


























































It’s a well-established principle: any LLM, whether open-source or proprietary, isn’t dependable without a RAG. And truly, there can’t be an effective RAG without an NLP library that is production-ready, natively distributed, state-of-the-art, and user-friendly. This holds true in our 5.1 release!
We’re excited to unveil Spark NLP 🚀 5.1 with:
- New OpenAI Whisper, Embeddings and Completions!
- Extended ONNX support for highly-rated E5 embeddings. Anticipate swifter inferences, seamless optimizations, and quantization for exporting LLM models.
- MPNet, a cherished sentence-embedding LLM boasting 140+ ready-to-use models!
- Cutting-edge BGE and GTE text embedding models lead the MTEB leaderboard, surpassing even the renowned OpenAI text-embedding-ada-002. We employ these models for text vectorization, pairing them with LLM models to ensure accuracy and prevent misinterpretations.
- Unified Support for All Major Cloud Storage (Azure, GCP, and S3)
- BART multi-lingual Zero-Shot multi-class/multi-label text classification
- and more!
We want to thank our community for their valuable feedback, feature requests, and contributions. Our Models Hub now contains over 18,000+ free and truly open-source models & pipelines. 🎉
New Features
Spark NLP ❤️ ONNX (toujours)
In Spark NLP 5.1.0, we’re persisting with our commitment to ONNX Runtime support. Following our introduction of ONNX Runtime in Spark NLP 5.0.0—which has notably augmented the performance of models like BERT—we’re further integrating features to bolster model efficiency. Our endeavors include optimizing existing models and expanding our ONNX-compatible offerings. For a detailed overview of ONNX compatibility in Spark NLP, refer to this issue.
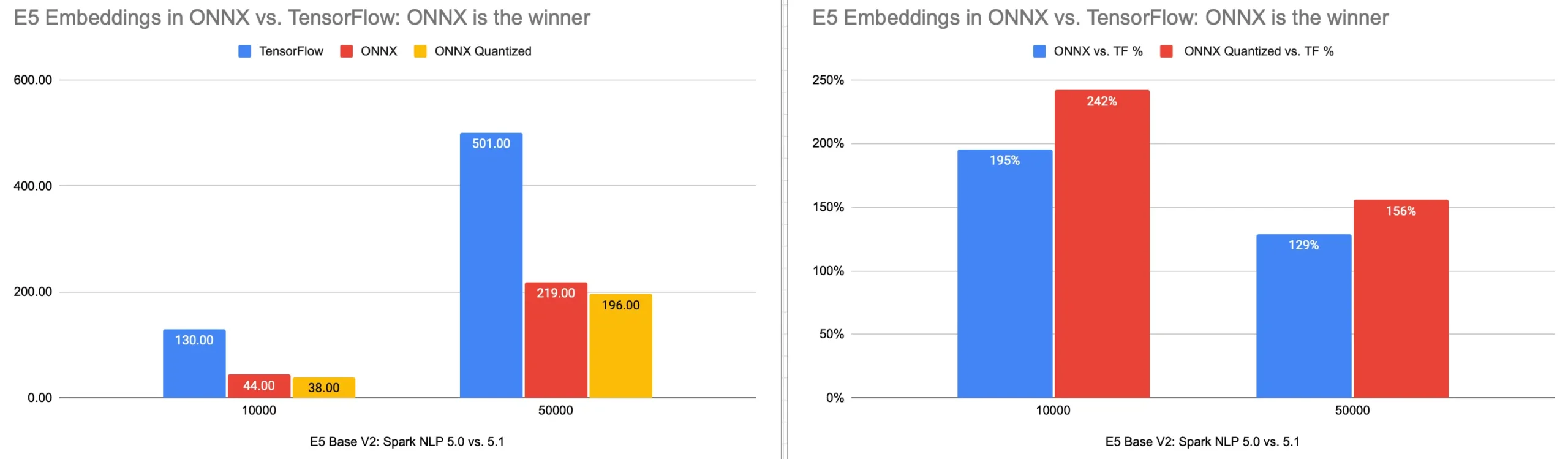
NEW: In the 5.1.0 release, we’ve extended ONNX support to the E5 embedding annotator and introduced 15 new E5 models in ONNX format. This includes both optimized and quantized versions. Impressively, the enhanced ONNX support and these new models showcase a performance boost ranging from 2.3x to 3.4x when compared to the TensorFlow versions released in the 5.0.0 update.
