Become a master of text classification with Spark NLP’s comprehensive guide

Text classification is the process of assigning a category or label to a piece of text, such as an email, tweet, or review. It is commonly used in natural language processing (NLP) to organize text into predefined categories automatically and Spark NLP has multiple solutions for the text classification problem.
Text classification in NLP is the process of categorizing a text document into one or more predefined categories based on its content. For example, classifying news articles into categories such as politics, sports, entertainment, or technology are examples of common text classification use cases. Also, although considered as sentiment analysis, classifying customer reviews of a product or service as positive, negative, or neutral is also text classification.
Machine Learning Text Classification: What Does It Mean
Text classification is a machine learning technique and a fundamental area in NLP and information retrieval, and it is used in many applications such as sentiment analysis, spam filtering, topic categorization, and document organization.
Text classification in deep learning refers to the use of deep neural networks for the task of categorizing text documents into one or more predefined categories. The input is typically represented as a sequence of sentence embeddings to represent sentences as numerical vectors, which can then be used as input to a deep learning model. This allows the model to better understand the context of the text and make more accurate predictions.
The parameters of the deep neural network are trained on a labeled training dataset, typically using a supervised learning approach, where the objective is to minimize the difference between the predicted class labels and the true class labels. After training, the deep neural network can be used to classify new, unseen text documents.
In this article, the aim is to discuss the solutions provided by Spark NLP to text classification. We will take a look at the following approaches:
- Using a Pretrained Model from the John Snow Labs Models Hub to classify a set of texts.
- Training a Deep Learning model using a Spark NLP annotator and then use this model to make predictions.
- Investigate the Multiple Label Classification problem, both by using a pretrained model and also by training a Deep Learning model.
Let us start with a short Spark NLP introduction and then discuss the details of NLP text classification techniques with some solid results.
How to perform text classification with Spark NLP
Introduction to Spark NLP
Spark NLP is an open-source library maintained by John Snow Labs. It is built on top of Apache Spark and Spark ML and provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment.
Since its first release in July 2017, Spark NLP has grown in a full NLP tool, providing:
- A single unified solution for all your NLP needs
- Transfer learning and implementing the latest and greatest SOTA algorithms and models in NLP research
- The most widely used NLP library in industry (5 years in a row)
- The most scalable, accurate and fastest library in NLP history
Spark NLP comes with 14,500+ pretrained pipelines and models in more than 250+ languages. It supports most of the NLP tasks and provides modules that can be used seamlessly in a cluster.
