

























































The Model Ranking & Leaderboard system, powered by LangTest from John Snow Labs, provides a systematic approach to evaluating and comparing AI models. It offers comprehensive ranking capabilities, historical comparison, and dataset-specific insights, enabling researchers and data scientists to make informed, data-driven decisions about model performance across various applications and datasets.
With the ongoing introduction of new models and methodologies, determining which models provide the greatest performance for given applications and datasets gets more difficult. The Model Ranking & Leaderboard system, driven by LangTest (maintained by John Snow Labs), was created to solve this issue, providing a complete and systematic method for model evaluation.
This innovative system is designed to cater to the needs of researchers, data scientists, and AI enthusiasts who seek a reliable method to assess and compare different models. By providing a robust framework for ranking models based on various performance metrics, the Model Ranking & Leaderboard system with LangTest enables users to make informed decisions backed by data-driven insights.
The system’s key features include comprehensive ranking capabilities, historical comparison functionality, and dataset-specific insights, all of which contribute to a thorough understanding of model performance. Comprehensive ranking allows users to evaluate models across multiple datasets and performance metrics, ensuring a holistic view of each model’s capabilities. Historical comparison ensures that users can track performance trends over time, identifying patterns and improvements. Dataset-specific insights offer a deeper dive into how models perform on different datasets, highlighting strengths and weaknesses that may not be apparent in aggregate metrics.
In this blog post, we will delve into the functionality and benefits of the Model Ranking & Leaderboard system with LangTest. We will provide a step-by-step guide on how to set up and configure the system, run model evaluations, and visualize the leaderboard. By the end of this post, you will have a clear understanding of how to leverage this system to enhance your model evaluation processes and drive continuous improvement in your AI projects.
Whether you are working with models like GPT-4o and Phi-3-mini-4k-instruct-q4 or any other models, this comprehensive guide will equip you with the knowledge and tools needed to rank and compare model performance across various datasets effectively. The Model Ranking & Leaderboard system with LangTest is a crucial addition to any data scientist’s toolkit, providing the insights necessary to stay ahead in the competitive field of AI.
Ensuring Robust and Reproducible Benchmarking
- Comprehensive Evaluation:
The Model Ranking & Leaderboard system evaluates models using multiple performance metrics across diverse datasets. This comprehensive approach ensures that users understand each model’s strengths and weaknesses, which is essential for making informed decisions about model selection and deployment. - Historical Performance Tracking:
Tracking model performance over time is vital for understanding how models evolve and improve. The historical comparison feature allows users to retain and compare previous rankings, providing a longitudinal view of model performance. This enables the identification of trends and patterns, which can inform future development and optimization efforts. - Dataset-Specific Insights:
Different datasets pose unique challenges, and a model that excels on one dataset may not perform as well on another. The Model Ranking & Leaderboard system offers detailed, dataset-specific insights highlighting where models perform best and where they may need improvement. This granular analysis is crucial for refining models to meet the specific demands of different datasets.
Key Features in the Langtest:
The langtest is a powerful tool designed and developed by John Snow Labs to evaluate and enhance language models’ robustness, bias, representation, fairness, and accuracy. With just one line of code, users can generate and execute over 60 distinct types of tests, covering a comprehensive range of model quality aspects. The library supports automatic training data augmentation based on test results for select models and integrates seamlessly with popular NLP frameworks like Spark NLP, Hugging Face, and Transformers for tasks such as NER, translation, and text classification. Additionally, langtest supports testing large language models (LLMs) from OpenAI, Cohere, AI21, Hugging Face Inference API, and Azure-OpenAI, enabling thorough evaluations in areas like question answering, toxicity, clinical tests, legal support, factuality, sycophancy, summarization, and more.
