

























































In the world of natural language processing (NLP), LLMs like GPT-4 have changed the game for how machines understand and generate human language. They are the foundation for a ton of applications, from chatbots and virtual assistants to fancy data analysis tools. But as they get used more and more, we need to make sure they’re robust — that they work well with different kinds of input that we can’t predict. That’s where LangTest comes in. It’s an open-source evaluation tool that plays a key role in testing and improving the robustness of foundation models. This blog post will show you how to use LangTest in the Databricks environment to evaluate and improve the robustness of foundation models.
Understanding Robustness in LLM’s and LangTest for Model Evaluation
Grasping the Importance of Robustness in LLMs:
In natural language processing (NLP), large language models (LLMs) like GPT-4 have changed the game for how machines understand and generate human language. They are the foundation for a ton of applications, from chatbots and virtual assistants to fancy data analysis tools. But as they get used more and more, we need to make sure they’re robust — that they work well with different kinds of input that we can’t predict. That’s where LangTest comes in.
LangTest is an open-source evaluation tool that plays a key role in testing and improving the robustness of foundation models. In this blog post, we’ll show you how to use LangTest in the Databricks environment to evaluate and improve the robustness of foundation models. We’ll cover the basics of LangTest, how to set it up in Databricks, and how to run robustness tests on your foundation models. By the end of this post, you’ll have a better understanding of how to use LangTest to ensure the robustness of your foundation models.
Key aspects of robustness include:
- Handling Typos and Spelling Errors: Robust LLM models can interpret and respond to informal language and typographical errors without substantial loss in performance. This is essential for ethical and effective LLM operation in a variety of applications.
- Mitigating Adversarial Inputs: Robustness in LLM models ensures reliability. Robust models are resilient to adversarial attacks, which are malicious inputs designed to deceive or manipulate the model.
- Navigating Contextual Ambiguities: Language is ambiguous, and context is key to interpretation. Robust LLMs can discern meanings despite ambiguity.
Here we need to understand and address the robustness aspects of LLMs to make them work ethically and effectively in a wide range of applications.
LangTest for Evaluating Foundation Models
LangTest emerges as an indispensable tool for systematically assessing and enhancing the robustness of foundation models. LangTest is an open-source Python library designed to evaluate the robustness, bias, fairness, and accuracy of foundation models in NLP. Unlike tools focusing solely on model training or deployment, LangTest concentrates on the evaluation phase, providing a comprehensive suite of tests that simulate real-world and adversarial conditions.
Key Functionalities of LangTest:
- Perturbation Generation: Creates controlled modifications to input data, such as introducing typos, altering casing, or rephrasing sentences, to assess the model’s resilience.
- Bias and Fairness Evaluation: Analyzes model outputs to detect and measure biases across different demographics and contexts, promoting fair and unbiased AI.
- Seamless Integration with NLP Frameworks: Works effortlessly with popular NLP libraries like Hugging Face Transformers, John Snow Labs, Spacy, and Langchain, facilitating smooth incorporation into existing evaluation workflows.
By utilizing LangTest within the Databricks environment, developers and data scientists can conduct thorough evaluations of foundation models, ensuring they meet robustness standards essential for reliable and equitable deployment.
Setting Up LangTest in Databricks
Databricks offers a unified analytics platform that simplifies the process of building, training, and deploying machine learning models at scale. By Integrating LangTest into Databricks enhances the robustness evaluation workflow, providing a collaborative and scalable environment for model assessment.
Step-by-Step Guide to Configuring Databricks for Robustness Testing
- Create a Databricks Workspace
If you don’t already have a Databricks account:
- Sign Up: Visit the Databricks website and sign up for an account.
- Create a Workspace: Once registered, create a new workspace. This workspace will serve as the central hub for all your development and testing activities.
- Set Up a Cluster
A Databricks cluster provides the computational resources needed to run your notebooks and execute tasks.
- Navigate to Clusters: In your Databricks workspace, go to the Clusters section.
- Create a Cluster: Click on Create Cluster and configure the settings:
- Cluster Name: Choose a descriptive name.