Spark NLP processes the data using Pipelines, structure that contains all the steps to be run on the input data:
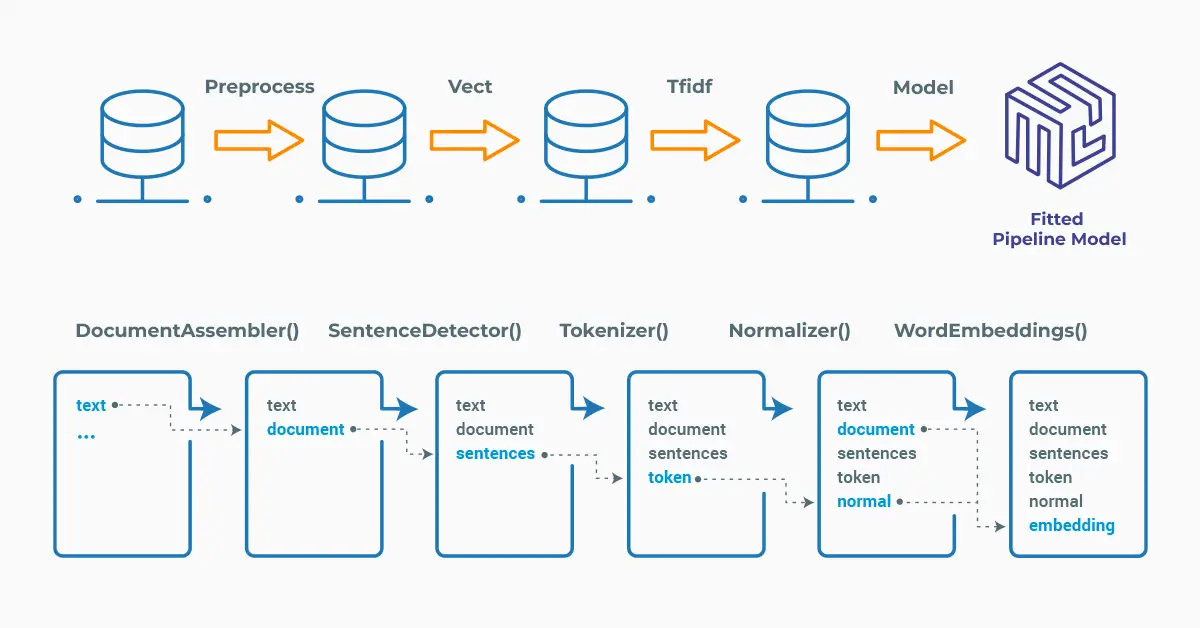
Spark NLP pipelines
Each step contains an annotator that performs a specific task such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
An annotator in Spark NLP is a component that performs a specific NLP task on a text document and adds annotations to it. An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. For example, a named entity recognizer annotator might identify and tag entities such as people, organizations, and locations in a text document, while a sentiment analysis annotator might classify the sentiment of the text as positive, negative, or neutral.
In this article, the aim is to discuss the text classification solutions provided by Spark NLP.
Spark NLP has multiple approaches for text classification, namely:
- Using a model from John Snow Labs Models Hub to categorize text,
- Training a model by using a labelled dataset and then test the fresh model’s accuracy,
- Finding solutions in Spark NLP for the multi-label classification.
Setup
To install Spark NLP in Python, simply use your favorite package manager (conda, pip, etc.). For example:
pip install spark-nlp pip install pyspark
For other installation options for different environments and machines, please check the official documentation.
Then, simply import the library and start a Spark session:
import sparknlp # Start Spark Session spark = sparknlp.start()
Using a Pretrained Model
ClassifierDLModel is an annotator in Spark NLP and it uses various embeddings as an input for text classifications.
Instead of training, saving, loading and getting predictions from a model, we can use a pretrained model. In machine learning, deep learning and NLP, a pretrained model is a model that has been trained on a large amount of data for a specific task, such as image recognition, text classification, or language translation. Pretrained models are typically trained on massive datasets using powerful hardware and advanced algorithms.
The models in John Snow Labs Model’s Hub are trained and optimized for greater-than-word length text, such as sentences, phrases or short paragraphs. They are trained on text (with variable lengths) and the output vector dimension depends on the type of embeddings that were used during training — typically ranges from 100 to 768 dimensions.
In text classification applications, it is crucial to consider all of the text instead of a single word because a single word may not provide enough information to accurately classify a text. By considering the entire text, we can capture the context of the text and use that to more accurately classify the text.
For this reason, UniversalSentenceEncoder, BertSentenceEmbeddings, SentenceEmbeddings or other sentence based embeddings can be used for preparing the embeddings stage.
To understand the concept better, we will use the following model: Fake News Classifier, where the model automatically determines whether a news article is Real or Fake using Universal Sentence Encoder embeddings. Model’s homepage will give you detailed information about the model, its size, data source used for training, benchmarking (metrics about the performance) and a sample pipeline showing how to use it.
The model was trained using Universal Sentence Encoder embeddings, so same embeddings must be used in the pipeline.