How Comprehensive Ranking & Leaderboard System in LangTest Works:
The Model Ranking & Leaderboard feature, powered by LangTest, provides a structured process for evaluating and comparing models. Users can configure the system with their specific model parameters, datasets, and performance metrics, and then run evaluations to generate detailed reports and leaderboards. This process enables a clear and transparent comparison of model performance, facilitating continuous improvement and informed decision-making.
The following are steps to do model ranking and visualize the leaderboard for the ‘GPT-4o’ and ‘Phi-3-mini-4k-instruct-q4’ models.
- First, we need to configure the harness with the necessary parameters. This configuration will include the model parameters, tasks, and tests.
# config.yaml
model_parameters:
max_tokens: 64
device: 0
task: text2text-generation
tests:
defaults:
min_pass_rate: 0.65
robustness:
add_typo:
min_pass_rate: 0.7
lowercase:
min_pass_rate: 0.7
- Next, we initialize the harness with the task, model, datasets, and benchmarking configuration.
from langtest import Harness
harness = Harness(
task="question-answering",
model={
"model": "gpt-4o",
"hub": "openai"
},
data=[
{
"data_source": "MedMCQA"
},
{
"data_source": "PubMedQA"
},
{
"data_source": "MMLU"
},
{
"data_source": "MedQA"
}
],
config="config.yml",
benchmarking={
"save_dir": "~/.langtest/leaderboard/" # required for benchmarking
}
)
- Once the harness is set up, generate the test cases, run the model, and get the report.
harness.generate().run().report()
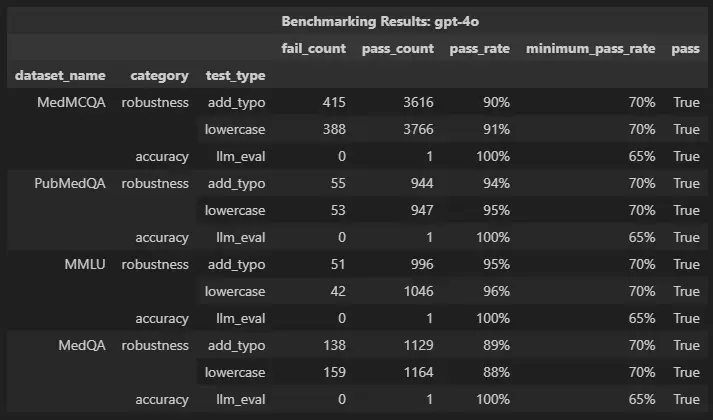
harness report for the GPT-4o model
- Similarly, follow the same steps for the ‘Phi-3-mini-4k-instruct-q4’ model with the same ‘save_dir’ path for benchmarking and the same ‘config.yaml’.
- Finally, visualize the model rankings by calling the following code.
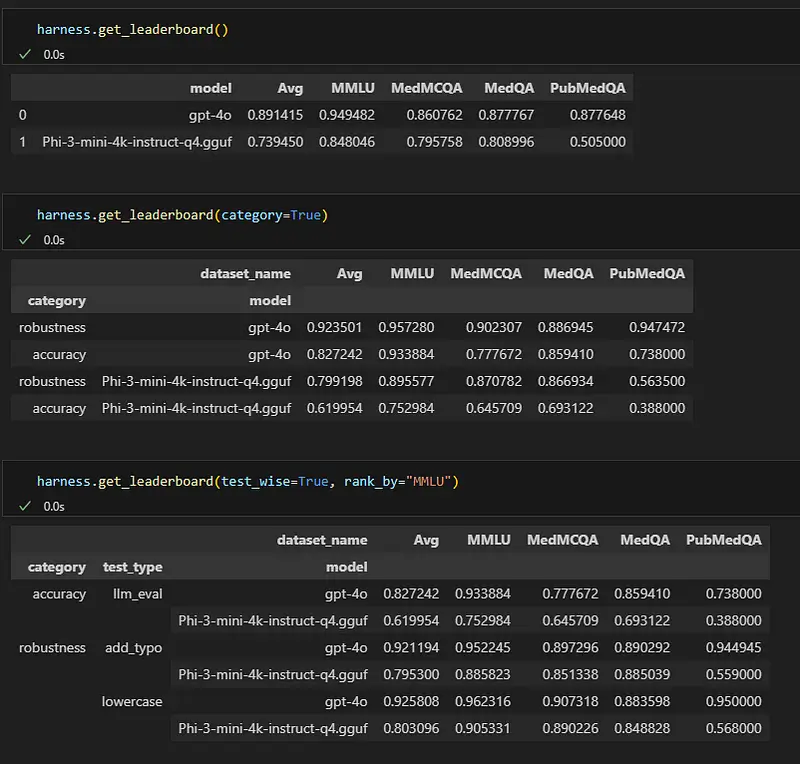
harness.get_leaderboard()
Conclusion
The Model Ranking & Leaderboard system, powered by LangTest, offers a robust and structured approach to evaluating and comparing model performance across various datasets and metrics. By utilizing this system, users can obtain a comprehensive view of model capabilities, enabling them to make data-driven decisions with confidence.
