






















































Speed up sate-of-the-art ViT models in Hugging Face 🤗 up to 2300% (25x times faster ) with Databricks, Nvidia, and Spark NLP 🚀
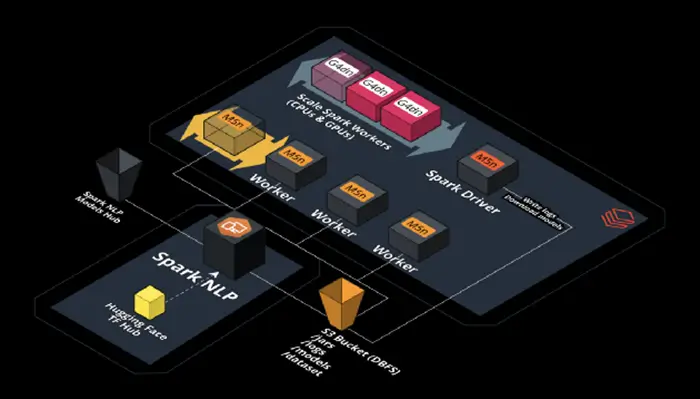
Scaling out transformer-based models by using Databricks, Nvidia, and Spark NLP
Previously on “Scale Vision Transformers (ViT) Beyond Hugging Face | Part 1”:
Bare-meta Dell server: Spark NLP is 65% faster than Hugging Face on CPUs in predicting image classes for the sample dataset with 3K images and 47% on the larger dataset with 34K images. Spark NLP is also 79% faster than Hugging Face on a single GPU inference larger dataset with 34K images and up to 35% faster on a smaller dataset.
The purpose of this article is to demonstrate how to scale out Vision Transformer (ViT) models from Hugging Face and deploy them in production-ready environments for accelerated and high-performance inference. By the end, we will scale a ViT model from Hugging Face by 25x times (2300%) by using Databricks, Nvidia, and Spark NLP.
In Part 2 of this article, I will:
- Benchmark Hugging Face inside Databricks Single Node on CPUs & GPUs
- Benchmark Spark NLP inside Databricks Single Node on CPUs & GPUs
In the spirit of full transparency, all the notebooks with their logs, screenshots, and even the excel sheet with numbers are provided here on GitHub
Spark NLP & Hugging Face on Databricks
What is Databricks? All your data, analytics, and AI on one platform
Databricks is a Cloud-based platform with a set of data engineering & data science tools that are widely used by many companies to process and transform large amounts of data. Users use Databricks for many purposes from processing and transforming extensive amounts of data to running many ML/DL pipelines to explore the data.
Disclaimer: This was my interpretation of Databricks, it does come with lots of other features and you should check them out: https://www.databricks.com/product/data-lakehouse
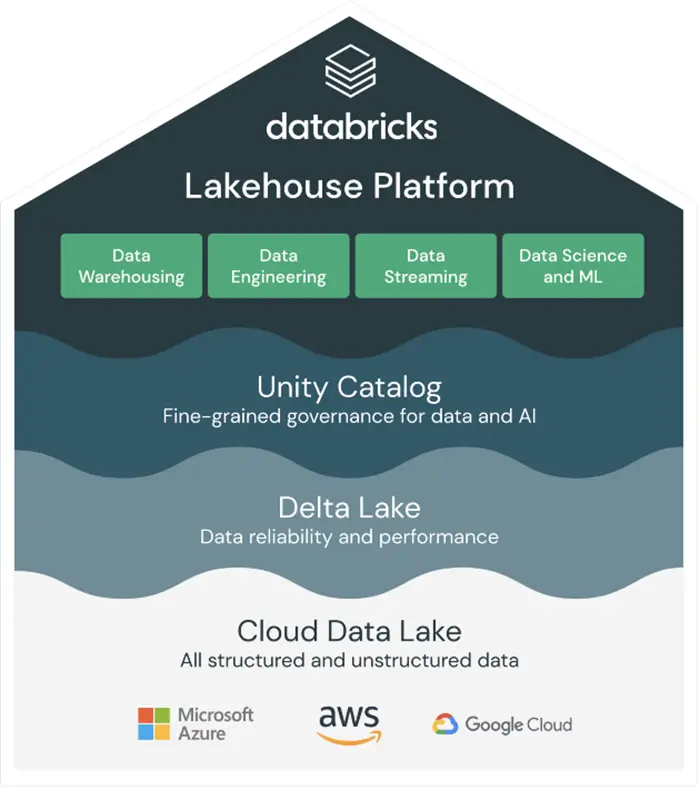
Databricks supports AWS, Azure, and GCP clouds: https://www.databricks.com/product/data-lakehouse
Hugging Face in Databricks Single Node with CPUs on AWS
Databricks offers a “Single Node” cluster type when you are creating a cluster that is suitable for those who want to use Apache Spark with only 1 machine or use non-spark applications, especially ML and DL-based Python libraries. Hugging Face comes already installed when you choose Datanricks 11.1 ML runtime. Here is what the cluster configurations look like for my Single Node Databricks (only CPUs) before we start our benchmarks:
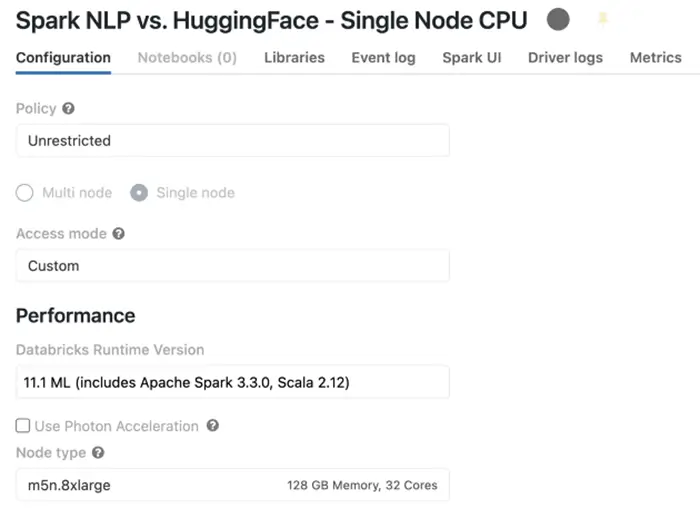
Databricks single-node cluster — CPU runtime
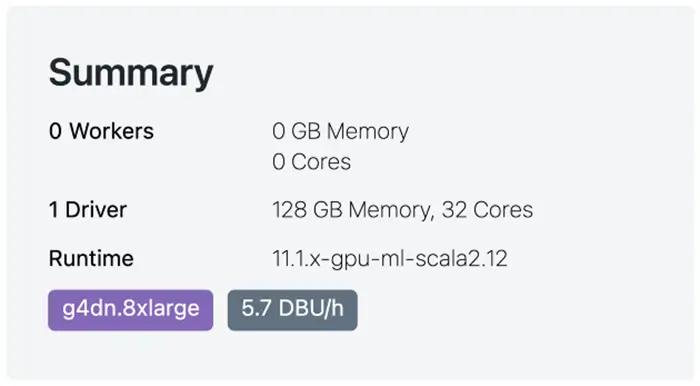
The summary of this cluster that uses m5n.8xlarge instance on AWS is that it has 1 Driver (only 1 node), 128 GB of memory, 32 Cores of CPU, and it costs 5.71 DBU per hour. You can read about “DBU” on AWS here: https://www.databricks.com/product/aws-pricing

Databricks single-cluster — AWS instance profile
Let’s replicate our benchmarks from the previous section (bare-metal Dell server) here on our single-node Databricks (CPUs only). We start with Hugging Face and our sample-sized dataset of ImageNet to find out what batch size is a good one so we can use it for the larger dataset since this happened to be a proven practice in the previous benchmarks:
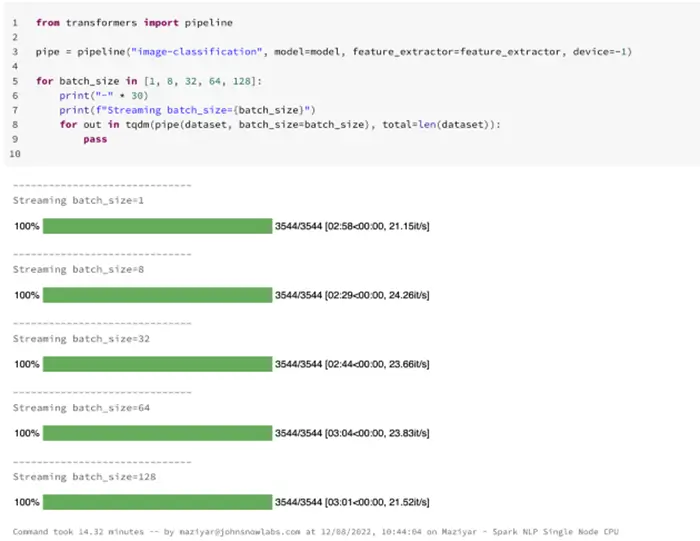
Hugging Face image-classification pipeline on Databricks single-node CPUs — predicting 3544 images
It took around 2 minutes and a half (149 seconds) to finish processing around 3544 images from our sample dataset on a single-node Databricks that only uses CPUs. The best batch size on this machine using only CPUs is 8 so I am gonna use that to run the benchmark on the larger dataset:
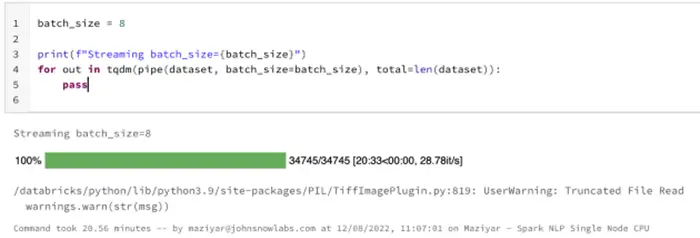
Hugging Face image-classification pipeline on Databricks single-node CPUs — predicting 34745 images
On the larger dataset with over 34K images, it took around 20 minutes and a half (1233 seconds) to finish predicting classes for those images. For our next benchmark we need to have a single-node Databricks cluster, but this time we need to have a GPU-based runtime and choose a GPU-based AWS instance.
Hugging Face in Databricks Single Node with a GPU on AWS
Let’s create a new cluster and this time we are going to choose a runtime with GPU which in this case is called 11.1 ML (includes Apache Spark 3.3.0, GPU, Scala 2.12) and it comes with all required CUDA and NVIDIA software installed. The next thing we need is to also select an AWS instance that has a GPU and I have chosen g4dn.8xlarge that has 1 GPU and a similar number of cores/memory as the other cluster. This GPU instance comes with a Tesla T4 and 16 GB memory (15 GB usable GPU memory).