The screenshot below shows the search results for a Classifier on the Models Hub page:
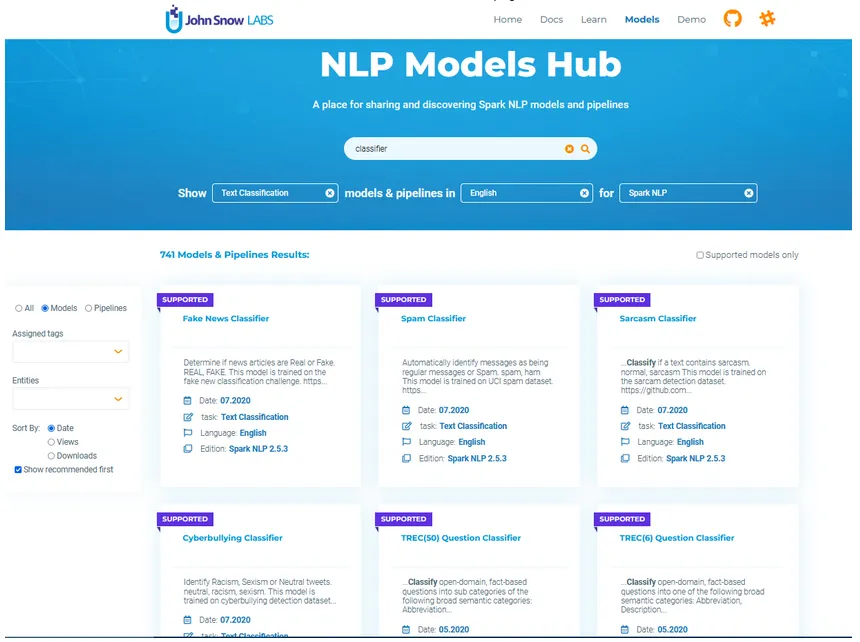
Fake News Classifier model homepage
The ClassifierDLModel annotator expects SENTENCE EMBEDDINGS as input, and then will provide CATEGORY as output. Thus, we need the previous steps to generate those annotations that will be used as input to our annotator.
Please check the details of the pipeline below, where we define a short pipeline (just 3 stages) and then define 10 texts for text classification:
# Import the required modules and classes
from sparknlp.base import DocumentAssembler, Pipeline
from sparknlp.annotator import (
UniversalSentenceEncoder,
ClassifierDLModel
)
import pyspark.sql.functions as F
import pandas as pd
# Step 1: Transforms raw texts to `document` annotation
document_assembler = (
DocumentAssembler()
.setInputCol("text")
.setOutputCol("document")
)
# Step 2: Encodes text into high dimensional vectors
use = UniversalSentenceEncoder.pretrained(lang="en") \
.setInputCols(["document"])\
.setOutputCol("sentence_embeddings")
# Step 3: Performs text classification
document_classifier = ClassifierDLModel.pretrained('classifierdl_use_fakenews', 'en') \
.setInputCols(["sentence_embeddings"]) \
.setOutputCol("category")
nlpPipeline = Pipeline(stages=[document_assembler, use, document_classifier])
text_list=[
"""Donald Trump a KGB Spy? 11/02/2016 In today's video, Christopher Greene of AMTV reports Hillary Clinton campaign accusation that Donald Trump is a KGB spy is about as weak and baseless a claim as a Salem witch hunt or McCarthy era trial. It's only because Hillary Clinton is losing that she is lobbing conspiracy theory. Citizen Quasar The way I see it, one of two things will happen: 1. Trump will win by a landslide but the election will be stolen via electronic voting, just like I have been predicting for over a decade, and the American People will accept the skewed election results just like they accept the TSA into their crotches. 2. Somebody will bust a cap in Hillary's @$ killing her and the election will be postponed. Follow AMTV!""",
"""President Barack Obama said former Secretary of State Hillary Clinton's use of a personal email server was a mistake, but that U.S. national security hadn't been endangered. In his first extensive remarks on the controversy that has roiled the Democratic presidential primary, Mr. Obama said on CBS's "60 Minutes" program that questions about Mrs. Clinton's email arrangement were legitimate. "It is important for her to answer these questions to the satisfaction of the American public," Mr. Obama said.""",
"""Abby Martin Exposes What Hillary Clinton Really Represents ‹ › Since 2011, VNN has operated as part of the Veterans Today Network ; a group that operates over 50 plus media, information and service online sites for U.S. Military Veterans. Morning Joe Destroys Corrupt Clinton Foundation (Laughable) "Total Corruption" By VNN on October 28, 2016 'Pay for Play' and 'Quid Pro Quo' 'Shut Down The Foundation' Inside the Clinton's Foundation and Personal Gains They are bragging that they can shake down foundation clients, for Bill Clinton money… This is sleazy… Joe Scarborough. Follow the money.""",
"""President Barack Obama is ramping up efforts to convince individual House members to grant him fast-track authority to negotiate trade deals, focusing his efforts on a dwindling group of undecided Democratic lawmakers.But Democrats who have already backed the deal publicly said these members need to be convinced they are not trading away their own political futures for a vote on fast-track. Potentially decisive are moderate, pro-growth members of the New Democrat Coalition. Its vice-chair, Rep. Jim Himes (D., Conn.), spoke as recently as Monday to the president, after fielding calls from the White House during last week's recess as well.""",
"""Most American spend over 9 hours a day using media. Is this making us dumber?? Are you living in a media induced trace? Do you know the truth of the world or do you know what the manipulators want you to know?! Professor Jerry Kroth (Ph. D. Psychology) examines the ties between advertising and factual knowledge. Most people can name every mascot of most companies, but they can not name hardly any historical figures. How did we get here? These are questions that Professor Kroth explains in this well thought out presentation. This talk is based on Dr. Kroth's recent book, "Duped! Delusion, Denial, and the end of the American dream." """,
