Stopwords removal in natural language processing (NLP) is the process of eliminating words that occur frequently in a language but carry little or no meaning. Removing stop words is useful when one wants to deal with only the most semantically important words in a text, and ignore words that are rarely semantically relevant, such as articles and prepositions.

Stopwords cleaning in Spark NLP is the process of removing stopwords from the text data. Stopwords are commonly occurring words (like the, a, and, in, etc.) in a language that carry little or no meaning and can hinder the performance of many natural language processing (NLP) tasks. Removing stopwords from the text data can significantly improve the accuracy of these tasks and reduce the computational resources needed for further processing.
With the StopWordsCleaner annotator, Spark NLP offers an efficient solution that can remove stopwords from the text in many languages, making it easier for NLP practitioners to integrate into their workflows. Additionally, Spark NLP offers the flexibility to customize the list of stopwords according to the specific application needs.
Removing stop words from a text document can be beneficial, as it can reduce noise, speed up processing and improve the accuracy of the results.
In this post, you will learn how to use Spark NLP’s StopWordsCleaner annotator to perform stop words cleaning using pretrained models efficiently.
Let us start with a short Spark NLP introduction and then discuss the details of the stopwords cleaning with some solid results.
Introduction to Spark NLP
Spark NLP is an open-source library maintained by John Snow Labs. It is built on top of Apache Spark and Spark ML and provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment.
Since its first release in July 2017, Spark NLP has grown in a full NLP tool, providing:
- A single unified solution for all your NLP needs
- Transfer learning and implementing the latest and greatest SOTAalgorithms and models in NLP research
- The most widely used NLP library in industry (5 years in a row)
- The most scalable, accurate and fastest library in NLP history
Spark NLP comes with 17,800+ pretrained pipelines and models in more than 250+ languages. It supports most of the NLP tasks and provides modules that can be used seamlessly in a cluster.
Spark NLP processes the data using Pipelines, structure that contains all the steps to be run on the input data:
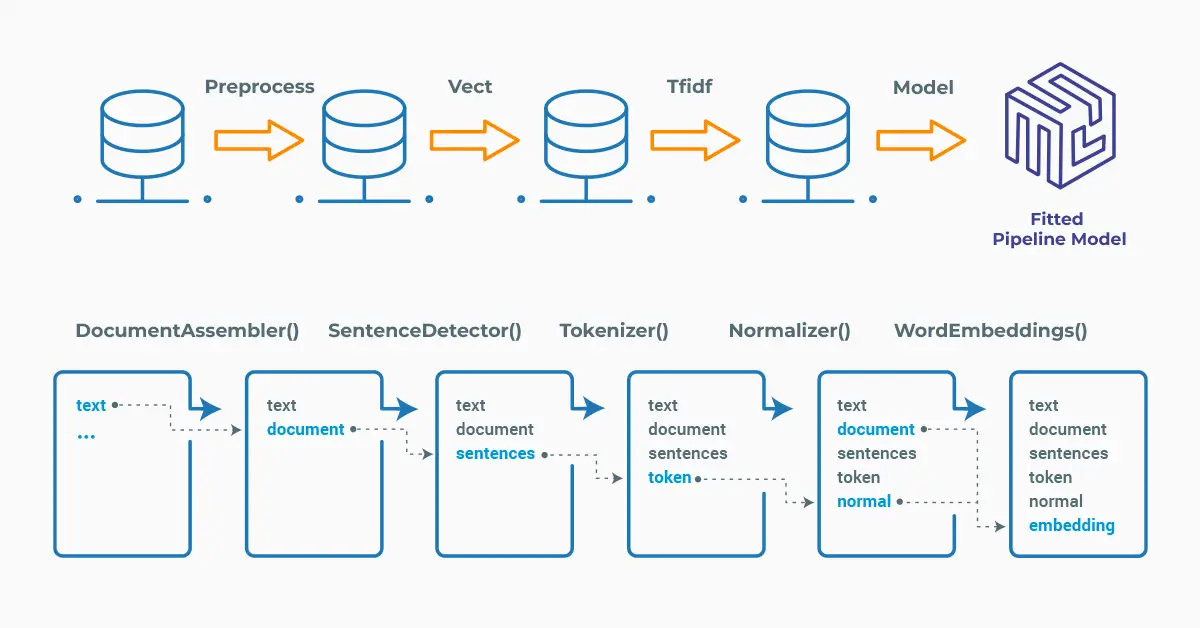
Spark NLP pipelines
Each step contains an annotator that performs a specific task such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
An annotator in Spark NLP is a component that performs a specific NLP task on a text document and adds annotations to it. An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. For example, a named entity recognizer annotator might identify and tag entities such as people, organizations, and locations in a text document, while a sentiment analysis annotator might classify the sentiment of the text as positive, negative, or neutral.
