Motivation
Spark OCR already contains an ImageToText transformer for recognising text on the image. It works fine for documents in general, but needs custom preprocessing to recognise text contained on images that represent natural scenes.
To simplify text recognition on images with complex backgrounds, or even when the text is rotated, we added a Deep Learning based model to detect text.
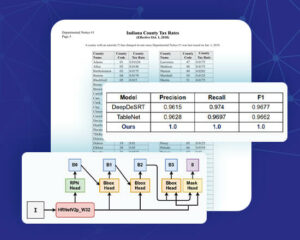
Let’s look into an image representing a real use case. In this particular example, we are interested in detecting the “Ref” and “Lot” numbers from the boxes.

Text detection can also help recognizing text present in documents, when the image is noised or contains a lot of graphical elements.
Load image
To work with images in Spark OCR, we need to load them to a Spark DataFrame. Let’s read an example image from the resources of the sparkocr python package using the binaryFile datasource:
imagePath = pkg_resources.resource_filename(‘sparkocr’, ‘resources/ocr/text_detection/020_Yas_patella.jpg’)binary_data_df = spark.read.format(“binaryFile”).load(imagePath)
Out next step is to convert the binary data to the internal Image format, and display the image. For displaying the image, we can call display_images():
binary_to_image = BinaryToImage() binary_to_image.setImageType(ImageType.TYPE_3BYTE_BGR)image_df = binary_to_image.transform(binary_data_df)display_images(image_df, “image”)
Detect text
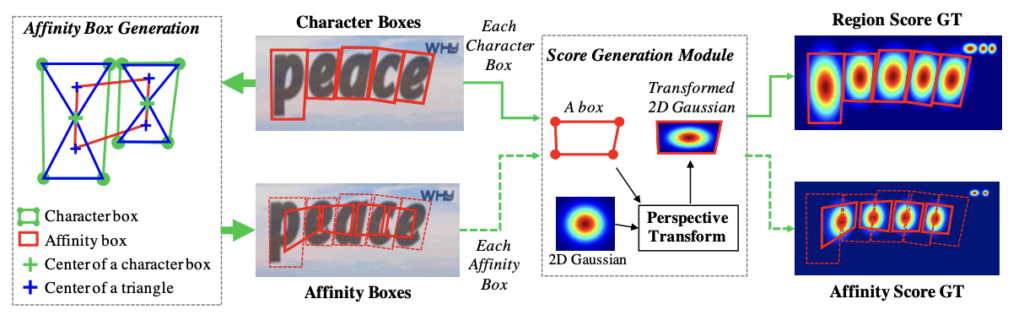
Following our pipeline definition, Spark OCR contains the ImageTextDetector transformer for detecting text on images. It is based on the “Character Region Awareness for Text Detection” model.
This NLP OCR model provides the character region(text) score and the character affinity(link) score that, together, fully cover various text shapes in a bottom-up manner.
Benchmarks
In this section we are going to present some of the results from the original paper. According to the authors,
Extensive experiments on six benchmarks, TotalText and CTW-1500
datasets that contain highly curved texts in natural images demonstrate that our character-level text detection significantly outperforms the state-of-the-art detectors. According to the results, our proposed method guarantees high flexibility in detecting complicated scene text images, such as arbitrarily oriented, curved, or deformed texts.
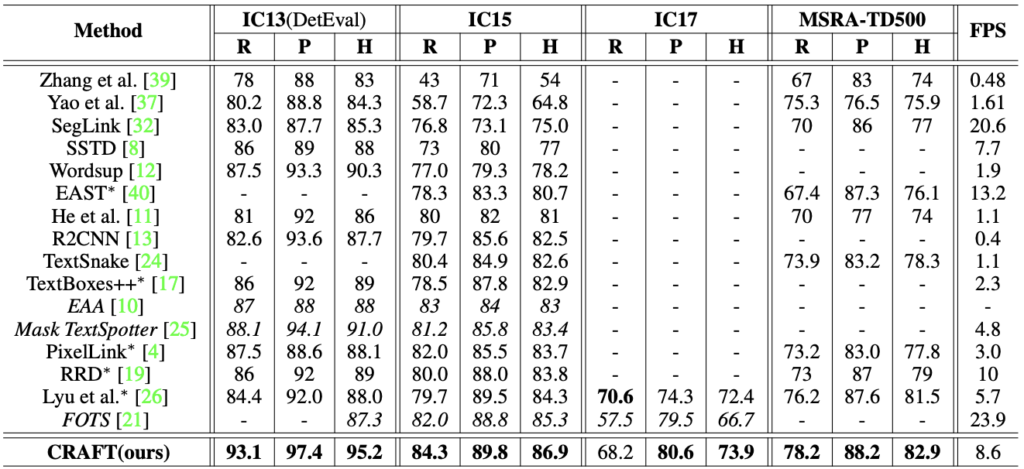
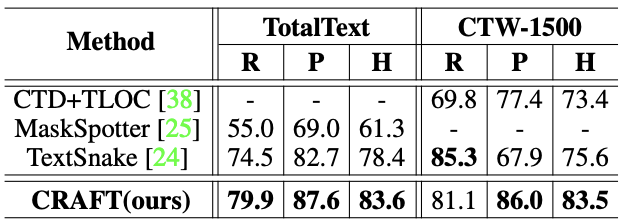
So these are super solid results that will help our final pipeline generalise to many different images and situations. This leads us to our final step; the Text Detection itself. Let’s jump into it!