"""Michael Brown's parents plan to bring a civil lawsuit for the wrongful death of their son against Darren Wilson and the city of Ferguson, Missouri. The announcment came a day after the Justice Department released its report on the abuses of the city's police department and said Wilson wouldn't be charged for violating Brown's civil rights. Brown family lawyers note that the burden of proof is lower in a civil case than the criminal cases that were considered by both the federal government and a St. Louis County grand jury.""",
"""It's Going to Change RADICALLY With Silver – HUGE Demand Coming | Cliff High Data mining expert Cliff High says the economy is much worse than most people think, and that bubble is going to pop after Election Day. Inflation is also coming, and that will be very positive for precious metals . High contends, " Gold and silver are going to rise relative to the falling currencies. Gold and silver in actual purchasing power will also rise. They won't be saying an ounce of gold bought a good suit 100 years ago and an ounce of gold will buy a good suit now. That's going to change, and it's also going to change radically with silver . Also, in our data sets between 2019 and 2024 , silver becomes the metal to have… You need to have silver . 2017 Gold Pandas and 2017 Silver Pandas Are Now Available! Secure Your 2017 Panda Coins Today at SD Bullion!""",
"""Senate Majority Leader Mitch McConnell announced a "Plan B" to halt a nuclear deal that would lift sanctions against Iran.The measure, which Republican aides said likely would be voted on Thursday, would prevent President Obama from lifting the sanctions until Iran releases four jailed Americans and recognizes the right of Israel to exist.McConnell made the announcement as Democrats prepared for a second time to filibuster a resolution of disapproval of the nuclear deal. Soon after McConnell's remarks, 42 Democrats again filibustered the resolution, preventing it from getting the 60 votes needed to advance."My strong preference is for Democrats to simply allow an up-or-down vote on the president's Iran deal." McConnell said. "But if they're determined to make that impossible, then at the very least we should be able to provide some protection to Israel and long-overdue relief to Americans who've languished in Iranian custody for years. Either way, this debate will continue." """,
"""TRUMP TSUNAMI INCOMING: What Trump Did In Florida Today Will Make Him President! TRUMP TSUNAMI INCOMING: What Trump Did In Florida Today Will Make Him President! fisher 5 mins ago News Comments Off on TRUMP TSUNAMI INCOMING: What Trump Did In Florida Today Will Make Him President! TRUMP TSUNAMI INCOMING: What Trump Did In Florida Today Will Make Him President! Breaking! Breaking! Bad news for Hillary in Florida. Early voting numbers from Florida are showing that Republicans have cast 17,000 more votes than Democrats. *** 6 days before the Election in 2012, Democrats in Florida cast 39,000 more votes than Republicans. *** Today, six days before the election, Republicans have now cast 17,000 more votes than Democrats. Watch Trump in Miami, FL today: """,
"""Sen. Marco Rubio (R-Fla.) is adding a veteran New Hampshire political operative to his team as he continues mulling a possible 2016 presidential bid, the latest sign that he is seriously preparing to launch a campaign later this year.Jim Merrill, who worked for former GOP presidential nominee Mitt Romney and ran his 2008 and 2012 New Hampshire primary campaigns, joined Rubio's fledgling campaign on Monday, aides to the senator said.Merrill will be joining Rubio's Reclaim America PAC to focus on Rubio's New Hampshire and broader Northeast political operations."Marco has always been well received in New Hampshire, and should he run for president, he would be very competitive there," Terry Sullivan, who runs Reclaim America, said in a statement. "Jim certainly knows how to win in New Hampshire and in the Northeast, and will be a great addition to our team at Reclaim America."News of Merrill's hire was first reported by The New York Times.""",
]
In Spark ML, we need to fit the obtained pipeline to make predictions (see this documentation page if you are not familiar with Spark ML).