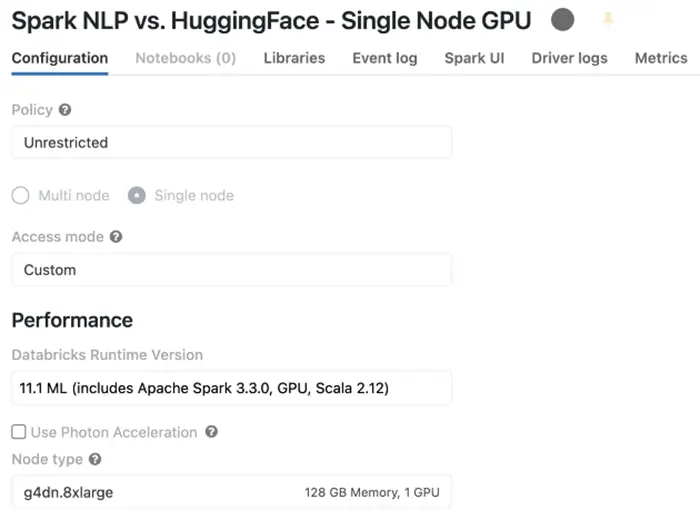
Databricks single-node cluster — GPU runtime
This is the summary of our single-node cluster like the previous one and it is the same in terms of the number of cores and the amount of memory, but it comes with a Tesla T4 GPU:
Databricks single-node cluster — AWS instance profile
Now that we have a single-node cluster with a GPU we can continue our benchmarks to see how Hugging Face performs on this machine in Databricks. I am going to run the benchmark on the smaller dataset to see which batch size is more suited for our GPU-based machine:
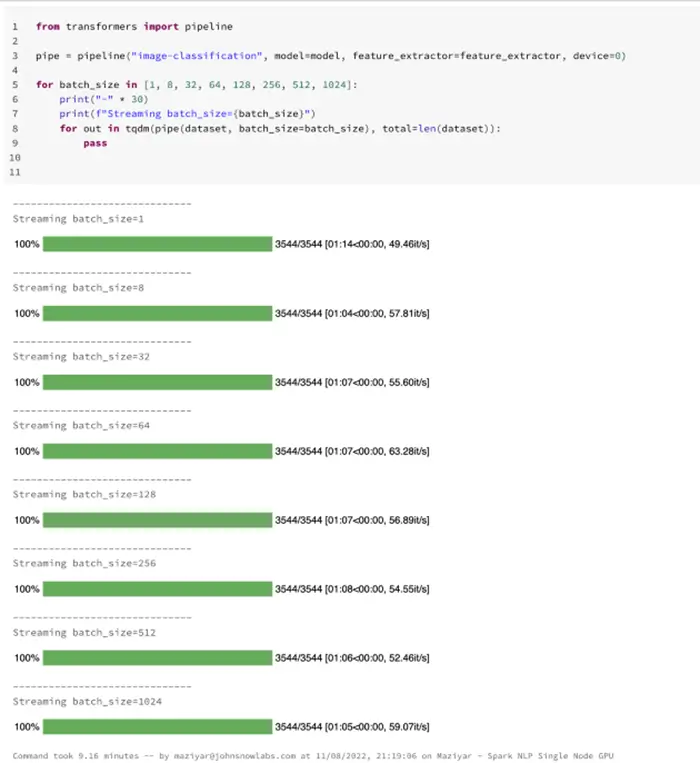
Hugging Face image-classification pipeline on Databricks single-node CPU — predicting 3544 images
It took around a minute (64 seconds) to finish processing around 3544 images from our sample dataset on our single-node Databricks cluster with a GPU device. The batching improved the speed if we look at batch size 1 result, however, after batch size 8 the results pretty much stayed the same. Although the results are the same after batch size 8, I have chosen batch size 256 for my larger benchmark to utilize more GPU memory as well. (to be honest, 8 and 256 both performed pretty much the same)
Let’s run the benchmark on the larger dataset and see what happens with batch size 256:
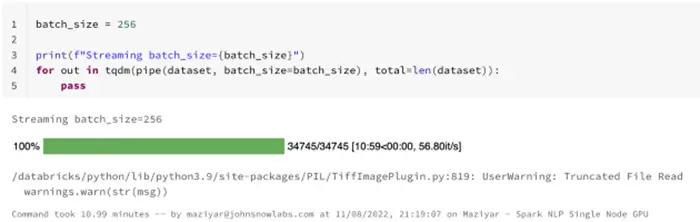
Hugging Face image-classification pipeline on Databricks single-node CPU — predicting 34745 images
On a larger dataset, it took almost 11 minutes (659 seconds) to finish predicting classes for over 34K images. If we compare the results from our benchmarks on a single node with CPUs and a single node that comes with 1 GPU we can see that the GPU node here is the winner:
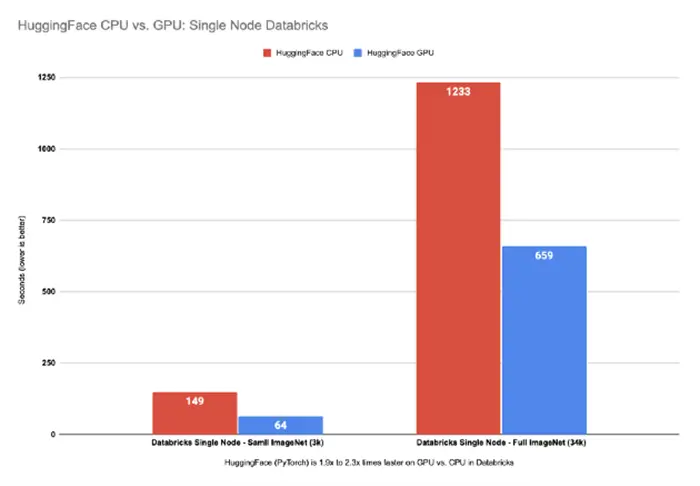
Hugging Face (PyTorch) is up to 2.3x times faster on GPU vs. CPU
The GPU is up to ~2.3x times faster compared to running the same pipeline on CPUs in Hugging Face on Databricks Single Node
Now we are going to run the same benchmarks by using Spark NLP in the same clusters and over the same datasets to compare it with Hugging Face.
