

























































A Powerful Tool for Sentiment Analysis

Sentiment analysis, also known as opinion mining, is a computational approach that aims to identify and extract subjective information from text data. This technique has gained significant attention in recent years due to its applications in various fields, including marketing, customer service, political analysis, and social media monitoring.
Sentiment analysis is a computational technique that aims to extract subjective information from textual data. It has widespread applications in various fields, including marketing, customer service, political analysis, and social media monitoring.
One of the notable approaches to sentiment analysis is the Vivek approach (sentiment analyzer inspired by the algorithm by Vivek Narayanan) used by Spark NLP, which is based on the use of lexicons or dictionaries that contain words and phrases associated with positive or negative sentiment. The Vivek approach has shown promising results in various studies and has been used in several applications, including sentiment analysis of social media data, movie reviews, and product reviews. It is a simple and effective approach that can be easily implemented using open-source tools and libraries.
In this post, you will learn how to use ViveknSentiment annotator of Spark NLP to perform sentiment analysis using a pretrained model and also learn how to easily train your own models for the same purpose.
Spark NLP has multiple approaches for detecting the sentiment (which is actually a text classification problem) in a text. There are separate blog posts for the rule-based sentiment analysis and a deep learning approach to sentiment analysis.
Let us start with a short Spark NLP introduction and then discuss the details of the Vivek sentiment analysis technique with some solid results.
What is Spark NLP Technology
Spark NLP refers to open-source NLP libraries. It was created by John Snow Labs (1st released in July 2017). It works on Spark ML and Apache Spark base. This AI technology offers simple, efficient & highly accurate NLP annotations for ML pipelines with the capability to easily scale in a distributed environment.
Since 2017, Spark NLP has grown into a full-scale natural language processing solution. Currently, it provides a unified tool for all NLP-tasks, TL technique and implementation of the newest and the most significant State-Of-The-Art models and algorithms in NLP research, the most popular NLP library in the industry, and the fastest NLP library ever.
Spark NLP comes with 17,800+ pretrained pipelines and models in more than 250+ languages. It serves a wide range of clients’ NLP needs and provides modules that can be integrated seamlessly into a cluster.
Spark NLP processes the data using Pipelines, structure that contains all the steps to be run on the input data:
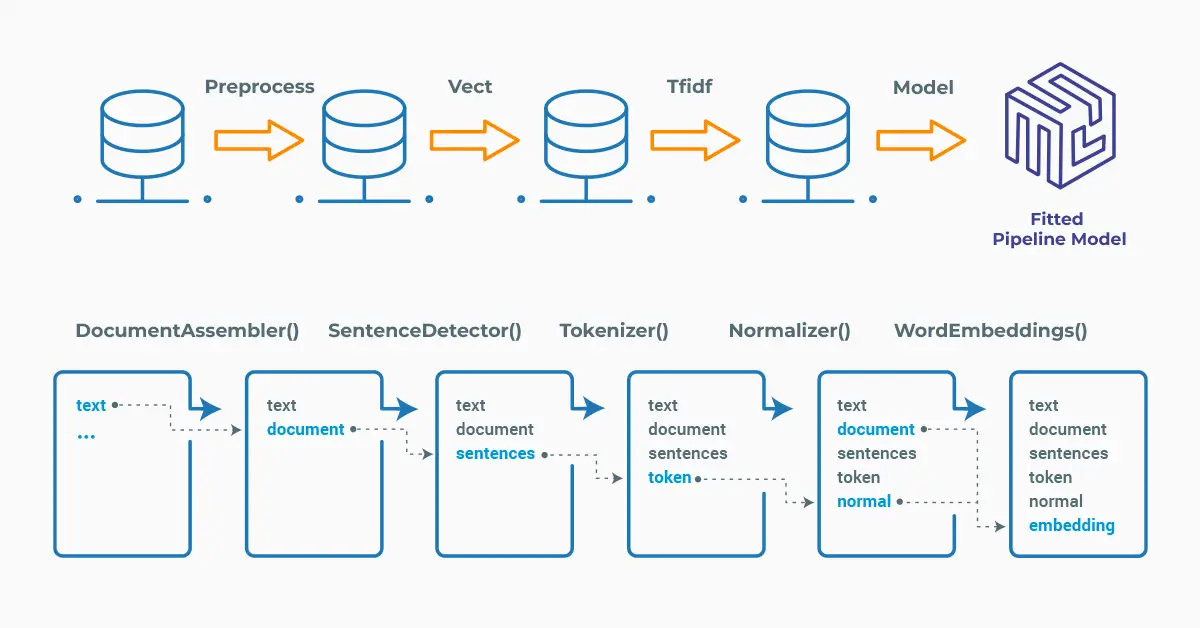
Spark NLP pipelines
Each step contains an annotator that performs a specific task such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
An annotator in Spark NLP is a component that performs a specific NLP task on a text document and adds annotations to it. An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. For example, a named entity recognizer annotator might identify and tag entities such as people, organizations, and locations in a text document, while a sentiment analysis annotator might classify the sentiment of the text as positive, negative, or neutral.