After that, we get predictions by transforming the model.
# Create a dataframe
empty_df = spark.createDataFrame([['']]).toDF("text")
# Fit the dataframe
pipelineModel = nlpPipeline.fit(empty_df)
df = spark.createDataFrame(pd.DataFrame({"text":text_list}))
# Get predictions
result = pipelineModel.transform(df)
We exploded the results to show the predicted classes for the corresponding texts in a dataframe.
result.select(F.explode(F.arrays_zip(result.document.result, result.category.result)).alias("cols")) \
.select(F.expr("cols['0']").alias("document"),
F.expr("cols['1']").alias("class")).show(truncate=150)

Predicted classes for the texts (Fake or Real)
One-liner alternative
In October 2022, John Snow Labs released the open-source johnsnowlabs library that contains all the company products, open-source and licensed, under one common library. This simplified the workflow especially for users working with more than one of the libraries (e.g., Spark NLP + Healthcare NLP). This new library is a wrapper on all John Snow Lab’s libraries, and can be installed with pip:
pip install johnsnowlabs
Please check the official documentation for more examples and usage of this library. To run the Fake News Identification model with one line of code, we can simply:
# Import the NLP module which contains Spark NLP and NLU libraries
from johnsnowlabs import nlp
fake_df = nlp.load('classify.fakenews.use').predict("""Donald Trump a KGB Spy? 11/02/2016 In today’s video, Christopher Greene of AMTV reports Hillary Clinton""", output_level='document')
fake_df[["document", "fakenews"]]
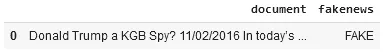
After using the one-liner model, the result shows that the text is FAKE
The one-liner is based on default models for each NLP task. Depending on your requirements, you may want to use the one-liner for simplicity or customizing the pipeline to choose specific models that fit your needs.
NOTE: when using only the johnsnowlabs library, make sure you initialize the spark session with the configuration you have available. Since some of the libraries are licensed, you may need to set the path to your license file. If you are only using the open-source library, you can start the session with spark = nlp.start(nlp=False). The default parameters for the start function includes using the licensed Healthcare NLP library with nlp=True, but we can set that to False and use all the resources of the open-source libraries such as Spark NLP, Spark NLP Display, and NLU.
For additional information, please check the following references.
- Documentation : ClassifierDLModel
- Python Docs : ClassifierDLModel
- Scala Docs : ClassifierDLModel
- For extended examples of usage, see the Spark NLP Workshop repository.
Training a Deep Learning Model
ClassifierDLApproach is an annotator in Spark NLP and it provides the ability to train models for text classification.
It is possible to train a text classifier model with Bert, Elmo, Glove and Universal Sentence Encoders (USE) in Spark NLP using the ClassifierDLApproach annotator. Please remember that models are trained and optimized for greater-than-word length text, such as sentences, phrases or short paragraphs, so we have to use sentence embeddings. In NLP, sentence embeddings are fixed-length numerical representations of sentences that capture their semantic meanings.
USE encodes text into high dimensional vectors that can be used for text classification, semantic similarity, clustering and other natural language tasks.
For model training, we need training and test datasets. We load the datasets from John Snow Labs AWS S3 and get them as dataframes.