- Databricks Runtime: Select a runtime version compatible with LangTest and your NLP libraries. (DBR 14.3 LTS recommended)
- Instance Type: Ensure the cluster has sufficient CPU and memory to handle LLM evaluation tasks.
- Start the Cluster: Once configured, start the cluster to make it ready for use.
- Install LangTest and Dependencies
Within a Databricks notebook attached to your cluster, install LangTest along with necessary dependencies using%pip.
# Install LangTest using pip %pip install langtest[databricks]==2.5.0
# Install LangTest using pip %pip install langtest[databricks]==2.5.0
Note: Using %pip install ensures that the packages are installed in the notebook’s environment, making them available for immediate use.
- Verify Installation
To confirm that LangTest and its dependencies are correctly installed, import them and perform a simple check.
%pip show langtest
Upon successful execution, you should see whether the LangTest is installed or not.
Implementing Robustness Tests on LLMs
With LangTest integrated into your Databricks environment, you can now implement and execute robustness tests on your foundation models. This involves generating perturbations, running the tests, and analyzing the results to gauge the model’s resilience.
Conducting Robustness Tests with LangTest
- Setup Harness
First, we need to set up the harness with the appropriate task and model. In this case, we are focusing on the question-answering task using the GPT-4o model from Databricks Model Serving.
import os
os.environ["OPENAI_API_KEY"] = "" # for evaluation
prompt_template = """
You are an AI bot specializing in providing accurate and concise answers
to questions. You will be presented with a medical question and
multiple-choice answer options.
Your task is to choose the correct answer.
\nQuestion: {question}\nOptions: {options}\n Answer:
"""
Test Config:
from langtest.types import HarnessConfig
test_config: HarnessConfig = {
"evaluation": {
"metric": "llm_eval",
"model": "gpt-4o", # for evaluation
"hub": "openai",
},
"tests": {
"defaults": {
"min_pass_rate": 1.0,
"user_prompt": prompt_template,