Benchmarking Spark NLP on a Single Node Databricks
First, let’s install Spark NLP in your Single Node Databricks CPUs:
- In the Librariestab inside your cluster you need to follow these steps:
— Install New -> PyPI -> spark-nlp==4.1.0 -> Install
— Install New -> Maven -> Coordinates -> johnsnowlabs.nlp:spark-nlp_2.12:4.1.0 -> Install
— Will add `TF_ENABLE_ONEDNN_OPTS=1` to `Cluster->Advacend Options->Spark->Environment variables` to enable oneDNN
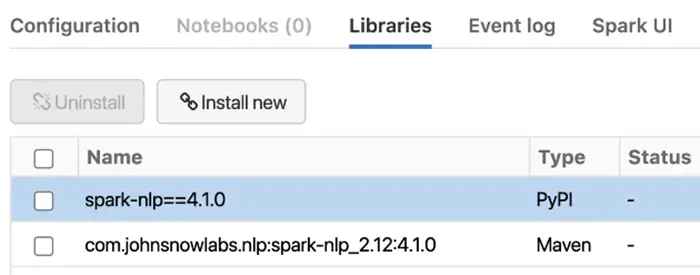
How to install Spark NLP in Databricks on CPUs for Python, Scala, and Java
Spark NLP in Databricks Single Node with CPUs on AWS
Now that we have Spark NLP installed on our Databricks single-node cluster we can repeat the benchmarks for a sample and full datasets on both CPU and GPU. Let’s start with the benchmark on CPUs first over the sample dataset:
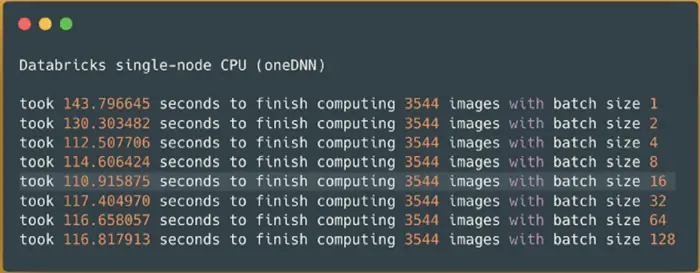
Spark NLP image-classification pipeline on Databricks single-node CPUs (oneDNN) — predicting 3544 images
It took around 2 minutes (111 seconds) to finish processing 3544 images and predicting their classes on the same single-node Databricks cluster with CPUs we used for Hugging Face. We can see that the batch size of 16 has the best result so I will use this in the next benchmark on the larger dataset:
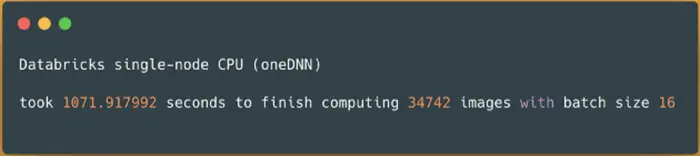
Spark NLP image-classification pipeline on Databricks single-node CPUs (oneDNN) — predicting 34742 images
On the larger dataset with over 34K images, it took around 18 minutes (1072 seconds) to finish predicting classes for those images. Next up, I will repeat the same benchmarks on the cluster with GPU.