! wget -q https://raw.githubusercontent.com/JohnSnowLabs/spark-nlp-workshop/master/tutorials/Certification_Trainings/Public/data/news_category_train.csv
! wget -q https://raw.githubusercontent.com/JohnSnowLabs/spark-nlp-workshop/master/tutorials/Certification_Trainings/Public/data/news_category_test.csv
# Separate training and testing datasets are created
trainDataset = spark.read \
.option("header", True) \
.csv("news_category_train.csv")
testDataset = spark.read \
.option("header", True) \
.csv("news_category_test.csv")
# Take a look at the dataset
testDataset.show(10, truncate=130)

Test dataset (first 10 rows)
See the total number of labelled texts and their perfect distribution.
trainDataset.groupBy('category').count().show()
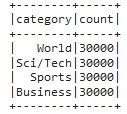
Training dataset contains 120,000 news and 4 classes
The pipeline below is similar to the one that we used for ClassifierDLModel; except in this case we use ClassifierDLApproach annotator for model training.
# Step 1: Transforms raw texts to `document` annotation
document = DocumentAssembler()\
.setInputCol("description")\
.setOutputCol("document")
# Step 2: Encodes text into high dimensional vectors
use = UniversalSentenceEncoder.pretrained("tfhub_use_lg", "en") \
.setInputCols("document") \
.setOutputCol("sentence_embeddings")
# Stage 3: Performs model training
classsifierdl = ClassifierDLApproach()\
.setInputCols(["sentence_embeddings"])\
.setOutputCol("class")\
.setLabelColumn("category")\
.setMaxEpochs(5)\
.setLr(0.001)\
.setBatchSize(16)\
.setEnableOutputLogs(True)
use_clf_pipeline = Pipeline(stages = [document,
use,
classsifierdl])
# Fit the training dataset to train the model
pipelineModel = use_clf_pipeline.fit(trainDataset)
Note that there are many parameters that you can use with the ClassifierDLApproach annotator and they play a vital role in model training. Please check the Notebook for detailed information about these parameters and their effects on the accuracy of the trained models.

Training logs show the increase in the accuracy value of the model
Using just 5 Epochs, a model using Universal Sentence Encoders provided an accuracy value of ~ 90 %. The number of epochs used in the training of a text classification model depends on various factors, such as the size of the dataset, the complexity of the model, the quality of the features, and the desired accuracy of the model. It is common to use 10–100 epochs in text classification model training. Considering that, there is still room for improvement of this model and the F1 score is expected to increase with higher epoch numbers.
It’s important to keep in mind that using too many epochs can lead to overfitting, where the model becomes too specific to the training data and performs poorly on new, unseen data. In overfitting, the model memorizes the training data and is unable to generalize to new data.
On the other hand, using too few epochs can result in underfitting, where the model doesn’t learn enough from the training data to make accurate predictions. In this case, the model is not able to achieve high accuracy even on the training data and it is not complex enough to capture the patterns in the data and is unable to learn from the training data.
Remember that we used the training dataset for model training and the freshly trained model is unbiased to the test dataset. Let us use the test dataset for getting predictions and check the accuracy of the model.
from sklearn.metrics import classification_report
preds = use_pipelineModel.transform(testDataset)
preds_df = preds.select('category','description',"class.result").toPandas()
preds_df['result'] = preds_df['result'].apply(lambda x : x[0])
print (classification_report(preds_df['category'], preds_df['result']))
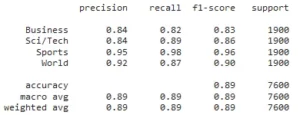
Classification report showing the model’s performance
In Spark NLP, it is possible to save the model with one line of code, ready to call later and get predictions. See below the saving, loading and getting predictions stages:
# Save the Model
use_pipelineModel.stages[2].write().overwrite().save('useClassifierDL')
# Load back the saved Model
Classifier_Model = ClassifierDLModel.load('useClassifierDL')
# Generate prediction Pipeline with loaded Model
ld_pipeline = Pipeline(stages=[document, use, Classifier_Model])
ld_pipeline_model = ld_pipeline.fit(spark.createDataFrame([['']]).toDF("description"))
# Apply Model Transform to testData
ld_preds = ld_pipeline_model.transform(testDataset)
ld_preds.select('category','description','class.result').show(8, truncate = 130)

Class predictions of the trained model
For additional information, please check the following references.
- Documentation : ClassifierDL
- Python Docs : ClassifierDLApproach
- Scala Docs : ClassifierDLApproach
- For extended examples of usage, see the Spark NLP Workshop repository.
