Clinical NLP extracts meaning from unstructured text. But in healthcare, extracted meaning isn't useful until it speaks the same language as the systems that need to act on it. An...
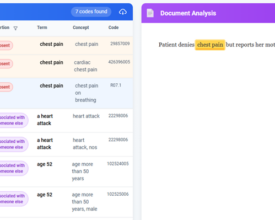
How the John Snow Labs Terminology Server converts unstructured clinical narratives into standardized, machine-ready medical codes, bridging the gap between narrative medicine and healthcare analytics. Every day, hospitals and health...
John Snow Labs, a healthcare AI company, is proud to announce that it has been named the winner of the Real World Evidence (RWE) Catalyst Challenge at PHUSE US Connect...
Why agentic AI marks a new era for healthcare data operations Healthcare organizations generate extraordinary volumes of data every day. Electronic health records, laboratory systems, imaging platforms, registries, clinical trial...


































































 See More
See More