},
"robustness": {
"add_typo": {"min_pass_rate": 0.8},
"add_ocr_typo": {"min_pass_rate": 0.8},
"add_speech_to_text_typo":{"min_pass_rate": 0.8},
"add_slangs": {"min_pass_rate": 0.8},
"uppercase": {"min_pass_rate": 0.8},
},
},
}
Accessing the Data Source:
from pyspark.sql import DataFrame
# Load the dataset into a Spark DataFrame
MedQA_df: DataFrame = spark.read.json("dbfs:/MedQA/test-tiny.jsonl")
input_data = {
"data_source": MedQA_df,
"source": "spark",
"spark_session": spark
}
Model Config:
model_config = {
"model": {
"endpoint": "databricks-meta-llama-3-1-70b-instruct",
},
"hub": "databricks",
"type": "chat"
}
Harness initializing with model_config, input_data, and config.
from langtest import Harness harness = Harness( task="question-answering", model=model_config, data=input_data, config=test_config )
- Generating Test Cases
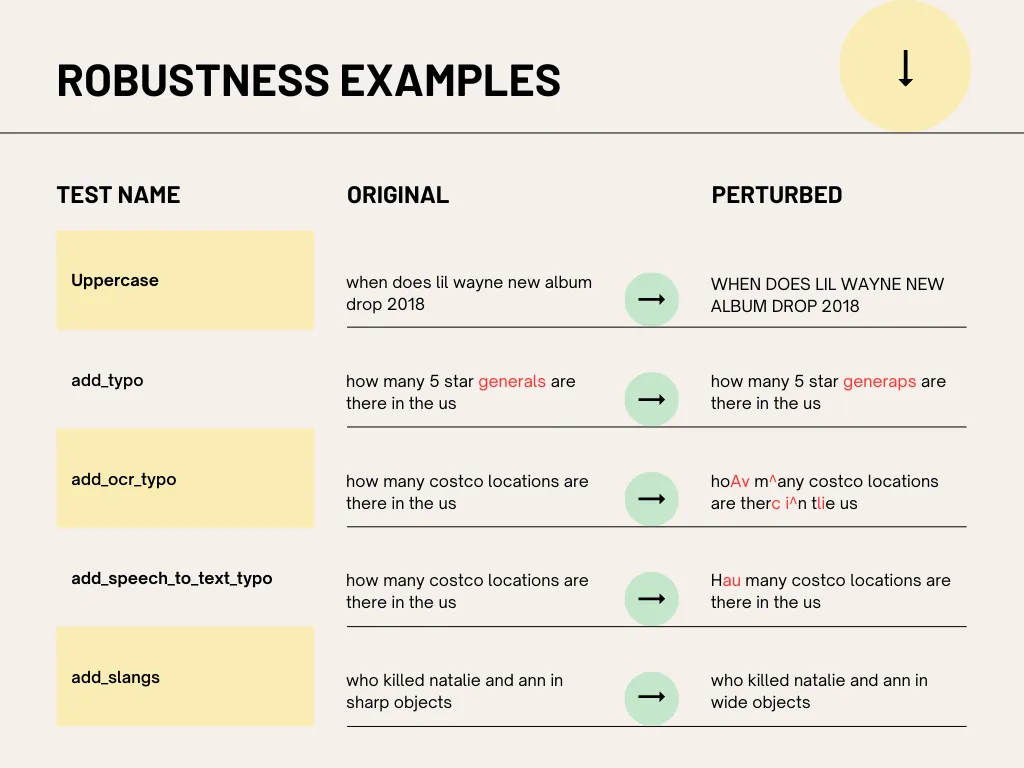
LangTest facilitates the generation of various test cases by introducing controlled perturbations to the input data. In this example, we focus on two types of perturbations: adding typos and converting text to lowercase.
# Generate test cases with perturbations harness.generate()
This command creates modified versions of the original dataset by introducing typos and altering the casing of the text, based on the configurations specified earlier.
- Running Robustness Tests
Once the test cases are generated, execute the robustness tests to evaluate the model’s performance against these perturbations.
# Run robustness tests harness.run()
This step processes each perturbed input through the model and records whether the model’s output meets the defined pass rates for each test type.
- Analyzing Model Performance
After running the tests, it’s crucial to analyze the results to understand how well the model handles various perturbations.
# Generate a detailed report of the results harness.report()
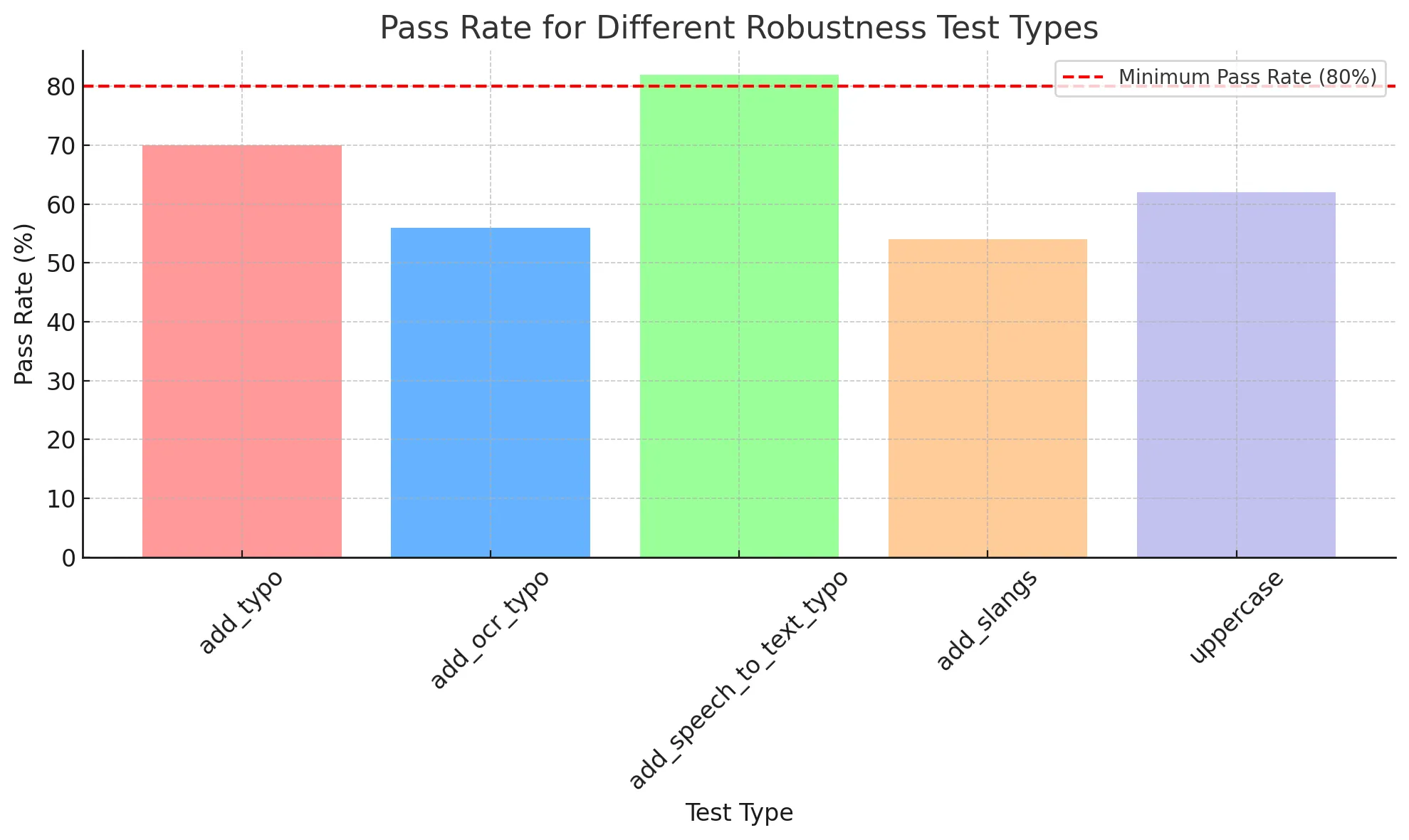
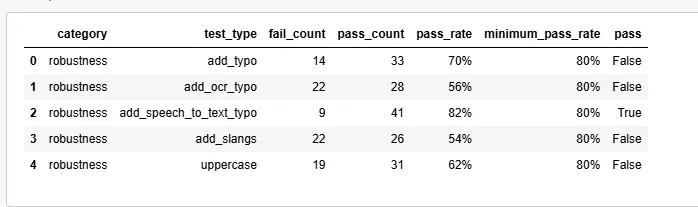
harness report on databricks-meta-llama-3-1-70b-instruct
- Storing the data into delta live tables