- For additional information, see Text Classification in Spark NLP with Bert and Universal Sentence Encoders.
Multi Label Text Classification
Multi Label Classification is a type of text classification with NLP where a document can belong to more than one category or label. For example, a social media post can have multiple tags such as #travel, #food, and #adventure. Another example is where a patient’s medical records can have multiple diagnoses such as diabetes, hypertension, and obesity.
A multi-label text classification NLP model can be trained to tag each post with relevant labels based on its content. Multi-label text classification is a challenging but essential task in many industries, including e-commerce, healthcare, and law.
In this section, we will perform multi-label classification of tweets in order to show the use and efficiency of the deep learning based MultiClassifierDL annotator — first use a model from the John Snow Labs Models Hub, then train a model for prediction.
MultiClassifierDLModel
Let us try Toxic Comment Classification from the John Snow Labs Models Hub. This model automatically detects identity hate, insult, obscene, severe toxic, threat, or toxic content in texts / comments using our out-of-the-box Spark NLP MulticlassifierDLModel annotator.
The MultiClassifierDLModel annotator expects SENTENCE EMBEDDINGS as input, and then will provide CATEGORY as output. Check the short pipeline below:
# Import the required modules and classes
from sparknlp.base import DocumentAssembler, Pipeline
from sparknlp.annotator import (
UniversalSentenceEncoder,
MultiClassifierDLModel
)
import pyspark.sql.functions as F
# Step 1: Transforms raw texts to `document` annotation
document_assembler = (
DocumentAssembler()
.setInputCol("text")
.setOutputCol("document")
)
# Step 2: Encodes text into high dimensional vectors
use = UniversalSentenceEncoder.pretrained(lang="en") \
.setInputCols(["document"])\
.setOutputCol("sentence_embeddings")
# Step 3: Performs multi-label text classification
document_classifier = MultiClassifierDLModel.pretrained('multiclassifierdl_use_toxic_sm', 'en') \
.setInputCols(["sentence_embeddings"]) \
.setOutputCol("class")
nlpPipeline = Pipeline(stages=[documentAssembler, use, document_classifier])
sample_text = ["""You're funny. Ugly? We're dudes on computers moron.. You are quite astonishingly stupid, Wtf kind of crap is this."""]
Now, we fit and transform to get predictions about the sample text.
# Create a dataframe
empty_df = spark.createDataFrame([['']]).toDF("text")
# Fit the dataframe
pipelineModel = nlpPipeline.fit(empty_df)
df = spark.createDataFrame(pd.DataFrame({"text":sample_text}))
# Get predictions
result = pipelineModel.transform(df)
Explode the results to show the predicted classes for the corresponding texts in a dataframe.
result.select(F.explode(F.arrays_zip(result.document.result, result.category.result)).alias("cols")) \
.select(F.expr("cols['0']").alias("document"),
F.expr("cols['1']").alias("category")).show(truncate = False)

According to the model, this text may be defined with 3 labels
One-liner alternative
Let’s see the one-liner alternative for the ‘Toxic Comment Classification — Small’ model:
multi_df = nlp.load('en.classify.toxic.sm').predict("""You're funny. Ugly? We're dudes on computers moron. You are quite astonishingly stupid, Wtf kind of crap is this.""")
multi_df[["document", "toxic"]]

After using the one-liner model, the result shows that the text may be considered both as TOXIC and INSULT
Let’s just mention once again that the one-liner is based on default models for each NLP task. Depending on your requirements, you may want to use the one-liner for simplicity or customizing the pipeline to choose specific models that fit your needs.
MultiClassifierDLApproach
Now, we will train a model by using the MultiClassifierDLApproach annotator, which is used for model training.
First, load the train (14620 rows) and test (1605 rows) datasets from John Snow Labs AWS S3 and get them as dataframes.
