regular expressions (regex) to search, extract, and manipulate text data based on patterns and rules defined by the user. In regex matching, the user defines a pattern using a combination of literal characters and special characters or metacharacters that have special meaning within the regex engine. The RegexMatcher then searches the input text data for sequences of characters that match the defined pattern and returns the matching results.
The RegexMatcher works by taking a set of regular expressions as input and applying them to the text data. When a match is found, the RegexMatcher outputs the matched text along with its starting and ending positions in the input text.
RegexMatcher expects DOCUMENT as input, and then will provide CHUNK as output. Here’s an example of how you can use RegexMatcher in Spark NLP to extract dates with a specific format from unstructured text:
# Import the required modules and classes
from sparknlp.base import DocumentAssembler, Pipeline
from sparknlp.annotator import (
RegexMatcher
)
from pyspark.sql.types import StringType
import pyspark.sql.functions as F
# Step 1: Transform raw texts to `document` annotation
documentAssembler = DocumentAssembler()\
.setInputCol("text")\
.setOutputCol("document")
# Step 2: Define the regex rules
regex_matcher = RegexMatcher()\
.setRules(["\d{4}\/\d\d\/\d\d,date", "\s\d{2}\/\d\d\/\d\d,short_date"]) \
.setDelimiter(",") \
.setInputCols(["document"]) \
.setOutputCol("matched_text") \
.setStrategy("MATCH_ALL")
# Define the Pipeline
nlpPipeline = Pipeline(stages=[documentAssembler,regex_matcher])
In this example, \d{4}\/\d\d\/\d\d is used as the first rule to define the date and \s\d{2}\/\d\d\/\d\d is the definition of short date.
Let’s use a sample text to see the performance of the RegexMatcher annotator, then fit and transform the dataframe to get the results:
# Make a sample text
text_list = ["John Smith was born on 1965/12/10 in New York City.",
"He got married on 89/01/05 and started his new job on 91/03/11.",
"He went on a trip to Europe from 2022/06/11/2022 to 2022/07/05 and
visited 6 countries.",
"He celebrated his 10th wedding anniversary on 1999/01/05."]
# Convert the sample_text to a dataframe
spark_df = spark.createDataFrame(text_list, StringType()).toDF("text")
# Fit and transform to get a prediction
result = nlpPipeline.fit(spark_df).transform(spark_df)
Explode the results to a dataframe with two columns — matched dates and the identifier:
result.select(F.explode(F.arrays_zip(result.matched_text.result,
result.matched_text.metadata)).alias("cols")) \
.select(F.expr("cols['0']").alias("Matches Found"),
F.expr("cols['1']['identifier']").alias("identifier")).show()
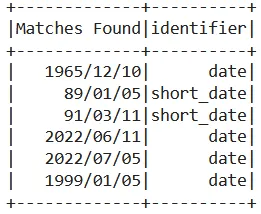
Matched dates and their labels defined in setRules.
It is also possible to define the rules as an external file.
For additional information, please check the following references.
- Documentation: RegexMatcher
- Python Docs: RegexMatcher
- Scala Docs: RegexMatcher
- For extended examples of usage, see the Spark NLP Workshop repository.
Conclusion
Information extraction is a crucial task in NLP that involves automatically extracting structured information from unstructured or semi-structured text data. RegexMatcher of Spark NLP allows users to define custom regular expressions to extract specific patterns from text data. Regular expressions provide a powerful solution to match and manipulate text, and they are supported by Spark NLP.
It is worth noting, however, that regular expressions have some limitations and can be difficult to maintain and extend for more complex patterns. In some cases, more advanced techniques, such as machine learning or deep learning may be required to extract information from text data.



