

























































New BART for Text Translation & Summarization, new ConvNeXT Transformer for Image Classification, new Zero-Shot Text Classification by BERT, more than 4000+ state-of-the-art models, and many more!
Overview
We are thrilled to announce the release of Spark NLP 4.4.0! This release includes new features such as a New BART for NLG, translation, and comprehension; a new ConvNeXTTransformer for Image Classification, a new Zero-Shot Text Classification by BERT, 4000+new state-of-the-art models, and more enhancements and bug fixes.
We want to thank our community for their valuable feedback, feature requests, and contributions. Our Models Hub now contains over 17,000+ free and truly open-source models & pipelines. 🎉
Spark NLP has a new home! https://sparknlp.org is where you can find all the documentation, models, and demos for Spark NLP. It aims to provide valuable resources to anyone interested in 100% open-source NLP solutions by using Spark NLP .
Full release note: https://github.com/JohnSnowLabs/spark-nlp/releases/tag/4.4.0
New Features
ConvNeXT Image Classification (By Facebook)
NEW: Introducing ConvNextForImageClassification annotator in Spark NLP. ConvNextForImageClassification can load ConvNeXT models that compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.
This annotator is compatible with all the models trained/fine-tuned by using ConvNextForImageClassification for PyTorch or TFConvNextForImageClassification for TensorFlow models in HuggingFace
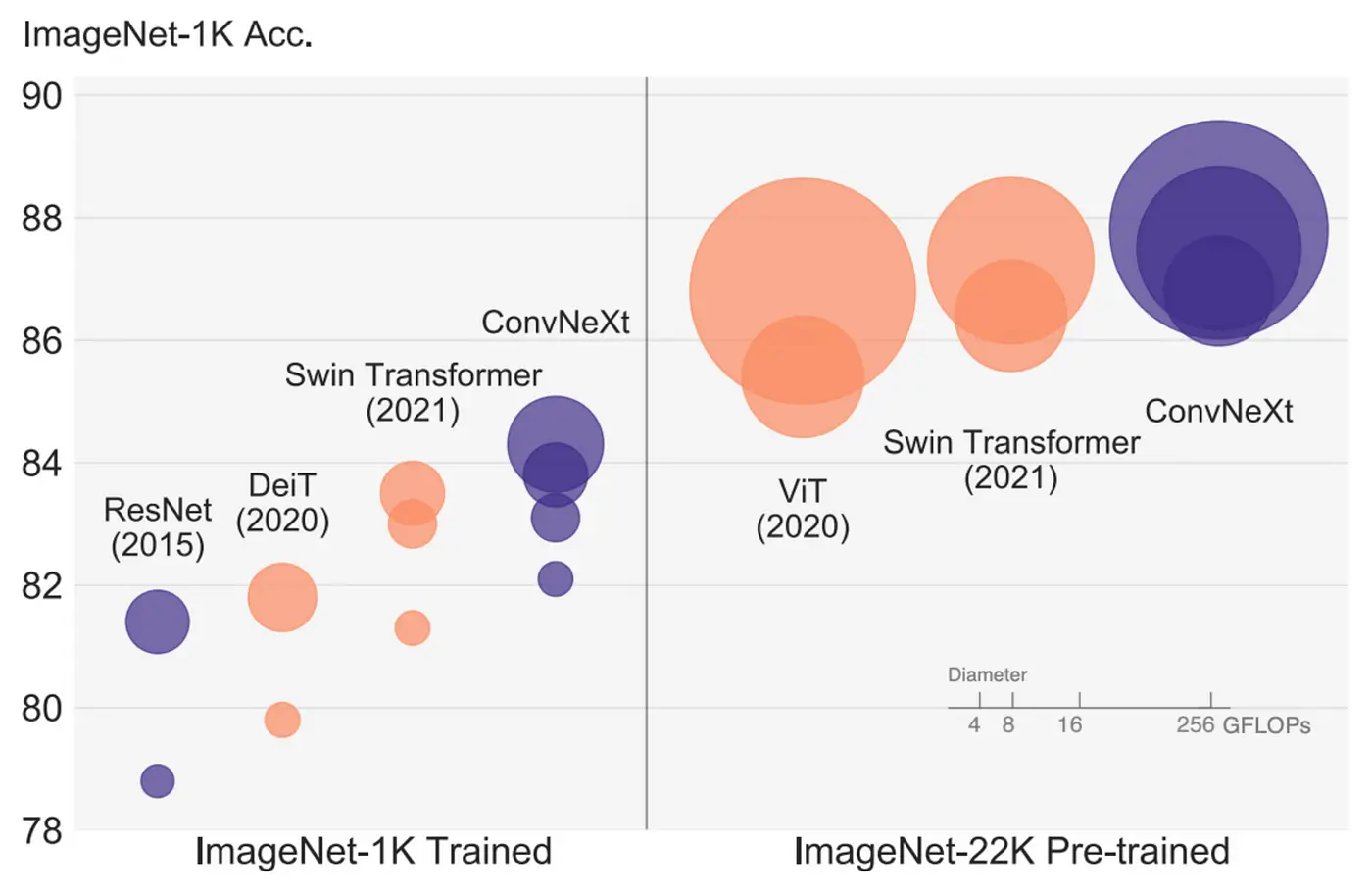
A ConvNet: ImageNet-1K classification results for • ConvNets and ◦ vision Transformers. Each bubble’s area is proportional to FLOPs of a variant in a model family. by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
BART for NLG, Translation, and Comprehension (By Facebook)