OpenAI Whisper: Robust Speech Recognition via Large-Scale Weak Supervision
NEW: Introducing WhisperForCTC annotator in Spark NLP 🚀. WhisperForCTC can load all state-of-the-art Whisper models inherited from OpenAI Whisperfor Robust Speech Recognition. Whisper was trained and open-sourced that approaches human level robustness and accuracy on English speech recognition.
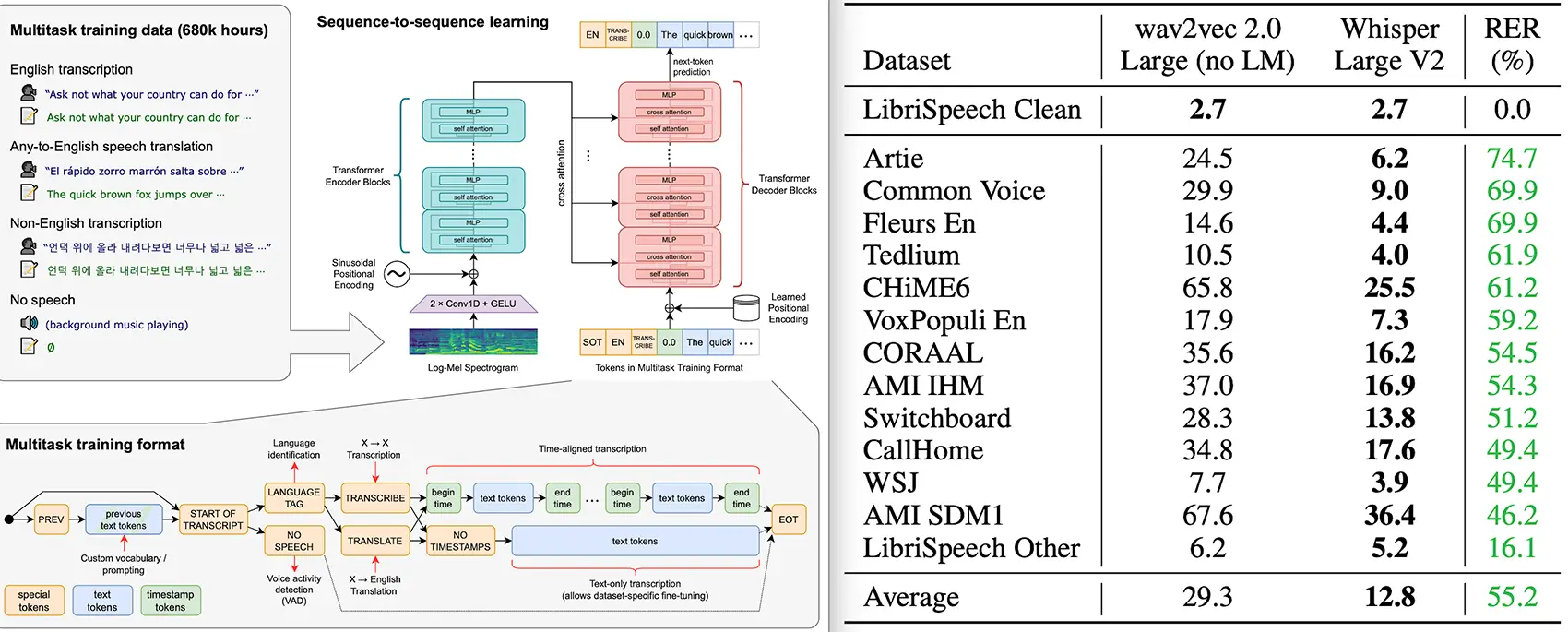
We study the capabilities of speech processing systems trained simply to predict large amounts of transcripts of audio on the internet. When scaled to 680,000 hours of multilingual and multitask supervision, the resulting models generalize well to standard benchmarks and are often competitive with prior fully supervised results but in a zeroshot transfer setting without the need for any finetuning. When compared to humans, the models approach their accuracy and robustness. We are releasing models and inference code to serve as a foundation for further work on robust speech processing.
For more details, check out the official paper
audio_assembler = AudioAssembler() \
.setInputCol("audio_content") \
.setOutputCol("audio_assembler")
speech_to_text = WhisperForCTC \
.pretrained()\
.setInputCols("audio_assembler") \
.setOutputCol("text")
pipeline = Pipeline(stages=[
audio_assembler,
speech_to_text,
])
MPNet: Masked and Permuted Pre-training for Language Understanding
NEW: Introducing MPNetEmbeddings annotator in Spark NLP 🚀. MPNetEmbeddings can load all state-of-the-art MPNet Models for Text Embeddings.