Databricks Single Node with a GPU on AWS
First, install Spark NLP in your Single Node Databricks GPU (the only difference is the use of “spark-nlp-gpu” from Maven):
- Install Spark NLPin your Databricks cluster
— In the Libraries tab inside the cluster you need to follow these steps:
— Install New -> PyPI -> spark-nlp==4.1.0 -> Install
— Install New -> Maven -> Coordinates -> johnsnowlabs.nlp:spark-nlp-gpu_2.12:4.1.0 -> Install
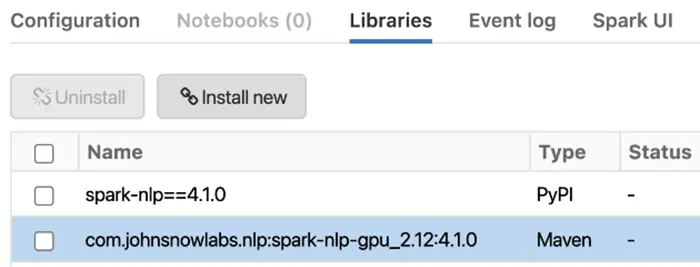
How to install Spark NLP in Databricks on GPUs for Python, Scala, and Java
I am going to run the benchmark on the smaller dataset to see which batch size is more suited for our GPU-based machine:
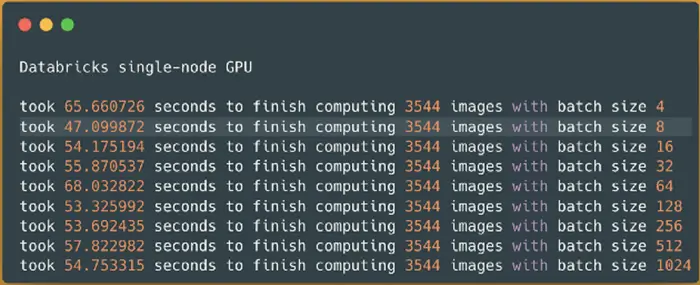
Spark NLP image-classification pipeline on Databricks single-node GPU — predicting 3544 images
It took less than a minute (47 seconds) to finish processing around 3544 images from our sample dataset on our single-node Databricks with a GPU device. We can see that batch size 8 performed the best in this specific use case so I will run the benchmark on the larger dataset:
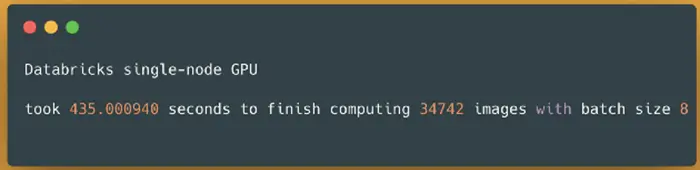