NEW: Introducing BartTransformer annotator in Spark NLP
BartTransformer can load BART models fine-tuned for tasks like summarizations.
This annotator is compatible with all the models trained/fine-tuned by using BartForConditionalGeneration for PyTorch or TFBartForConditionalGeneration for TensorFlow models in HuggingFace
The abstract explains that Bart uses a standard seq2seq/machine translation architecture, similar to BERT’s bidirectional encoder and GPT’s left-to-right decoder. The pretraining task involves randomly shuffling the original sentences and replacing text spans with a single mask token. BART is effective for text generation and comprehension tasks, matching RoBERTa’s performance with similar training resources on GLUE and SQuAD. It also achieves new state-of-the-art results on various summarization, dialogue, and question-answering tasks with gains of up to 6 ROUGE.
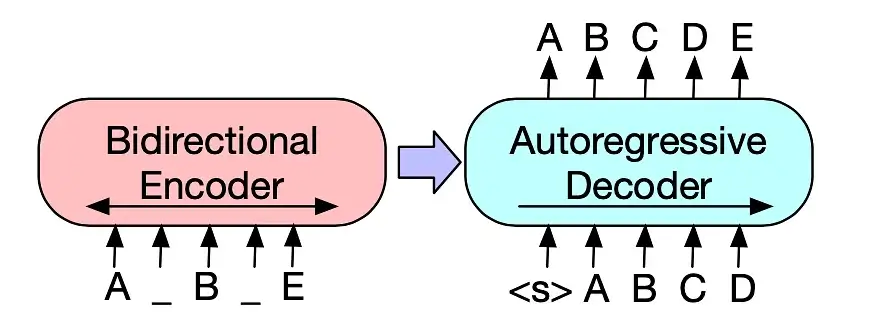
The Bart model was proposed in BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer
Zero-Shot for Text Classification by BERT
NEW: Introducing BertForZeroShotClassification annotator for Zero-Shot NLP Text Classification with Spark NLP. You can use the BertForZeroShotClassification annotator for text classification with your labels!
Zero-Shot Learning (ZSL): Traditionally, ZSL most often referred to a fairly specific type of task: learning a classifier on one set of labels and then evaluating on a different set of labels that the classifier has never seen before. Recently, especially in NLP, it’s been used much more broadly to get a model to do something it wasn’t explicitly trained to do. A well-known example of this is in the GPT-2 paper where the authors evaluate a language model on downstream tasks like machine translation without fine-tuning on these tasks directly.
