
























































One of the questions that Spark NLP users often ask me is what type of tasks can you quickly solve using Spark NLP out of the box. In order to provide intuitive and easy to understand answers to this question, we have started building demo applications that visually illustrate the use of Spark pretrained NLP models. The demo applications are available here: NLP demo.
For simplicity reasons, each application is focused on one feature, but the different models can also be combined into more complex pipelines if necessary.
Automatic annotation examples
As part of this exercise, we provide example texts on which we illustrate the results obtained using pre-trained models but also colab notebooks that can be used for running the pipelines on custom example documents.
This post focuses on the Open Source features we have included in the first release of the demo applications. The Spark NLP community resources currently include the following features.
Basic text preprocessing features
- Find text in a document– Finds a text in the document either by keyword or by regex expression.
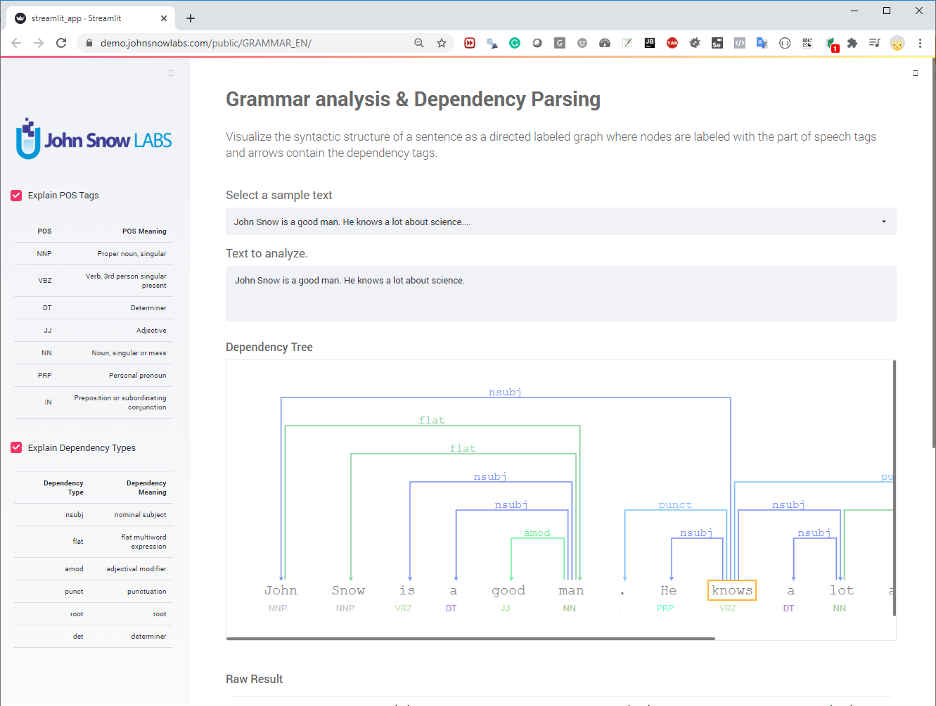
- Grammar analysis & Dependency Parsing– This application illustrates the syntactic structure of a sentence as a directed labeled graph where nodes are labeled with the part of speech tags and arrows contain the dependency tags.
- Split and clean text – Spark NLP pre-trained annotators allow an easy and straightforward processing of any type of text documents. This demo showcases the result obtained when applying Sentence Detector, Tokenizer, Stemmer, Lemmatizer, Normalizer and Stop Words Removal on text documents.
- Spell check your text documents – Spark NLP contextual spellchecker allows the quick identification of typos or spell issues within any text document.
- Find text in a document– Finds a text in document either by keyword or by regex expression.
 Figure 1. Streamlit app for grammatical text analysis and dependency parsing.
Figure 1. Streamlit app for grammatical text analysis and dependency parsing.
Entity recognition
- Recognize entities in text – This application can be used when you need to recognize Persons, Locations, Organizations and Misc entities. It uses out of the box pre-trained Deep Learning models based on GloVe (glove_100d) and BERT (ner_dl_bert) word embeddings.