Spark NLP image-classification pipeline on Databricks single-node GPU — predicting 34742 images
On a larger dataset, it took almost 7 minutes and a half (435 seconds) to finish predicting classes for over 34K images. If we compare the results from our benchmarks on a single node with CPUs and a single node that comes with 1 GPU we can see that the GPU node here is the winner:
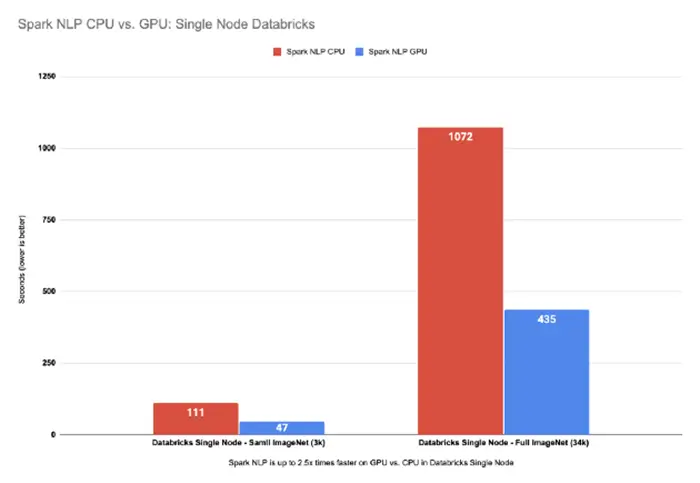
Spark NLP is up to 2.5x times faster on GPU vs. CPU in Databricks Single Node
This is great! We can see Spark NLP on GPU is up to 2.5x times faster than CPUs even with oneDNN enabled (oneDNN improves results on CPUs between 10% to 20%).
Let’s have a look at how these results are compared to Hugging Face benchmarks in the same Databricks Single Node cluster:
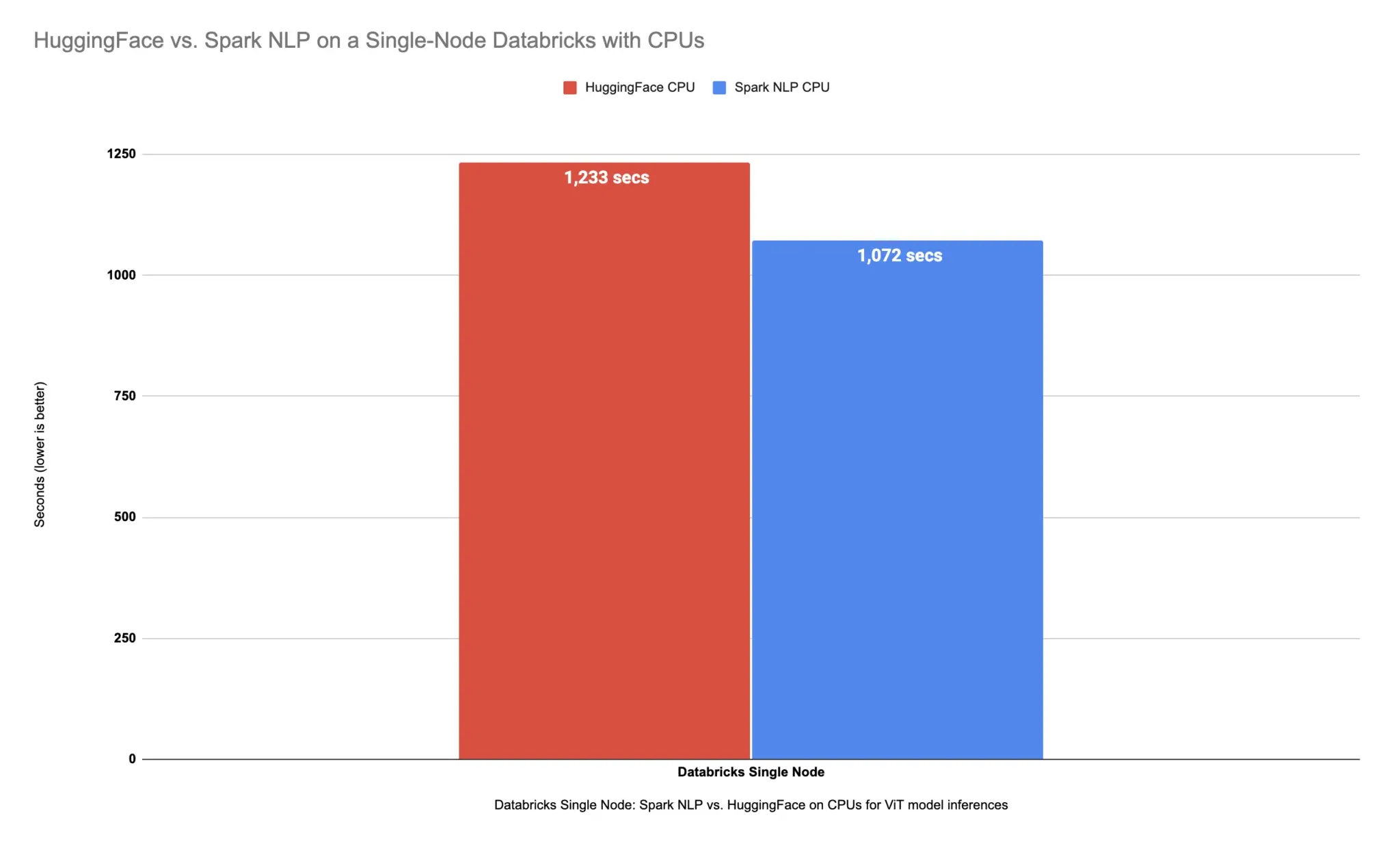
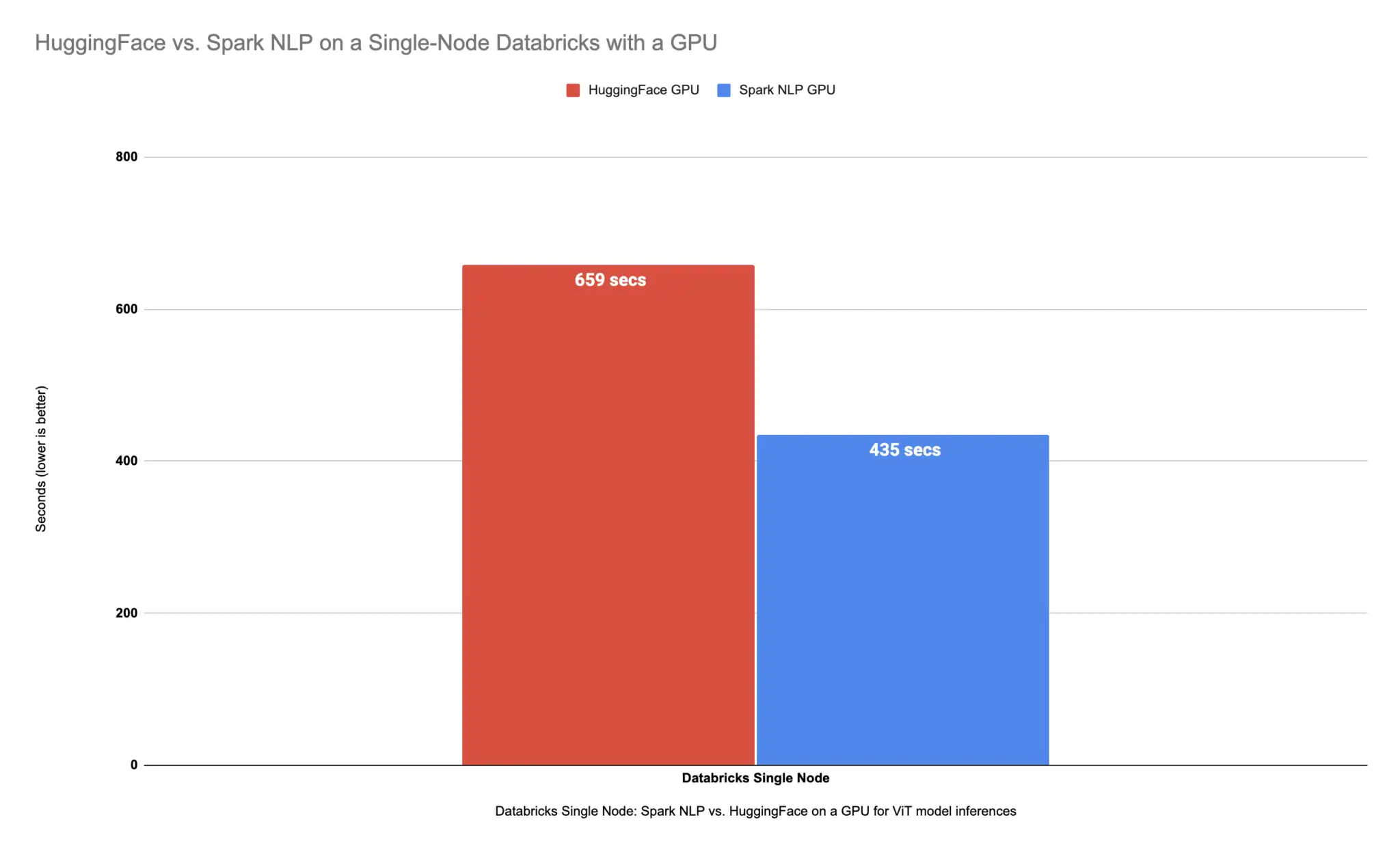
Spark NLP is up to 15% faster than Hugging Face on CPUs in predicting image classes for the sample dataset with 3K images and up to 34% on the larger dataset with 34K images. Spark NLP is also 51% faster than Hugging Face on a single GPU for a larger dataset with 34K images and up to 36% faster on a smaller dataset with 3K images.