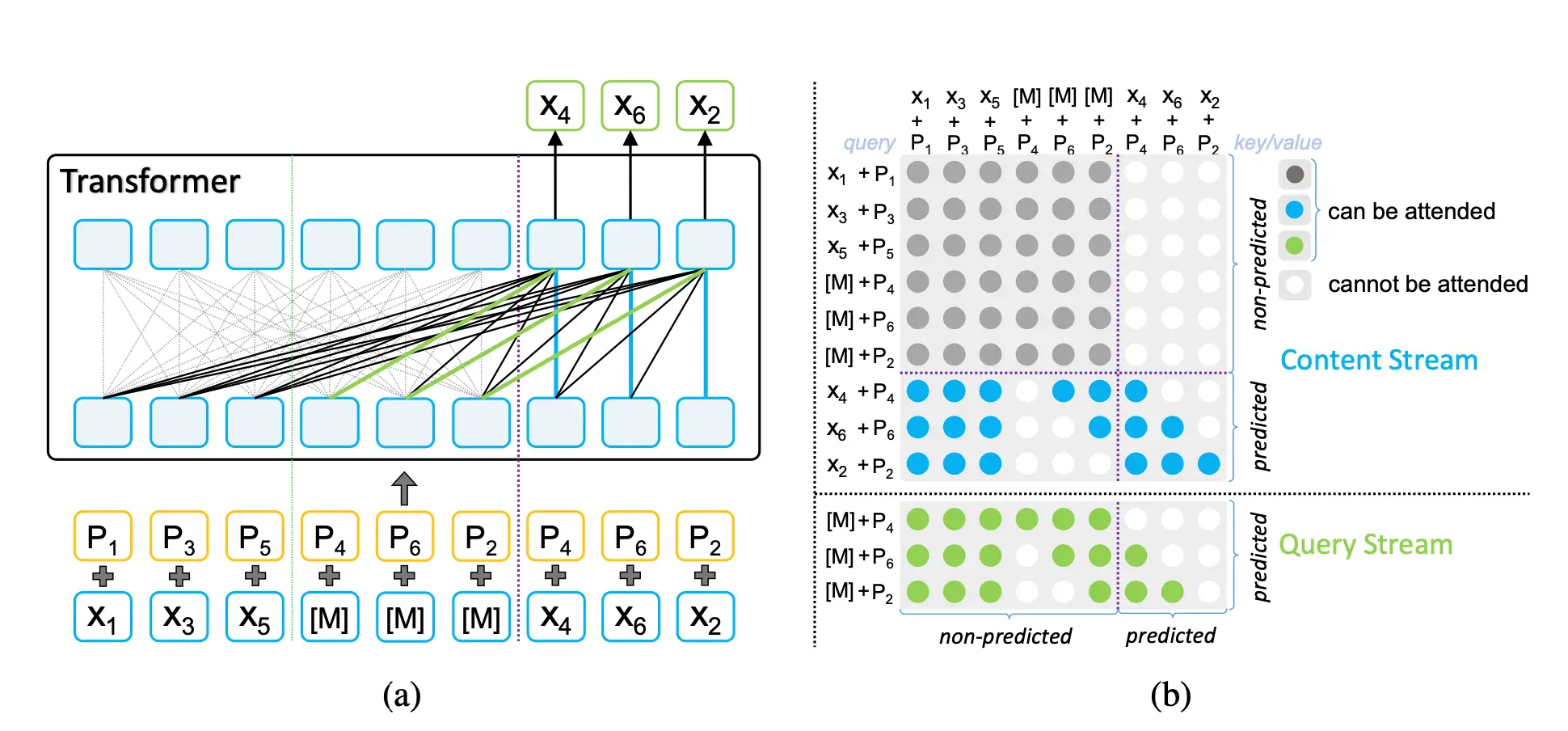
We propose MPNet, a novel pre-training method that inherits the advantages of BERT and XLNet and avoids their limitations. MPNet leverages the dependency among predicted tokens through permuted language modeling (vs. MLM in BERT), and takes auxiliary position information as input to make the model see a full sentence and thus reducing the position discrepancy (vs. PLM in XLNet). We pre-train MPNet on a large-scale dataset (over 160GB text corpora) and fine-tune on a variety of down-streaming tasks (GLUE, SQuAD, etc). Experimental results show that MPNet outperforms MLM and PLM by a large margin, and achieves better results on these tasks compared with previous state-of-the-art pre-trained methods (e.g., BERT, XLNet, RoBERTa) under the same model setting.