To create a Delta tablefrom a Spark DataFrametestcases_dlt_df,results_dlt_df, andreport_dlt_dfcontaining test cases, generated results, and reports from the harness. These data frames from the harness are append to an existing Delta table at the specifiedFilePathor create the new delta table ensuring efficient storage and versioning of data.
# Step 1: Create a DataFrame for test cases and save it to Delta format
# 'testcases' is the pandas data frame from harness.testcases()
testcases_dlt_df = spark.createDataFrame(testcases)
# Overwrite the existing Delta table with new test cases data
testcases_dlt_df.write.format("delta").save(
"dbfs:/MedQA/langtest_testcases"
)
# Step 2: Create a DataFrame for generated results and save it to Delta format
# 'generated_results' contains the results from the harness.generated_results()
results_dlt_df = spark.createDataFrame(generated_results)
# Save the results DataFrame to a new Delta table
results_dlt_df.write.format("delta").save("dbfs:/MedQA/langtest_results")
# Step 3: Create a data frame for the report and save it to Delta format
# 'report' contains the summary report from the harness.report()
report_dlt_df = spark.createDataFrame(report)
# Save the report DataFrame to a new Delta table
report_dlt_df.write.format("delta").save("dbfs:/MedQA/langtest_report")
Conclusion
Ensuring the robustness of Large Language Models is essential for their effective deployment in real-world applications. By leveraging LangTest within the Databricks environment, developers can systematically evaluate and enhance their models’ resilience against various perturbations and adversarial inputs. This comprehensive approach not only improves model accuracy and fairness but also builds trust in AI-driven solutions.
Robustness testing not only safeguards the reliability and accuracy of LLMs but also fortifies them against potential adversarial threats, thereby fostering trust in AI-driven applications. Embracing tools like LangTest in robust environments like Databricks equips organizations to deploy more dependable and fair language models, ultimately leading to more effective and trustworthy AI solutions.