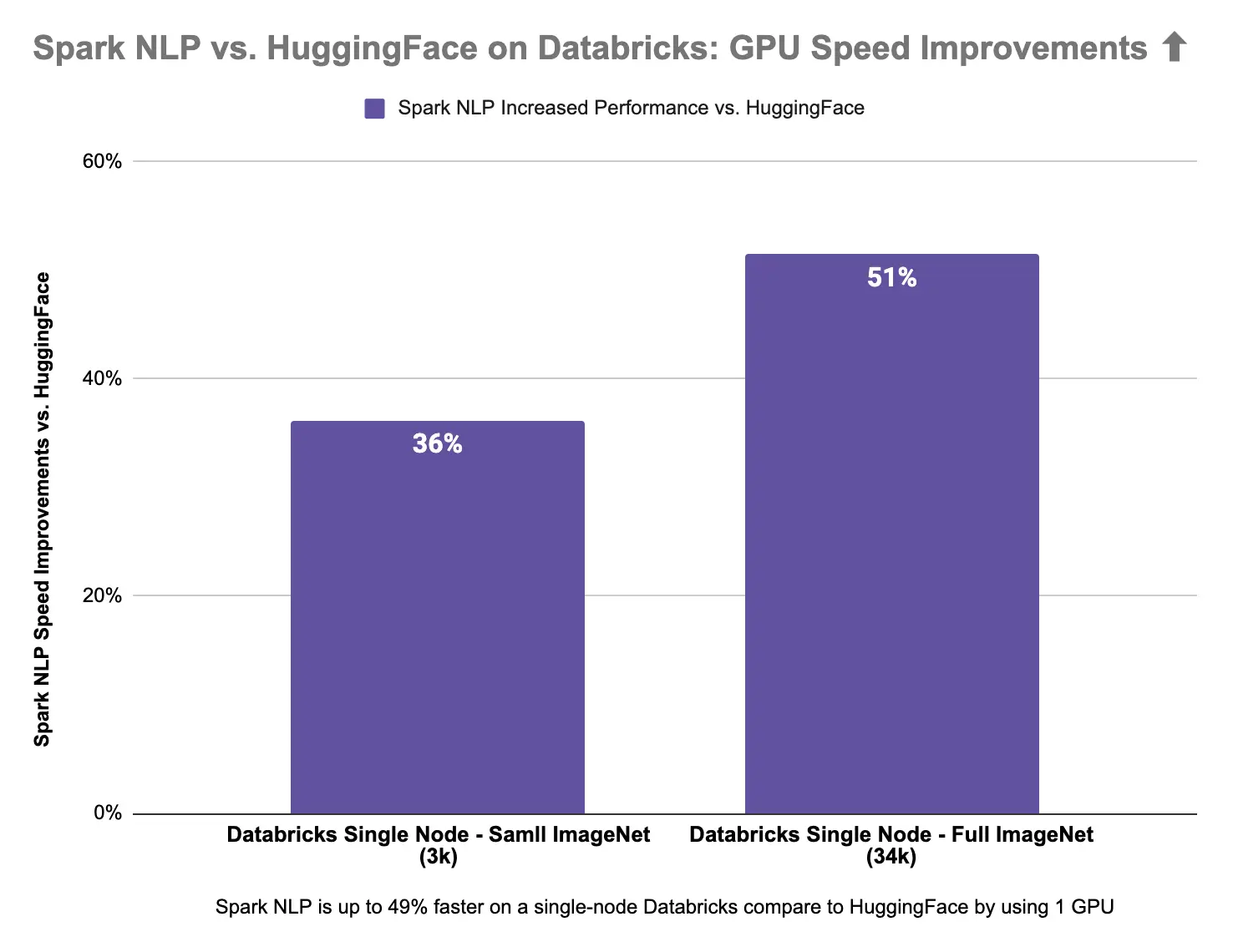
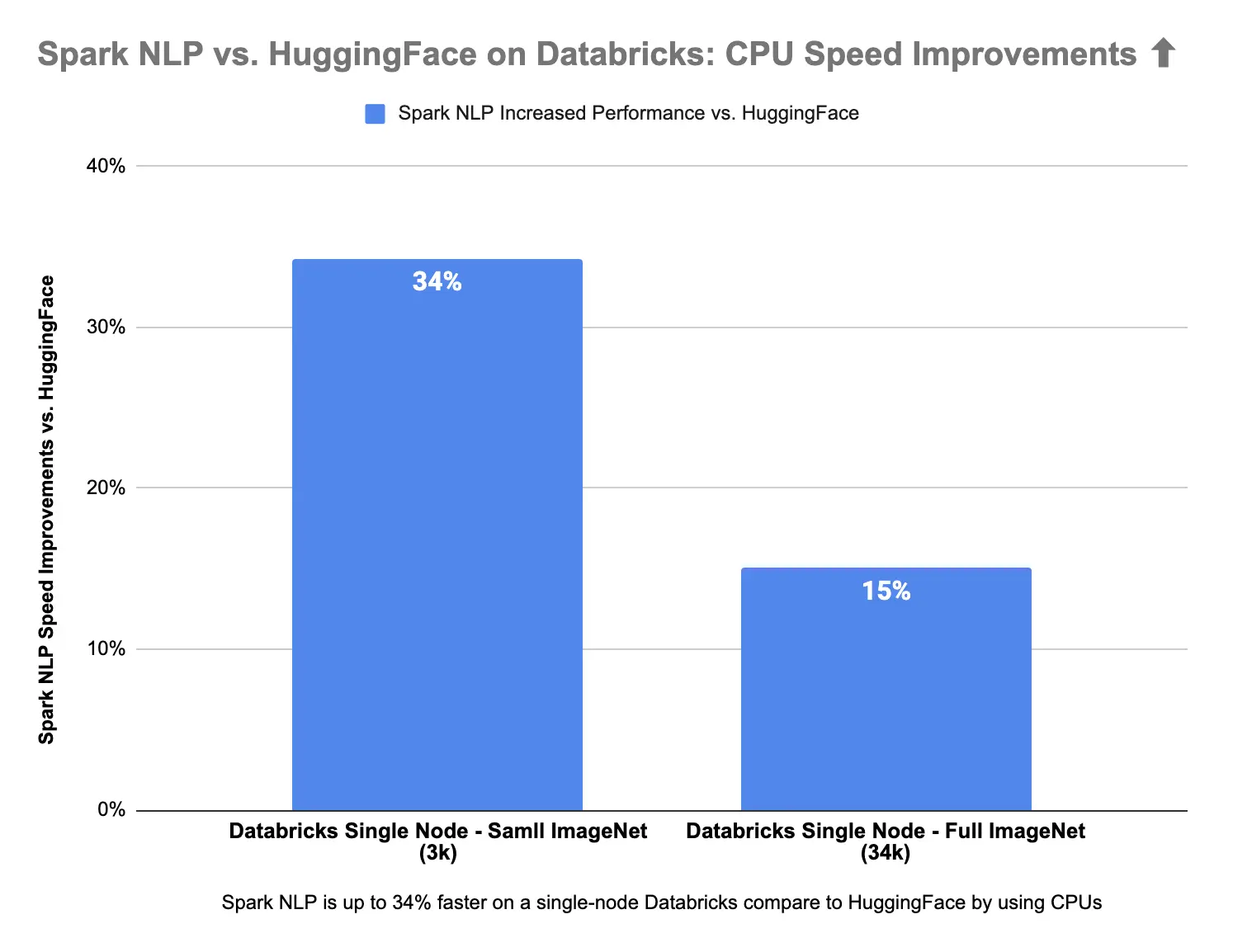
Spark NLP is faster on both CPUs and GPUs vs. Hugging Face in Databricks Single Node

Spark NLP is faster on both CPUs and GPUs vs. Hugging Face in Databricks Single Node
In Part 3 I will run the same benchmarks on Databricks Multi Nodes (CPU & GPU) to compare Spark NLP vs. Hugging Face.
References
ViT
- https://arxiv.org/pdf/2010.11929.pdf
- https://github.com/google-research/vision_transformer
- Vision Transformers (ViT) in Image Recognition — 2022 Guide
- https://github.com/lucidrains/vit-pytorch
- https://medium.com/mlearning-ai/an-image-is-worth-16×16-words-transformers-for-image-recognition-at-scale-51f3561a9f96
- https://medium.com/nerd-for-tech/an-image-is-worth-16×16-words-transformers-for-image-recognition-at-scale-paper-summary-3a387e71880a
- https://gareemadhingra11.medium.com/summary-of-paper-an-image-is-worth-16×16-words-3f7f3aca941
- https://medium.com/analytics-vidhya/vision-transformers-bye-bye-convolutions-e929d022e4ab
- https://medium.com/syncedreview/google-brain-uncovers-representation-structure-differences-between-cnns-and-vision-transformers-83b6835dbbac
Hugging Face
- https://huggingface.co/docs/transformers/main_classes/pipelines
- https://huggingface.co/blog/fine-tune-vit
- https://huggingface.co/blog/vision-transformers