MPNet: Masked and Permuted Pre-training for Language Understanding by
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu
Available new state-of-the-art BGE, TGE, E5, and INSTRUCTOR models for Text Embeddings are currently dominating the top of the MTEB leaderboard positioning themselves way above OpenAI text-embedding-ada-002
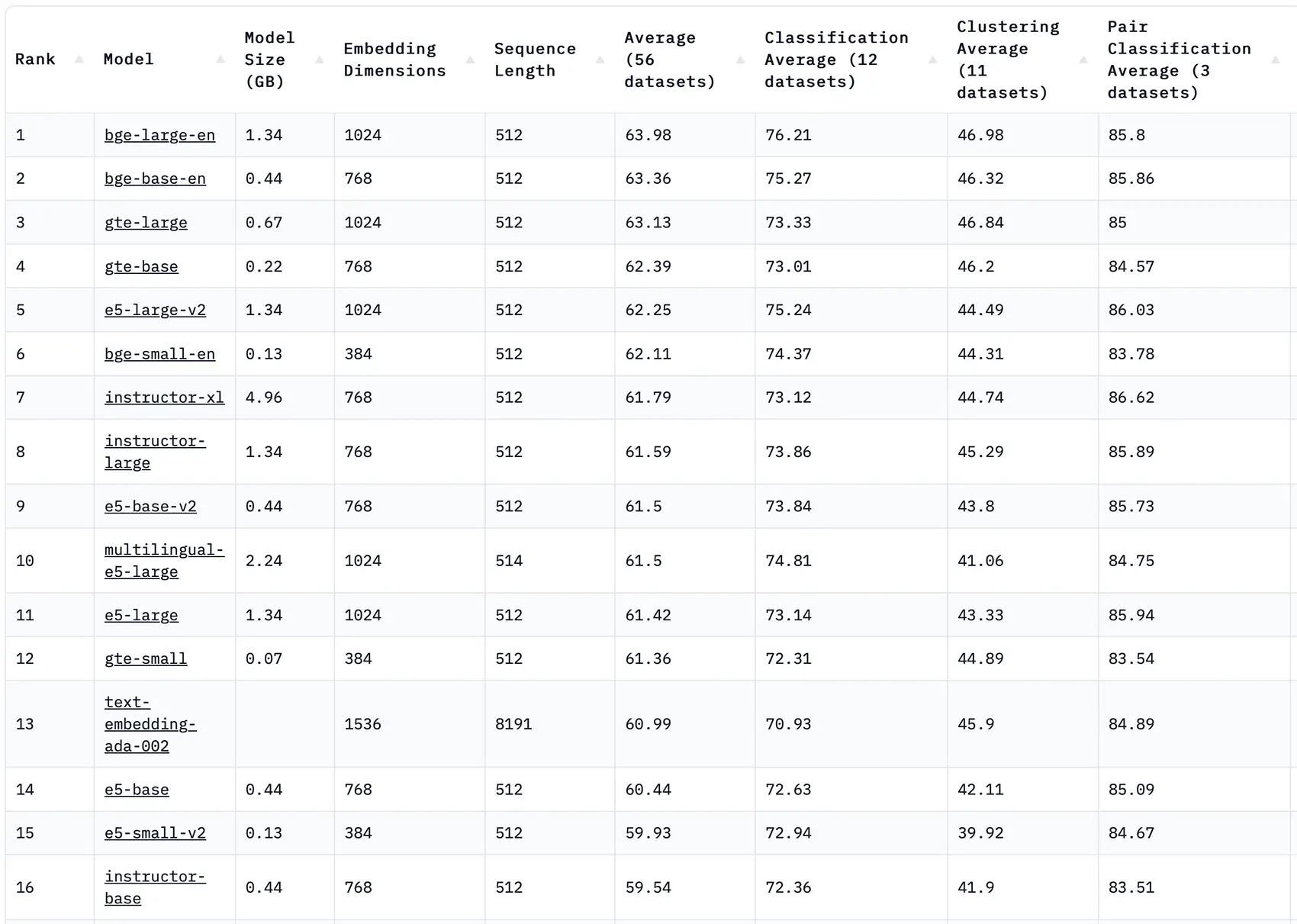
Massive Text Embedding Benchmark (MTEB) Leaderboard. To submit, refer to the MTEB GitHub repository 🤗
New OpenAI Embeddings and Completions
NEW: In Spark NLP 5.1.0, we’re thrilled to introduce the integration of OpenAI Embeddings and Completions transformers. By merging the prowess of OpenAI’s language model with the robust NLP processing capabilities of Spark NLP, we’ve created a powerful synergy. Specifically, with the newly introduced OpenAIEmbeddings and OpenAICompletion transformers, users can now make direct API calls to OpenAI’s Embeddings and Completion endpoints right from an Apache Spark DataFrame. This enhancement promises to elevate the efficiency and versatility of data processing workflows within Spark NLP pipelines.