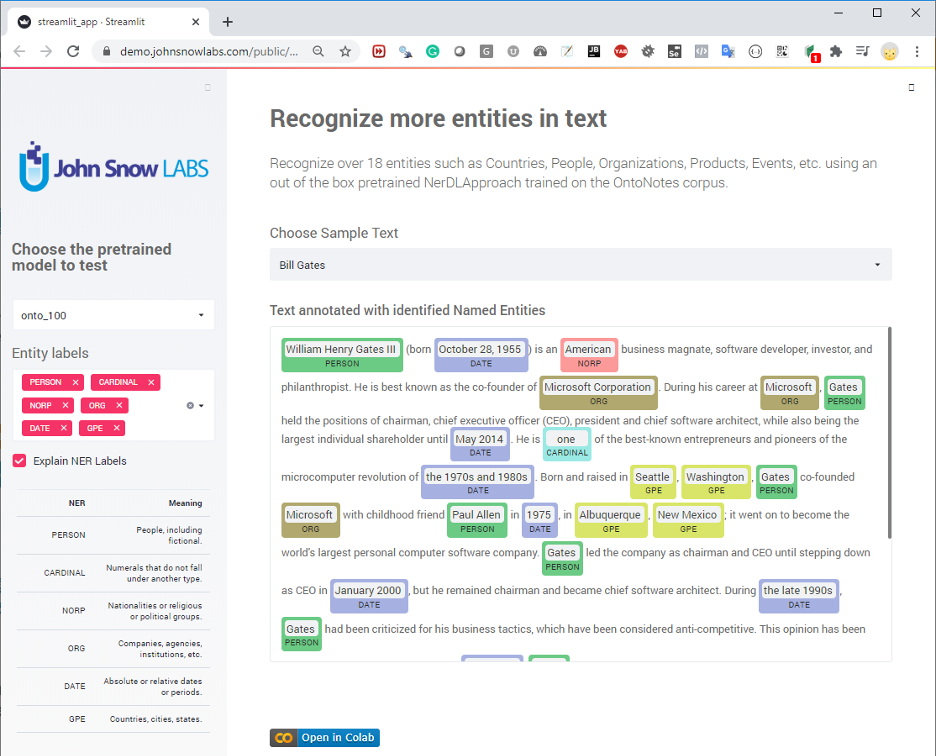
- Recognize more entities in text – This model is trained to recognize over 18 entities such as Countries, People, Organizations, Products, Events, etc. It has been trained on the OntoNotes corpus.
 Figure 2- Streamlit app for NER
Figure 2- Streamlit app for NER
Document classification
- Classify text according to TREC classes– Classify open-domain, fact-based questions into one of the following broad semantic categories: Abbreviation, Description, Entities, Human Beings, Locations or Numeric Values.
- Detect fake news – Determine if news articles are Real or Fake.
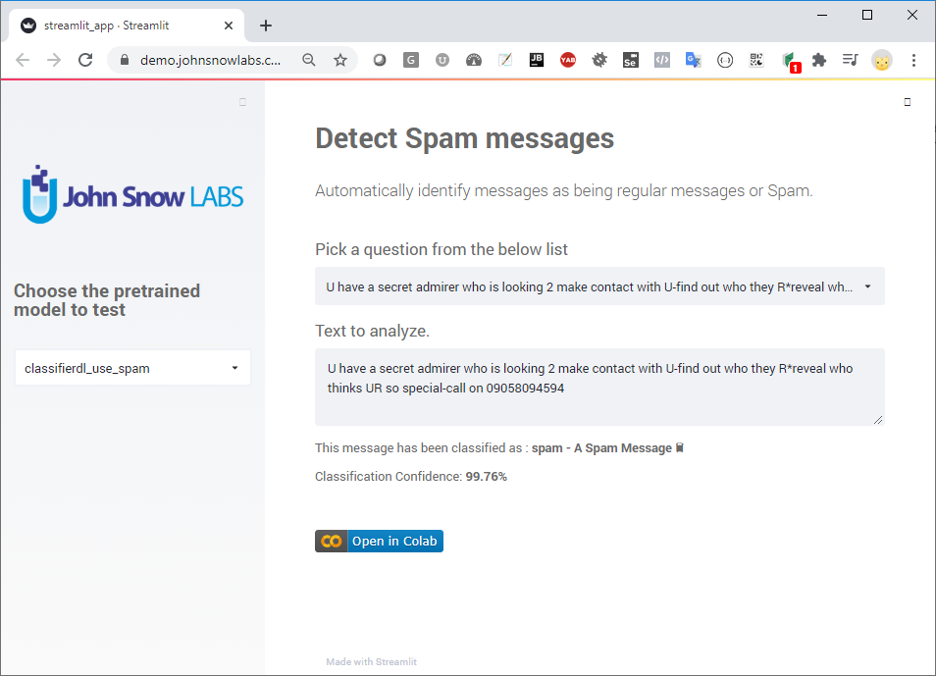
- Detect spam messages – Automatically identify messages as being regular messages or Spam.