- https://huggingface.co/blog/tf-serving-vision
- https://huggingface.co/blog/deploy-tfserving-kubernetes
- https://huggingface.co/google/vit-base-patch16-224
- https://huggingface.co/blog/deploy-vertex-ai
- https://huggingface.co/models?other=vit
Databricks
- https://www.databricks.com/spark/getting-started-with-apache-spark
- https://docs.databricks.com/getting-started/index.html
- https://docs.databricks.com/getting-started/quick-start.html
- See the best of DATA+AI SUMMIT 2022
- https://www.databricks.com/blog/2020/05/15/shrink-training-time-and-cost-using-nvidia-gpu-accelerated-xgboost-and-apache-spark-on-databricks.html
Spark NLP
- Spark NLP GitHub
- Spark NLP Workshop(Spark NLP examples)
- Spark NLP Transformers
- Spark NLP Models Hub
- Speed Optimization & Benchmarks in Spark NLP 3: Making the Most of Modern Hardware
- Hardware Acceleration in Spark NLP
- Serving Spark NLP via API: Spring and LightPipelines
- Serving Spark NLP via API (1/3): Microsoft’s Synapse ML
- Serving Spark NLP via API (2/3): FastAPI and LightPipelines
- Serving Spark NLP via API (3/3): Databricks Jobs and MLFlow Serve APIs
- Leverage deep learning in Scala with GPU on Spark 3.0
- Getting Started with GPU-Accelerated Apache Spark 3
- Apache Spark Performance Tuning
- Possible extra optimizations on GPUs: RAPIDS Accelerator for Apache Spark Configuration