# to use OpenAI completions endpoint
document_assembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
openai_completion = OpenAICompletion() \
.setInputCols("document") \
.setOutputCol("completion") \
.setModel("text-davinci-003") \
.setMaxTokens(50)
# to use OpenAI embeddings endpoint
document_assembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
openai_embeddings = OpenAIEmbeddings() \
.setInputCols("document") \
.setOutputCol("embeddings") \
.setModel("text-embedding-ada-002")
# Define the pipeline
pipeline = Pipeline(stages=[
document_assembler, openai_embeddings
])
Unified Support for All Major Cloud Storage
In Spark NLP 5.1.0, we’re thrilled to announce a holistic integration of all major cloud and distributed file storage systems. Building on our existing support for AWS, DBFS, and HDFS, we’ve now introduced seamless operations with Google Cloud Platform (GCP) and Azure. Here’s a brief overview of what’s been added and improved:
- Comprehensive Integration: We’ve successfully unified all externally supported file systems and cloud access, ensuring a consistent experience across platforms.
- Enhanced Cloud Access: Undergoing refactoring, the cache_pretrained property now offers unified cloud access, making it easier to cache models from any supported platform.
- New Azure Storage Support: We’ve integrated Azure dependencies, allowing for Azure support in all cloud operations, ensuring users of Microsoft’s cloud platform have a first-class experience.
- New GCP Storage support: Users can now effortlessly export NER log files directly to GCP Storage. Additionally, importing HF models from GCP has been made straightforward.
- Refinements and Fixes: We’ve relocated the Credentials component to the AWS package for better organization and addressed issues related to HDFS log and NER Graph loading.
- Documentation: To help users get started and transition smoothly, comprehensive documentation has been added detailing the support for Azure, GCP, and S3 operations.
We’re confident these updates will provide a smoother, more unified experience for users across all cloud platforms for the following features:
- Define a custom path for
cache_pretraineddirectory - Store logs during training
- Load TF graphs for NerDL annotator
- Importing any HF model into Spark NLP
BART: New multi-lingual Zero-Shot Text Classification
- NEW: Introducing BartForZeroShotClassification annotator for Zero-Shot Text Classification in Spark NLP 🚀. You can use the
BartForZeroShotClassificationannotator for text classification with your labels!
Zero-Shot Learning (ZSL): Traditionally, ZSL most often referred to a fairly specific type of task: learning a classifier on one set of labels and then evaluating on a different set of labels that the classifier has never seen before. Recently, especially in NLP, it’s been used much more broadly to get a model to do something it wasn’t explicitly trained to do. A well-known example of this is in the GPT-2 paper where the authors evaluate a language model on downstream tasks like machine translation without fine-tuning on these tasks directly.