Setup
To install Spark NLP in Python, simply use your favorite package manager (conda, pip, etc.). For example:
pip install spark-nlp pip install pyspark
For other installation options for different environments and machines, please check the official documentation.
Then, simply import the library and start a Spark session:
import sparknlp # Start Spark Session spark = sparknlp.start()
StopWordsCleaner
Stopwords are a list of common words that are usually removed from text before analysis. They include words like “the,” “and,” “a,” etc. which do not carry much meaningful information but appear frequently in text. Stopword removal is a crucial step in text preprocessing because it helps reduce the size of text data and makes it easier to analyze. It also speeds up processing time and improves the efficiency of text-based algorithms.
Healthcare NLP Trends
In healthcare NLP, stopword cleaning has recently evolved from a basic preprocessing task into a key enabler of accuracy. Clinical pipelines now combine it with context filtering to better extract diagnoses, treatments, and medical histories from unstructured records. Optimized preprocessing techniques are widely regarded as an important factor in improving the precision of medical coding and streamlining clinical workflows.
Another important development is multilingual and domain-specific stopword handling. Since patient records are increasingly written in multiple languages, adapting stopword lists to local and medical contexts has become essential. Tailored preprocessing significantly improves entity extraction in mixed-language notes, supporting better outcomes in global research collaborations and telemedicine.
Looking ahead, stopword cleaning will also play a crucial role in making generative healthcare models safer and more reliable. As hospitals and insurers adopt LLMs for reporting, summarization, and compliance, efficient preprocessing reduces bias and minimizes hallucinations. Early pilots show that combining Spark NLP pipelines with large healthcare LLMs leads to more trustworthy AI-driven decision support.
These advances demonstrate how even a seemingly simple step like stopword cleaning is shaping the next generation of healthcare NLP.
Please check the John Snow Labs Models Hub for the available pretrained models.
Let’s take a look at the pipeline below and then run it on the sample text, to observe the efficiency of StopWordsCleaner.
# Import the required modules and classes
from sparknlp.base import DocumentAssembler, Pipeline
from sparknlp.annotator import (
SentenceDetector,
Tokenizer,
StopWordsCleaner
)
import pyspark.sql.functions as F
# Step 1: Transforms raw texts to `document` annotation
document_assembler = (
DocumentAssembler()
.setInputCol("text")
.setOutputCol("document")
)
# Step 2: Splits the text into separate sentences
sentence = (
SentenceDetectorDLModel.pretrained("sentence_detector_dl", "en")
.setInputCols(["document"])
.setOutputCol("sentence")
)
# Step 2: Gets tokens from the sentences
tokenizer = (
Tokenizer()
.setInputCols(["sentence"])
.setOutputCol("token")
)
# Step 3: Performs stopwords cleaning
stop_words = (
StopWordsCleaner().pretrained("stopwords_iso","en")
.setInputCols(["token"])
.setOutputCol("cleanTokens")
)
pipeline = Pipeline(stages=[document_assembler, sentence, tokenizer, stop_words])
After that, we feed the text and use the model to see the clean tokens — without stopwords.
sample_text = """
The quick brown fox jumped over the lazy dog. It was a beautiful day in
the park, with birds chirping and the sun shining brightly. As the fox
ran through the grass, it startled a group of rabbits who were munching on
some carrots. They quickly scurried away, leaving the fox to continue
its hunt. After a while, the fox grew tired and decided to take a nap under
a nearby tree. The dog watched from a distance, wagging its tail lazily.