The ImageTextDetector transformer
This is how we define our ImageTextDetector,
text_detector = ImageTextDetector.pretrained(“text_detection_v1”, “en”, “clinical/ocr”) text_detector.setInputCol(“image”) text_detector.setOutputCol(“text_regions”) text_detector.setSizeThreshold(10) text_detector.setScoreThreshold(0.9) text_detector.setLinkThreshold(0.4) text_detector.setTextThreshold(0.2) text_detector.setWidth(1512) text_detector.setHeight(2016)
- For filter detected character by size, we can set sizeThreshold.
- TextThreshold param is used for thresholding by character region score. LinkThreshold for affinity score.
- We can reduce memory usage and processing time by scaling image when set width and height params.
The output schema is:
root |-- col: struct (nullable = true) | |-- index: integer (nullable = false) | |-- page: integer (nullable = false) | |-- x: float (nullable = false) | |-- y: float (nullable = false) | |-- width: float (nullable = false) | |-- height: float (nullable = false) | |-- score: float (nullable = false) | |-- label: string (nullable = false) | |-- angle: float (nullable = false)
Show detected regions:
result.select(f.explode(“text_regions”)).show(10, False)+------------------------------------------------------------------+ |col | +------------------------------------------------------------------+ |[0, 0, 120.0, 662.0, 24.0, 36.0, 0.93, 0, -90.0] | |[0, 0, 192.90, 667.2792, 22.30, 117.72, 0.95, 0, -85.91] | |[0, 0, 275.0, 673.0, 22.0, 38.0, 0.93, 0, -90.0] | |[0, 0, 332.14, 679.37, 20.49, 80.81, 0.98, 0, -84.80] | |[0, 0, 818.0, 680.0, 24.0, 40.0, 0.964, 0, -90.0] | |[0, 0, 895.0, 681.0, 22.0, 134.0, 0.96, 0, -90.0] | |[0, 0, 980.0, 683.0, 18.0, 40.0, 0.94, 0, -90.0] | |[0, 0, 1039.0, 683.0, 22.0, 94.0, 0.96, 0, -90.0] | |[0, 0, 1343.98, 682.27, 14.75, 71.97, 0.97, 0, -86.82] | |[0, 0, 1247.0, 685.0, 18.0, 86.0, 0.93, 0, -90.0] | +------------------------------------------------------------------+
Let’s draw detected text regions to the original image using the ImageDrawRegions transformer:
draw_regions = ImageDrawRegions() draw_regions.setInputCol(“image”) draw_regions.setInputRegionsCol(“text_regions”) draw_regions.setOutputCol(“image_with_regions”) draw_regions.setRectColor(Color.green) draw_regions.setRotated(True)

Text recognition
As the next step, we should recognize text from detected regions using ImageToText. But before let’s split the original image into the sub-images by ImageSplitRegions:
splitter = ImageSplitRegions() \ .setInputCol(“image”) \ .setInputRegionsCol(“text_regions”) \ .setOutputCol(“text_image”) \ .setDropCols([“image”]) \ .setExplodeCols([“text_regions”]) \ .setRotated(True) \ .setImageType(ImageType.TYPE_BYTE_GRAY)ocr = ImageToText() \ .setInputCol(“text_image”) \ .setOutputCol(“text”) \ .setPageSegMode(PageSegmentationMode.SINGLE_WORD) \ .setIgnoreResolution(False)
Output:
REF 1518-10-029 LOT 8455732 REA 11518-20-029 . [LOT] 19129475 2024-03) | STERILE | R | ATTUNE™ (STERILE | R | 202* | ATTUNE™ PATELLA 2017-01-17. MEDIALIZED | PATELLA | ANATOMIC \ MEM A! IZED DOME QTY} .....