Let’s see how easy it is to just use any set of labels our trained model has never seen via the setCandidateLabels() param:
zero_shot_classifier = BartForZeroShotClassification \
.pretrained() \
.setInputCols(["document", "token"]) \
.setOutputCol("class") \
.setCandidateLabels(["urgent", "mobile", "travel", "movie", "music", "sport", "weather", "technology"])
For Zero-Short Multi-class Text Classification:
+----------------------------------------------------------------------------------------------------------------+--------+
|result |result |
+----------------------------------------------------------------------------------------------------------------+--------+
|[I have a problem with my iPhone that needs to be resolved asap!!] |[mobile]|
|[Last week I upgraded my iOS version and ever since then my phone has been overheating whenever I use your app.]|[mobile]|
|[I have a phone and I love it!] |[mobile]|
|[I want to visit Germany and I am planning to go there next year.] |[travel]|
|[Let's watch some movies tonight! I am in the mood for a horror movie.] |[movie] |
|[Have you watched the match yesterday? It was a great game!] |[sport] |
|[We need to hurry up and get to the airport. We are going to miss our flight!] |[urgent]|
+----------------------------------------------------------------------------------------------------------------+--------+
For Zero-Short Multi-class Text Classification:
+----------------------------------------------------------------------------------------------------------------+-----------------------------------+
|result |result |
+----------------------------------------------------------------------------------------------------------------+-----------------------------------+
|[I have a problem with my iPhone that needs to be resolved asap!!] |[urgent, mobile, movie, technology]|
|[Last week I upgraded my iOS version and ever since then my phone has been overheating whenever I use your app.]|[urgent, technology] |
|[I have a phone and I love it!] |[mobile] |
|[I want to visit Germany and I am planning to go there next year.] |[travel] |
|[Let's watch some movies tonight! I am in the mood for a horror movie.] |[movie] |
|[Have you watched the match yesterday? It was a great game!] |[sport] |
|[We need to hurry up and get to the airport. We are going to miss our flight!] |[urgent, travel] |
+----------------------------------------------------------------------------------------------------------------+-----------------------------------+
- NEW: New BAAI general embedding (BGE) and General Text Embeddings (GTE) Models
Models
Spark NLP 5.1.0 comes with more than 200+ new state-of-the-art pre-trained transformer models in multi-languages.
Featured Models
| Model | Name | Lang |
|---|---|---|
| WhisperForCTC | asr_whisper_tiny | xx |
| WhisperForCTC | asr_whisper_tiny_opt | xx |
| BertEmbeddings | bge_small | en |
| BertEmbeddings | bge_base | en |
| BertEmbeddings | bge_large | en |
| BertEmbeddings | gte_small | en |
| BertEmbeddings | gte_base | en |
| BertEmbeddings | gte_large | en |
The complete list of all 18400+ models & pipelines in 230+ languages is available on Models Hub
New Notebooks
- Whisper: Automatic Speech Recognition in Spark NLP
- Import Whisper models (ONNX)
- Import Whisper models (TF)
- OpenAICompletion Example
- OpenAIEmbeddings Example
- Import Transformers from 🤗 into Spark NLP 🚀 with GCP
- Import Transformers from 🤗 into Spark NLP 🚀 with Azure
- Import Transformers from 🤗 into Spark NLP 🚀 with AWS
You can visit Import Transformers in Spark NLP
You can visit Spark NLP Examples for 100+ examples
Documentation
- Import models from TF Hub & HuggingFace
- Spark NLP Notebooks
- Models Hub with new models
- Spark NLP Articles
- Spark NLP in Action
- Spark NLP Documentation
- Spark NLP Scala APIs
- Spark NLP Python APIs
Community support
- Slack For live discussion with the Spark NLP community and the team
- GitHub Bug reports, feature requests, and contributions
- Discussions Engage with other community members, share ideas,
and show off how you use Spark NLP! - Medium Spark NLP articles
- JohnSnowLabs official Medium
- YouTube Spark NLP video tutorials
Installation
Python
#PyPI
pip install spark-nlp==5.1.0
Spark Packages
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, and 3.4.x (Scala 2.12):
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.1.0
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.1.0
GPU
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.1.0
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.1.0
Apple Silicon (M1 & M2)
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.1.0
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.1.0
AArch64
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.1.0
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.1.0
Maven
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, and 3.4.x:
dependency
groupId com.johnsnowlabs.nlp /groupId
artifactId spark-nlp_2.12 /artifactId
version 5.1.0 /version
/dependency
spark-nlp-gpu:
dependency
groupId com.johnsnowlabs.nlp /groupId
artifactId spark-nlp-gpu_2.12 /artifactId
version 5.1.0 /version
/dependency
spark-nlp-silicon:
dependency
groupId com.johnsnowlabs.nlp /groupId
artifactId spark-nlp-silicon_2.12 /artifactId
version 5.1.0 /version
/dependency
spark-nlp-aarch64:
dependency
groupId com.johnsnowlabs.nlp /groupId
artifactId spark-nlp-aarch64_2.12 /artifactId
version 5.1.0 /version
/dependency
FAT JARs
- CPU on Apache Spark 3.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-assembly-5.1.0.jar
- GPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-gpu-assembly-5.1.0.jar
- M1 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-silicon-assembly-5.1.0.jar
- AArch64 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-aarch64-assembly-5.1.0.jar