Eventually, the sun began to set, and the sky turned a brilliant shade of
orange and pink. It was a perfect end to a perfect day.
"""
# Create a dataframe from the sample_text
prediction_data = spark.createDataFrame([[sample_text]]).toDF("text")
# Fit and transform to get a prediction
model = pipeline.fit(prediction_data)
result = model.transform(prediction_data)
# Display the results
result.select("cleanTokens.result").show(truncate = 200)

The tokens without the stopwords
Display the Cleaned Stopwords
After cleaning, we can see all the stopwords in the model (571 in total):
stop_words.getStopWords()

Some of the stopwords defined in the model
Using LightPipeline
LightPipeline is a Spark NLP specific Pipeline class equivalent to Spark ML Pipeline. The difference is that its execution does not hold to Spark principles, instead it computes everything locally (but in parallel) in order to achieve fast results when dealing with small amounts of data. This means, we do not input a Spark Dataframe, but a string or an array of strings instead, to be annotated.
Check this post to learn more about this class.
We can get predictions by running the following code:
from sparknlp.base import LightPipeline light_model = LightPipeline(model) light_result = light_model.fullAnnotate(sample_text)[0]
We can show the results in a Pandas DataFrame by running the following code:
import pandas as pd
keys_df = pd.DataFrame([(k.result, k.begin, k.end, k.metadata['sentence']) for k in light_result['cleanTokens']],
columns = ['cleanTokens','begin','end','sentence'])
keys_df.sort_values(['sentence']).head(100)
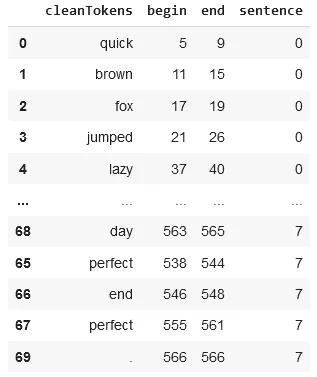
The dataframe shows the clean tokens after the removal of the stopwords from the text
Stopwords Cleaning for Other Languages
There are more than 100 models in the John Snow Labs Models Hub for non-English languages.
Let’s try one model for French:
stop_words = StopWordsCleaner.pretrained("stopwords_fr","fr") \
.setInputCols(["token"]) \
.setOutputCol("cleanTokens")
pipeline = Pipeline(stages=[documentAssembler, tokenizer, stop_words])
sample_text_fr = """
Le rapide renard brun sauta par dessus le chien paresseux. C'était une belle journée à
le parc, avec le chant des oiseaux et le soleil qui brille de mille feux. Comme le renard
couru dans l'herbe, il a fait sursauter un groupe de lapins qui grignotaient
quelques carottes. Ils se sont rapidement éloignés, laissant le renard continuer
sa chasse. Au bout d'un moment, le renard se fatigua et décida de faire une sieste sous
un arbre voisin. Le chien regardait de loin, remuant paresseusement la queue.
Finalement, le soleil a commencé à se coucher et le ciel a pris une teinte brillante de
orange et rose. C'était une fin parfaite pour une journée parfaite.
"""
example = spark.createDataFrame([[sample_text_fr]], ["text"])
results = pipeline.fit(example).transform(example)
results.select("cleanTokens.result").show(1, truncate = 200)
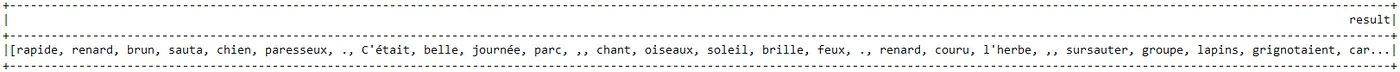
The tokens in the French text without the stopwords
Customize Your Own Stopwords
Instead of using the stopwords in the model, it is possible to define your list of stopwords by using the setStopWords parameter. Using a file is also an option.