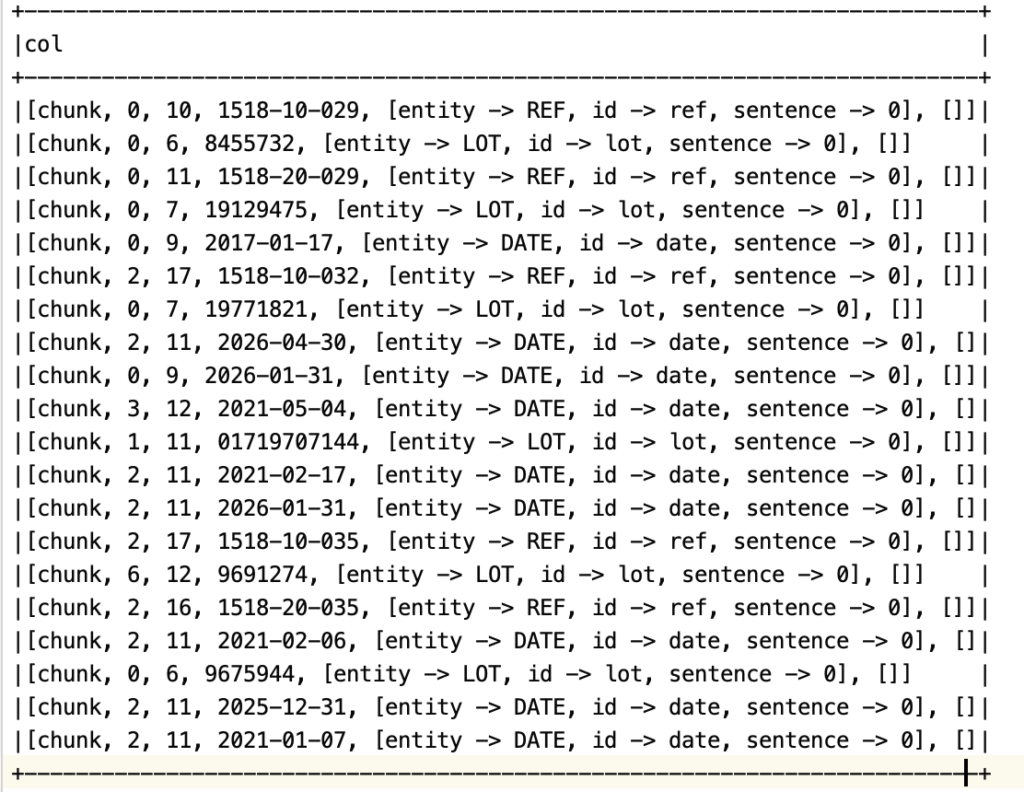
Extract Ref and Lot numbers
Spark NLP can help to extract fields from the recognized text. Let’s use EntityRulerApproach. We need to define patterns in the file:
{"id": "ref", "label": "REF", "patterns": ["\\d{4}-\\d{2}-\\d{3}"]}
{"id": "date", "label": "DATE", "patterns": ["\\d{4}-\\d{2}-\\d{2}"]}
{"id": "lot", "label": "LOT", "patterns": ["\\d{7}"]}
And now we can define the whole pipeline:
documentAssembler = DocumentAssembler() \
.setInputCol(“text”) \
.setOutputCol(“document”)tokenizer = Tokenizer() \
.setInputCols([“document”]) \
.setOutputCol(“token”)entityRuler = EntityRulerApproach() \
.setInputCols([“document”, “token”]) \
.setOutputCol(“entities”) \
.setPatternsResource(
“patterns.json”,
ReadAs.TEXT,
{“format”: “jsonl”}
) \
.setEnablePatternRegex(True)pipeline_nlp = Pipeline().setStages([
splitter,
ocr,
documentAssembler,
tokenizer,
entityRuler
])text_result = pipeline_nlp.fit(result).transform(result)text_result.selectExpr("explode(entities)").show(truncate=False)
Results
A notebook with a full example can be found here.