Setup
If you want to install this NLP library in Python, use the package manager you prefer (conda, pip, or other one). For example:
pip install spark-nlp pip install pyspark
Here you can find official documentation with installation details for all other machines and environments.
Then, simply import the library and start a Spark session:
import sparknlp # Start Spark Session spark = sparknlp.start()
Enhanced Naive Bayes Model Approach — ViveknSentiment
ViveknSentiment uses Naive-Bayes classifier for sentiment analysis. In statistics, Naive-Bayes classifiers are a family of simple “probabilistic classifiers” based on applying Bayes’ theorem with strong independence assumptions between the features.
Bayes theorem provides a way of calculating the posterior probability, P(c|x), from P(c), P(x), and P(x|c). Naive Bayes classifier assume that the effect of the value of a predictor x on a given class c is independent of the values of other predictors. This assumption is called class conditional independence.
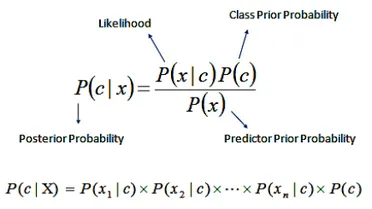
Please check the academic paper named ‘Fast and accurate sentiment classification using an enhanced Naive Bayes model’, to understand the theory behind finding the maximum likelihood probability of a word belonging to a particular class.
ViveknSentimentApproach annotator is used for training models and ViveknSentimentModelannotator is used for getting predictions from the trained model.
First, we will use a pretrained ViveknSentiment model from John Snow Labs Model’s Hub in order to predict the sentiment in a text. Then, by using just 6 labelled sentences, we will train a model and get predictions by using this model.
Use a Model from John Snow Labs Model’s Hub
The ViveknSentiment annotator expects DOCUMENT and TOKEN as input, and then will provide SENTIMENT as output. Thus, we need the previous steps to generate those annotations that will be used as input to our annotator.
Please notice that Normalizer is added to the pipeline as the third stage and the target was to clean out the tokens before feeding them to the sentiment detection stage.
Please check the details of the pipeline below:
# Import the required modules and classes
from sparknlp.base import DocumentAssembler, Pipeline, Finisher
from sparknlp.annotator import (
Tokenizer,
Normalizer,
ViveknSentimentModel
)
import pyspark.sql.functions as F
# Step 1: Transforms raw texts to `document` annotation
document_assembler = (
DocumentAssembler()
.setInputCol("text")
.setOutputCol("document")
)
# Step 2: Tokenization
tokenizer = Tokenizer().setInputCols(["document"]).setOutputCol("token")
# Step 3: Normalizer
normalizer= Normalizer().setInputCols("token").setOutputCol("normal")
# Step 4: Sentiment Detection
vivekn= (
ViveknSentimentModel.pretrained('sentiment_vivekn')
.setInputCols(["document", "normal"])
.setOutputCol("result_sentiment")
.setFeatureLimit(4)
)
# Step 5: Finisher
finisher= (
Finisher()
.setInputCols(["result_sentiment"]).setOutputCols("final_sentiment")
)
# Define the pipeline
pipeline = Pipeline(
stages=[
document_assembler,
tokenizer,
normalizer,
vivekn,
finisher
]
)
We will use a dataframe (data) with two sample sentences and get sentiment predictions for them.
# Define dataframe with sample texts
data = spark.createDataFrame([
["I recommend this movie"],
["Dont waste your time!!!"]
]).toDF("text")
model = pipeline.fit(data)
result = model.transform(data)
# Display both the sample text and the predicted sentiment
result.select("text", "final_sentiment").show(truncate=False)
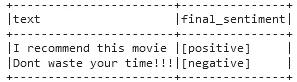
Sentiment predictions for both sentences
Using LightPipeline
LightPipeline is a Spark NLP specific Pipeline class equivalent to Spark ML Pipeline. The difference is that its execution does not hold to Spark principles, instead it computes everything locally (but in parallel) in order to achieve fast results when dealing with small amounts of data. This means, we do not input a Spark Dataframe, but a string or an array of strings instead, to be annotated.