As shown in the code below, this time we defined just two stopwords: ‘Tom’ and ‘Kashmir’, although they are not stopwords.
stop_words = StopWordsCleaner()\
.setInputCols(["token"]) \
.setOutputCol("cleanTokens") \
.setCaseSensitive(False)\
.setStopWords(["Tom", "Kashmir"])
#(We manually specified only 'is' and 'a' as stopwords.
prediction_pipeline = Pipeline(
stages = [
documentAssembler,
sentence,
tokenizer,
stop_words
]
)
prediction_data = spark.createDataFrame([[
"Tom is a nice man and he lives in Kashmir."]]).toDF("text")
result = prediction_pipeline.fit(prediction_data).transform(prediction_data)
result.select("cleanTokens.result").show(1, False)

As you can see from the result, only the words defined by the setStopWords parameter were cleaned and many stopwords are still in the text.
One-liner alternative
In October 2022, John Snow Labs released the open-source johnsnowlabs library that contains all the company products, open-source and licensed, under one common library. This simplified the workflow especially for users working with more than one of the libraries (e.g., Spark NLP + Healthcare NLP). This new library is a wrapper on all John Snow Lab’s libraries, and can be installed with pip:
pip install johnsnowlabs
Please check the official documentation for more examples and usage of this library. To run stopwords cleaner with one line of code, we can simply use the following code:
from johnsnowlabs import nlp
nlp.load('en.stopwords').predict("The dog watched from a distance, wagging its tail.", output_level='sentence')

After using the one-liner model, the result shows the text without the stopwords
The one-liner is based on default models for each NLP task. Depending on your requirements, you may want to use the one-liner for simplicity or customizing the pipeline to choose specific models that fit your needs.
NOTE: when using only the johnsnowlabs library, make sure you initialize the spark session with the configuration you have available. Since some of the libraries are licensed, you may need to set the path to your license file. If you are only using the open-source library, you can start the session with spark = nlp.start(nlp=False). The default parameters for the start function includes using the licensed Healthcare NLP library with nlp=True, but we can set that to False and use all the resources of the open-source libraries such as Spark NLP, Spark NLP Display, and NLU.
For additional information, please consult the following references.
- Documentation : StopWordsCleaner
- Python Docs : StopWordsCleaner
- Scala Docs : StopWordsCleaner
- For extended examples of usage, see the Spark NLP Workshop repository.
Conclusion
Stopwords are defined as the commonly occurring words in a language that carry little or no meaning and stopwords removal is a crucial step in many NLP applications. With StopWordsCleaner, Spark NLP offers pretrained models that can remove stopwords from the text data in many languages. Additionally, Spark NLP offers the flexibility to customize the list of stopwords according to the specific application needs.
By removing stopwords, the accuracy of downstream NLP tasks can be significantly improved, and the computational resources needed for processing can be reduced. The flexibility to customize the list of stopwords according to the specific application needs makes Spark NLP a valuable resource for NLP practitioners to streamline their workflows and produce meaningful and accurate results.
FAQ
- Why is stopword removal important in NLP?
Stopword removal helps eliminate frequent words that add little meaning, such as “the” or “and.” By reducing noise, it improves both the speed and accuracy of downstream NLP tasks like classification, entity recognition, and summarization. - How does Spark NLP handle stopword cleaning?
Spark NLP provides the StopWordsCleaner annotator with pretrained models for more than 100 languages. It allows efficient stopword filtering and supports custom lists for domain-specific needs. - Can I customize stopword lists for healthcare or other domains?
Yes. Spark NLP lets you define custom stopword lists or adapt existing ones. This is especially useful in healthcare, where certain terms may be frequent but contextually significant, requiring domain-aware filtering. - What recent trends affect stopword removal in healthcare NLP?
Preprocessing is becoming smarter: hospitals combine stopword cleaning with context filtering, multilingual handling, and continual updates. Studies show that optimized pipelines improve coding accuracy and reduce diagnostic errors. - How can stopword cleaning improve large language models (LLMs)?
When paired with LLMs, stopword cleaning reduces noise, minimizes hallucinations, and strengthens reliability. In healthcare and compliance-heavy fields, it supports safer, more transparent decision-making by ensuring input text is as clean as possible.