 Figure 3 – Streamlit app for spam detection
Figure 3 – Streamlit app for spam detection
Sentiment analysis
- Sentiment detection – Detect the general sentiment expressed in a movie review or tweet by using our pre-trained Spark NLP DL classifier.
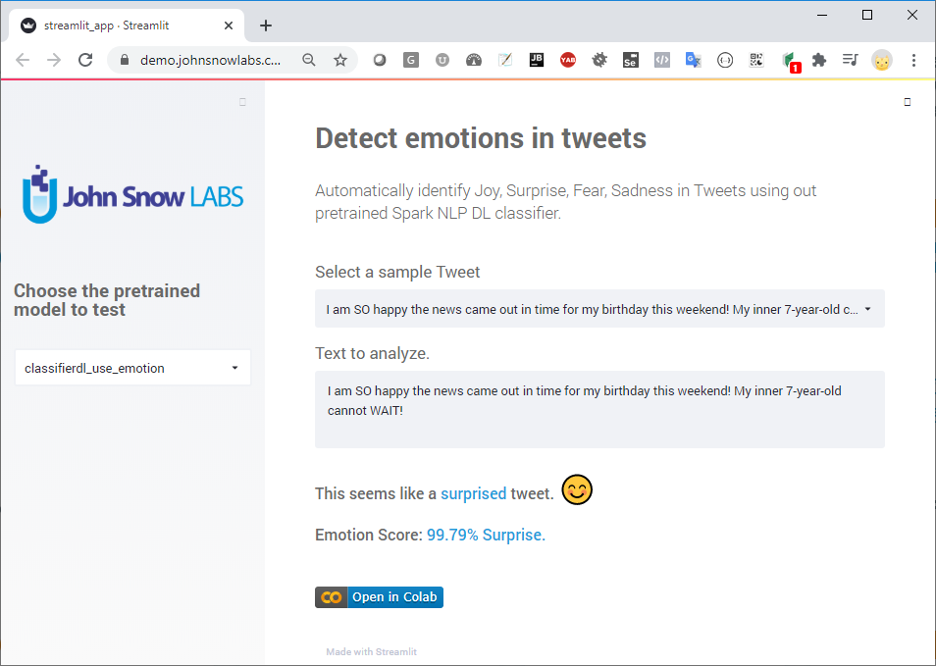
- Detect emotions in tweets – Automatically identify Joy, Surprise, Fear, Sadness in Tweets using out pre-trained Spark NLP DL classifier.
- Detect bullying in tweets – Identify Racism, Sexism, or Neutral tweets using our pre-trained emotions detector.
- Detect sarcastic tweets – This pre-trained Spark NLP model is able to tell apart from normal content from sarcastic content.
 Figure 4- Streamlit app for emotion detection in tweets.
Figure 4- Streamlit app for emotion detection in tweets.
Colab notebooks
For all demo applications, we are also providing colab notebooks that can be used for testing the models on additional documents or as a source of inspiration for creating more complex pipelines. All colab notebooks are freely available on our git repo https://github.com/JohnSnowLabs/spark-nlp-workshop.
This repo also contains additional training resources that you can test and use.
Conclusion
This is the first article in a series meant to present simple examples of how Spark NLP pre-trained models can be used to solve real-world problems. There are currently over 200 such models available both for general purpose and healthcare-specific. You can check the list of available models on our git repo: https://github.com/JohnSnowLabs/spark-nlp-models.
By leveraging out-of-the-box Spark NLP models, organizations can unlock the full potential of Generative AI in Healthcare, enabling innovations like a Healthcare Chatbot to provide seamless, real-time support, enhance patient engagement, and improve healthcare outcomes.
Problems?
Feel free to ping us on Github or join our slack channel!