We can show the results in a Pandas DataFrame by running the following code:
import pandas as pd
text = "This is a terrible movie"
light_model = LightPipeline(model)
light_result = light_model.fullAnnotate(text)
results_tabular = []
for res in light_result[0]["result_sentiment"]:
results_tabular.append(
(
text,
res.result
))
pd.DataFrame(results_tabular, columns=['text', "final_sentiment"])

The dataframe shows the predicted sentiments of the text
One-liner alternative
In October 2022, John Snow Labs released the open-source johnsnowlabs library that contains all the company products, open-source and licensed, under one common library. This simplified the workflow especially for users working with more than one of the libraries (e.g., Spark NLP + Healthcare NLP). This new library is a wrapper on all John Snow Lab’s libraries, and can be installed with pip:
pip install johnsnowlabs
Please check the official documentation for more examples and usage of this library. To run sentiment analysis with one line of code, we can simply:
# Import the NLP module which contains Spark NLP and NLU libraries
from johnsnowlabs import nlp
nlp.load("en.sentiment.vivekn").predict("""This is a terrible movie!""")
After using the one-liner model, the result shows that the sentiment of the text is Negative
The one-liner is based on default models for each NLP task. Depending on your requirements, you may want to use the one-liner for simplicity or customizing the pipeline to choose specific models that fit your needs.
NOTE: when using only the johnsnowlabs library, make sure you initialize the spark session with the configuration you have available. Since some of the libraries are licensed, you may need to set the path to your license file. If you are only using the open-source library, you can start the session with spark = nlp.start(nlp=False). The default parameters for the start function includes using the licensed Healthcare NLP library with nlp=True, but we can set that to False and use all the resources of the open-source libraries such as Spark NLP, Spark NLP Display, and NLU.
Train a Model by ViveknSentimentApproach
In order to show the capacity of the ViveknSentimentApproach annotator in model training, let us train a model with just 6 labelled sentences and then use this trained model to get predictions.
The pipeline below is quite similar to the one that we used for ViveknSentimentModel:
# Import the required modules and classes
from sparknlp.annotator import (
ViveknSentimentApproach
)
document_assembler = (
DocumentAssembler()
.setInputCol("text")
.setOutputCol("document")
)
tokenizer = Tokenizer().setInputCols(["document"]).setOutputCol("token")
normalizer= Normalizer().setInputCols("token").setOutputCol("normal")
vivekn= (
ViveknSentimentApproach()
.setInputCols(["document", "normal"])
.setOutputCol("result_sentiment")
.setSentimentCol("train_sentiment")
)
finisher= (
Finisher()
.setInputCols(["result_sentiment"]).setOutputCol("final_sentiment")
)
pipeline = Pipeline(
stages=[
document_assembler,
tokenizer,
normalizer,
vivekn,
finisher
]
)
We will use the labelled sentences below for model training:
training = spark.createDataFrame([
("I really liked this movie!", "positive"),
("The cast was horrible", "negative"),
("Never going to watch this again or recommend it to anyone", "negative"),
("It's a waste of time", "negative"),
("I loved the protagonist", "positive"),
("The music was really really good", "positive")
]).toDF("text", "train_sentiment")
Now, we fit the training dataset and then using this model, get sentiment predictions for the simple sentences below:
pipelineModel = pipeline.fit(training)
data = spark.createDataFrame([
["I recommend this movie"],
["Dont waste your time!!!"]
]).toDF("text")
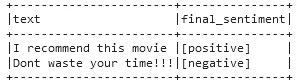
result = pipelineModel.transform(data)
result.select("text", "final_sentiment").show(truncate=False)
For additional information, please check the following references.
- Documentation : ViveknSentiment
- Python Docs : ViveknSentimentModel, ViveknSentimentApproach
- Scala Docs : ViveknSentimentModel, ViveknSentimentApproach
- Academic Reference Paper: Fast and accurate sentiment classification using an enhanced Naive Bayes model.
- For LightPipelines, check this post.
Conclusion
Sentiment analysis using the ViveknSentiment annotator of Spark NLP provides a powerful and efficient approach for analyzing and extracting sentiment from textual data. The ViveknSentiment annotator is based on the use of lexicons or dictionaries to assign sentiment scores to words and phrases, which are then aggregated to determine the overall sentiment of the text.
Despite its simplicity, the ViveknSentiment annotator of Spark NLP has been shown to perform well in various applications, including social media monitoring, product reviews, and movie reviews. However, like any computational approach, it is not without limitations, such as the need for high-quality lexicons and the difficulty in handling sarcasm and irony.
Also, it can be limited in its ability to generalize to new or unseen text and more training data will provide better results.