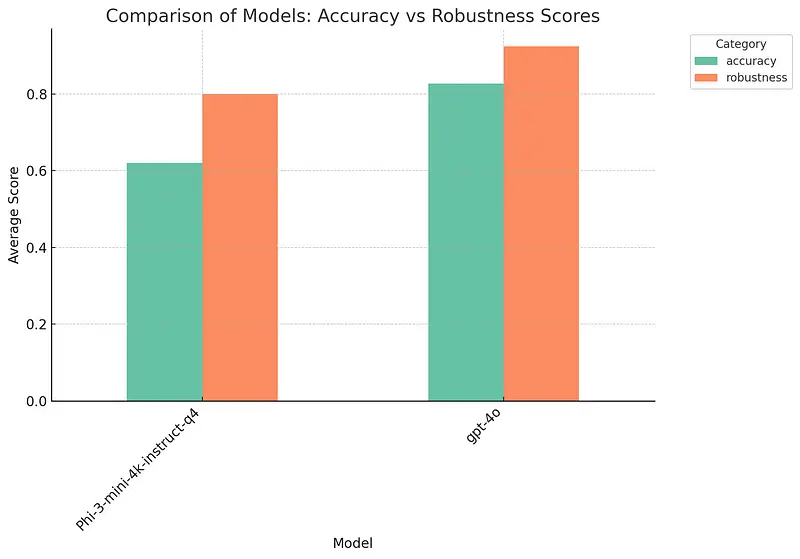
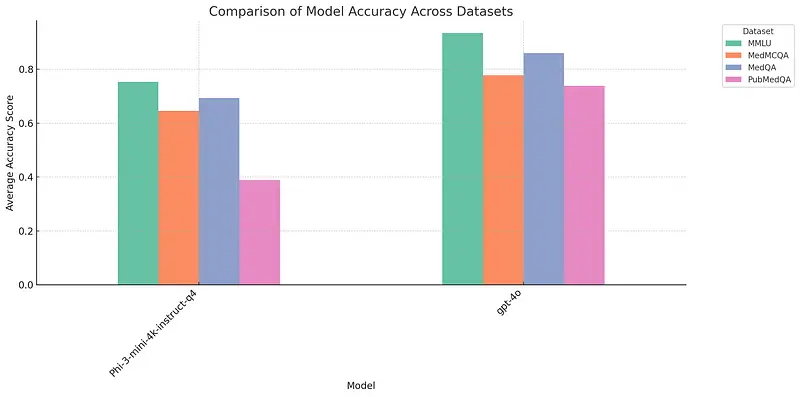
The images provided showcase the effectiveness of the Model Ranking & Leaderboard system in action. Specifically, the leaderboard demonstrates how models such as ‘GPT-4o’ and ‘Phi-3-mini-4k-instruct-q4’ can be evaluated across multiple datasets including MMLU, MedMCQA, MedQA, and PubMedQA. This highlights the system’s flexibility and versatility, as it allows for the comparison of any model from various hubs, with ‘GPT-4o’ and ‘Phi3’ serving as prime examples. Key insights from the leaderboard include:
- Comprehensive Ranking: The overall ranking shows that ‘GPT-4o’ outperforms ‘Phi-3-mini-4k-instruct-q4’ across various datasets with an average score of 0.891415 compared to 0.739450.
