A new generation of the NLP Lab is now available: the Generative AI Lab. Check details here https://www.johnsnowlabs.com/nlp-lab/
Annotation Lab 3.5.0 adds support for out-of-the-box usage of Multilingual Models as well as support for some of the European Language Models: Romanian, Portuguese, Danish and Italian. It also provides support for split dataset using Test/Train tags in classification project and allows NER pretrained models evaluation with floating license. The release also includes fixes for known security vulnerabilities and for some bugs reported by our user community.
Here are the highlights of this release:
Support for Multilingual Models
In this release, some improvements were added to the Models Hub page to include multilingual models. Previously, only multilingual embeddings were available on the Hub page of NLP Models. A new language filter has been added to the Models hub page to make searching for all available multilingual models and embeddings more efficient. User can select the target language and then explore the set of relevant multilingual models and embeddings. When a relevant model is discovered and downloaded to Annotation Lab, the suffix xx will be added to the model’s name.

Expended Support for European Language Models
Annotation Lab now offers support for four new European languages Romanian, Portuguese, Italian, and Danish, on top of English, Spanish, and German, already supported in previous versions. Many pretrained models in those languages are now available to download from the NLP Models Hub and easily use to preannotate documents on the Annotation Lab. Users can also upload models in those languages to the Annotation Lab and use them for preannotation in new projects or tune them to better suite their data.

Use Test/Train Tags for Classification Training Experiments
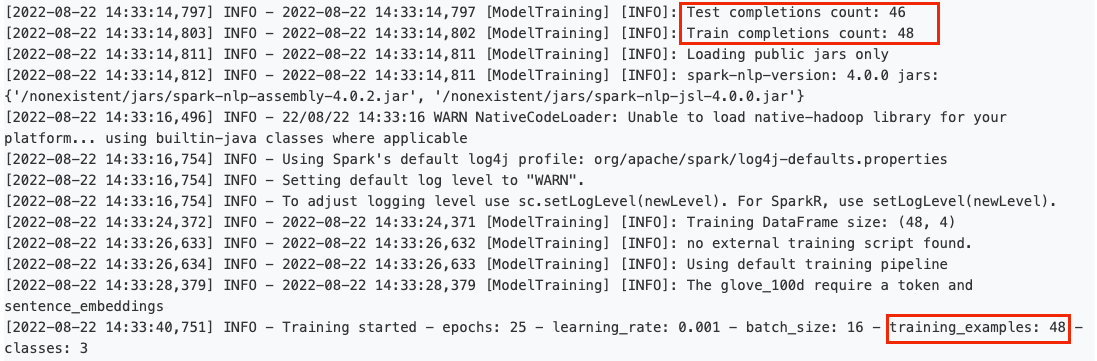
With version 3.5.0, the Test/Train split of annotated tasks can be used when training classification models. When this option is checked on the Training Settings, all tasks that have the Test tag are used as test datasets. All tasks tagged as Train together with all other non Test tasks will be used as a training dataset. For instance, when “Split dataset using Test/Train tags” is enabled, on a project with a total of 94 tasks, out of which 46 tasks have the Test tag, the 48 tasks that do not have the Test tag will be used as train tasks while the 46 Test tasks will be used for testing the model’s performance.
NER Model Evaluation available for Floating License
Starting with version 3.5.0, Project Owner and/or Manager can evaluate pretrained NER models against a set of annotated tasks in the presence of floating licenses. Earlier, this feature was only available in the presence of airgap licenses. The NER models included in the current project configuration are tested against the tasks tagged as Test. The performance metrics can be checked and downloaded as evaluation logs.
Chunks preannotation in VisualNER
Annotation Lab 3.4.0 which first published the visual NER preannotation and visual NER model training could only create token level preannotations. With version 3.5.0, individual tokens are combined into one chunk entity and shown as merged to the user.

Benchmarking Information for Models Trained with Annotation Lab
Earlier versions of Annotation Lab provided benchmarking information for models published by John Snow Labs on the NLP Models Hub. With version 3.5.0 benchmarking information is available for models trained within Annotation Lab. User can go to the Available Models Tab of the Models Hub page and view the benchmarking data by clicking the small graph icon next to the model.

Configuration for Annotation Lab Deployment
The resources allocated to Annotation Lab deployment can be configured via the resource values in the annotationlab-updater.sh. Users can follow the steps below to change the default resource allocation:
- Go to the end of annotationlab-updater.sh file
- Set the CPU and memory for both limits and requests as per the requirement
Example:
--set resources.limits.cpu="8000m"\
--set resources.limits.memory="8000Mi" \
--set resources.requests.cpu="4000m" \
--set resources.requests.memory="4000Mi" \
NOTE:The resource allocation needs to be defined according to the type of instance used for the deployment.
Security fixes
As part of our release process we run CVE scans and upgrade the python packages to latest versions in order to eliminate known vulnerabilities. A high number of Common Vulnerabilities and Exposures(CVE) issues are fixed in this version.