Let’s see how easy it is to just use any set of labels our trained model has never seen via the setCandidateLabels() param:
zero_shot_classifier = BertForZeroShotClassification \
.pretrained() \
.setInputCols(["document", "token"]) \
.setOutputCol("class") \
.setCandidateLabels(["urgent", "mobile", "travel", "movie", "music", "sport", "weather", "technology"])
For Zero-Short Multi-class Text Classification:
+----------------------------------------------------------------------------------------------------------------+--------+ |result |result | +----------------------------------------------------------------------------------------------------------------+--------+ |[I have a problem with my iPhone that needs to be resolved asap!!] |[mobile]| |[Last week I upgraded my iOS version and ever since then my phone has been overheating whenever I use your app.]|[mobile]| |[I have a phone and I love it!] |[mobile]| |[I want to visit Germany and I am planning to go there next year.] |[travel]| |[Let's watch some movies tonight! I am in the mood for a horror movie.] |[movie] | |[Have you watched the match yesterday? It was a great game!] |[sport] | |[We need to hurry up and get to the airport. We are going to miss our flight!] |[urgent]| +----------------------------------------------------------------------------------------------------------------+--------+
For Zero-Short Multi-class Text Classification:
+----------------------------------------------------------------------------------------------------------------+-----------------------------------+ |result |result | +----------------------------------------------------------------------------------------------------------------+-----------------------------------+ |[I have a problem with my iPhone that needs to be resolved asap!!] |[urgent, mobile, movie, technology]| |[Last week I upgraded my iOS version and ever since then my phone has been overheating whenever I use your app.]|[urgent, technology] | |[I have a phone and I love it!] |[mobile] | |[I want to visit Germany and I am planning to go there next year.] |[travel] | |[Let's watch some movies tonight! I am in the mood for a horror movie.] |[movie] | |[Have you watched the match yesterday? It was a great game!] |[sport] | |[We need to hurry up and get to the airport. We are going to miss our flight!] |[urgent, travel] | +----------------------------------------------------------------------------------------------------------------+-----------------------------------+
Improvements & Bug Fixes
- Add a new
nerHasNoSchemaparamfor NerConverter when labels coming from NerDLMOdel and NerCrfModel don’t have any schema - Set custom entity name in Data2Chunk via
setEntityNameparam - Fix loading
WordEmbeddingsModelbugwhen loading a model from S3 via thecache_folderconfig - Fix the
WordEmbeddingsModelbugfailing when it’s used withsetEnableInMemoryStorageset toTrueand LightPipeline - Remove deprecated parameter
enablePatternRegexfromEntityRulerApproach&EntityRulerModel - Welcoming 3 new Databricks runtimes to our Spark NLP family:
– Databricks 12.2 LTS
– Databricks 12.2 LTS ML
– Databricks 12.2 LTS ML GPU
– Deprecate Python 3.6 in Spark NLP 4.4.0
Models
Spark NLP 4.4.0 comes with more than 4300+ new state-of-the-art pre-trained transformer models in multi-languages.
The complete list of all 17000+ models & pipelines in 230+ languages is available on Spark NLP Models Hub
Documentation
- Import models from TF Hub & HuggingFace
- Spark NLP Notebooks
- Models Hub with new models
- Spark NLP Documentation
- Spark NLP in Action
- Spark NLP Scala APIs
- Spark NLP Python APIs
Community support
- SlackFor live discussion with the Spark NLP community and the team
- GitHubBug reports, feature requests, and contributions
- DiscussionsEngage with other community members, share ideas,
and show off how you use Spark NLP! - MediumSpark NLP articles
- YouTubeSpark NLP video tutorials
Installation
Python
pip install spark-nlp==4.4.0
Spark Packages
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, and 3.3.x (Scala 2.12)
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_2.12:4.4.0 pyspark --packages com.johnsnowlabs.nlp:spark-nlp_2.12:4.4.0
GPU
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:4.4.0 pyspark --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:4.4.0
Apple Silicon (M1 & M2)
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:4.4.0 pyspark --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:4.4.0
AArch64
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:4.4.0 pyspark --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:4.4.0
Maven
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, and 3.3.x
com.johnsnowlabs.nlp
spark-nlp_2.12
4.4.0
spark-nlp-gpu
com.johnsnowlabs.nlp
spark-nlp-gpu_2.12
4.4.0
spark-nlp-silicon
com.johnsnowlabs.nlp
spark-nlp-silicon_2.12
4.4.0
spark-nlp-aarch64
com.johnsnowlabs.nlp
spark-nlp-aarch64_2.12
4.4.0
FAT JARs
- CPU on Apache Spark 3.x/3.1.x/3.2.x/3.3.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-assembly-4.4.0.jar
- GPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-gpu-assembly-4.4.0.jar
- M1 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-silicon-assembly-4.4.0.jar
- AArch64 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-aarch64-assembly-4.4.0.jar