- Category-Specific Insights: When categorized by robustness, ‘GPT-4o’ consistently performs better across all datasets.
- Test-Wise Analysis: The detailed breakdown of test types, such as ‘add_typo’ and ‘lowercase,’ reveals that ‘GPT-4o’ maintains higher performance scores in robustness tests than ‘Phi-3-mini-4k-instruct-q4’.
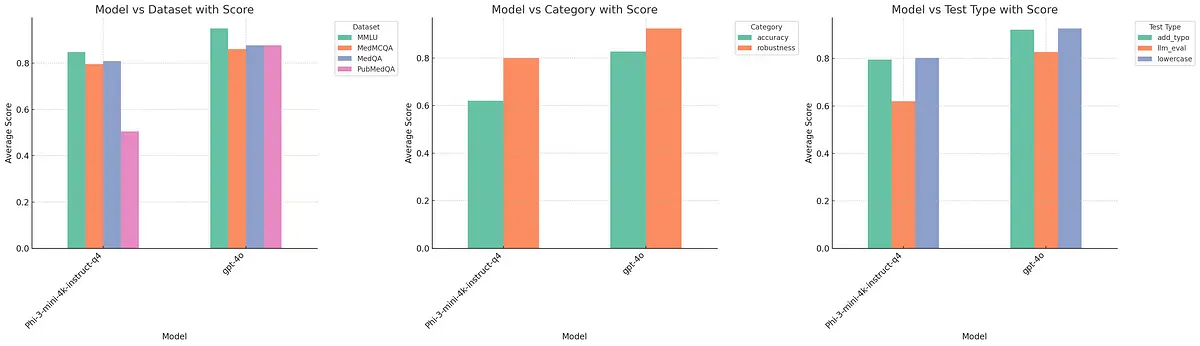
Average scores
These detailed visualizations and comparisons highlight the Model Ranking & Leaderboard system’s capability to provide granular insights into model performance. Users can see the overall performance and delve into specific categories and test types to identify strengths and areas for improvement.
Incorporating the Model Ranking & Leaderboard system into your workflow will empower you to identify the best-performing models, track their progress over time, and optimize them for various datasets. As you continue to explore and innovate in AI, this system will be an invaluable resource, helping you achieve your goals and maintain a competitive edge.
By leveraging the power of LangTest, the Model Ranking & Leaderboard system sets a new standard for model evaluation, ensuring that you have the insights and tools necessary to excel in your AI endeavors.
For more updates and community support, join our Slack channel and give a star to our GitHub repo here.
References:
- Nazir, Arshaan, Thadaka K. Chakravarthy, David A. Cecchini, Rakshit Khajuria, Prikshit Sharma, Ali T. Mirik, Veysel Kocaman, and David Talby. “LangTest: A Comprehensive Evaluation Library for Custom LLM and NLP Models.” Software Impacts 19, (2024): 100619. Accessed July 4, 2024. https://www.softwareimpacts.com/article/S2665-9638(24)00007-1/fulltext
- David Cecchini, Arshaan Nazir, Kalyan Chakravarthy, and Veysel Kocaman. 2024. Holistic Evaluation of Large Language Models: Assessing Robustness, Accuracy, and Toxicity for Real-World Applications. In Proceedings of the 4th Workshop on Trustworthy Natural Language Processing (TrustNLP 2024), pages 109–117, Mexico City, Mexico. Association for Computational Linguistics.
- Benchmark Datasets supported by LangTest
- Check out the Langtest website