!curl -O 'https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/resources/en/classifier-dl/toxic_comments/toxic_train.snappy.parquet'
!curl -O 'https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/resources/en/classifier-dl/toxic_comments/toxic_test.snappy.parquet'
trainDataset = spark.read.parquet("./toxic_train.snappy.parquet").repartition(120)
testDataset = spark.read.parquet("./toxic_test.snappy.parquet").repartition(10)
trainDataset.show(10, truncate = 100)

Training and test datasets include “text” and “labels” columns
This time, we use Bert Sentence Embeddings instead of Universal Sentence Encoder. Bert (Bidirectional Encoder Representations from Transformers) sentence embeddings are dense vector representations of sentences, or sequences of words, produced by pre-trained deep learning models such as the BERT model developed by Google.
# Step 1: Transforms raw texts to `document` annotation
document = DocumentAssembler()\
.setInputCol("text")\
.setOutputCol("document")\
.setCleanupMode("shrink")
# Step 2: Encodes text into high dimensional vectors
bert_sent = BertSentenceEmbeddings.pretrained('sent_small_bert_L8_512')\
.setInputCols(["document"])\
.setOutputCol("sentence_embeddings")
# Step 3: Performs multi-label text classifier training
multiClassifier = MultiClassifierDLApproach()\
.setInputCols("sentence_embeddings")\
.setOutputCol("category")\
.setLabelColumn("labels")\
.setBatchSize(128)\
.setMaxEpochs(5)\
.setLr(1e-3)\
.setThreshold(0.5)\
.setShufflePerEpoch(False)\
.setEnableOutputLogs(True)\
.setValidationSplit(0.1)
pipeline = Pipeline(stages = [document,
bert_sent,
multiClassifier])
# Fit the trainDataset for model training
pipelineModel = pipeline.fit(trainDataset)
Observe the increase in model’s accuracy during training — from 86.1 % to 88.5 %.
!cat ~/annotator_logs/{multiClassifier.uid}.log
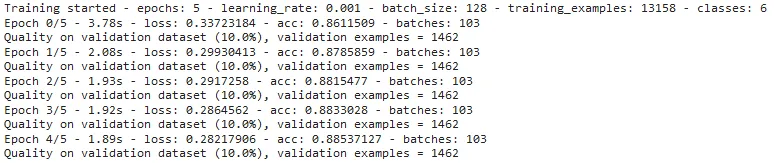
Change in the accuracy and loss values during every epoch
Now, let us use the trained model on the test dataset and observe its performance:
# Use the model to get predictions
preds = pipelineModel.transform(testDataset)
# Create a Pandas dataframe and see the first 10 rows
preds_df = preds.select('text','labels',"category.result").toPandas()
preds_df.head(10)
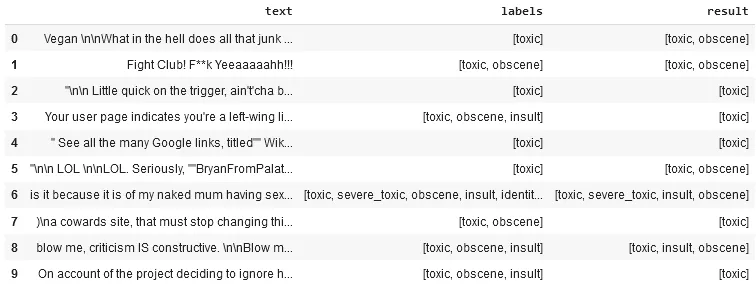
“labels” column show the original labels and “result” column displays the model’s predictions
This is another quick result; normally during model training, number of epochs is higher than 5 and the accuracy is expected to be much higher.
For additional information, please consult the following references.
- Documentation : MultiClassifierDL
- Python Docs : MultiClassifierDL
- Scala Docs : MultiClassifierDL
- For extended examples of usage, see the Spark NLP Workshop repository.
Conclusion
In this article, we tried to get you familiar with the basics of text classification. Text classification is an important task in fintech NLP and NLP in any other field that involves assigning predefined categories or labels to text documents based on their content. NLP for text classification can help make sense of large amounts of textual data, automate tasks, and improve the user experience in various applications.
Spark NLP provides alternative solutions to this problem and those are discussed in detail. There are references throughout the article and also please check the basic reference notebook.
Mastering text classification with tools like Spark NLP enables the effective application of Generative AI in Healthcare, enhancing the capabilities of a Healthcare Chatbot to provide more accurate and efficient patient support.