

























































Version 1.20.0 of the library comes with optimized sentence embedding models for RAG applications in the Legal domain and new demo apps for Subpoenas.
Sentence Embedding Models
The new sentence embedding model expands the capabilities of the library for Retrieval Augmented Generation (RAG) applications, and the capability to train text classification models. E5 and BGE models obtain top performances on standard NLP benchmarks, and we provide a Legal-specific fine-tuned version.
To use the model on a Spark NLP pipeline, simply download the pretrained model:
document_assembler = (
nlp.DocumentAssembler().setInputCol("text").setOutputCol("document")
)
E5_embedding = (
nlp.E5Embeddings.pretrained(
"legembedding_e5_base", "en", "legal/models"
)
.setInputCols(["document"])
.setOutputCol("E5")
)
pipeline = nlp.Pipeline(stages=[document_assembler, E5_embedding])
Then, we can transform texts into vector representations with:
data = spark.createDataFrame(
[["Receiving Party shall not use any Confidential Information for any purpose other than the purposes stated in Agreement."]]
).toDF("text")
result = pipeline.fit(data).transform(data)
We can then obtain the vector arrays with:
result.select("E5.embeddings").show(truncate=100)
Obtaining:
+----------------------------------------------------------------------------------------------------+ | embeddings| +----------------------------------------------------------------------------------------------------+ |[0.023808457, 0.38471168, 0.43703818, 0.6033733, -0.40925637, -0.78775537, -0.329775, -0.028943084, -0.08633131, ...| +----------------------------------------------------------------------------------------------------+
The vector representation of the texts can easily be used on VectorDBs to implement RAG systems on domain-specific applications. Reach out to us if you want to use the capabilities of Spark and Legal NLP to enhance your RAG application on legal documents.
New demo apps for Subpoena analysis
A subpoena is a formal document issued by a court, grand jury, legislative body or committee, or authorized administrative agency. It commands an individual to appear at a specific time and provide testimony, either orally or in writing, regarding the matter specified in the document.
We released two new demo apps to identify subpoena entities and section classification, showing examples using the latest models of the library.
Identifying relevant Entities in Subpoena
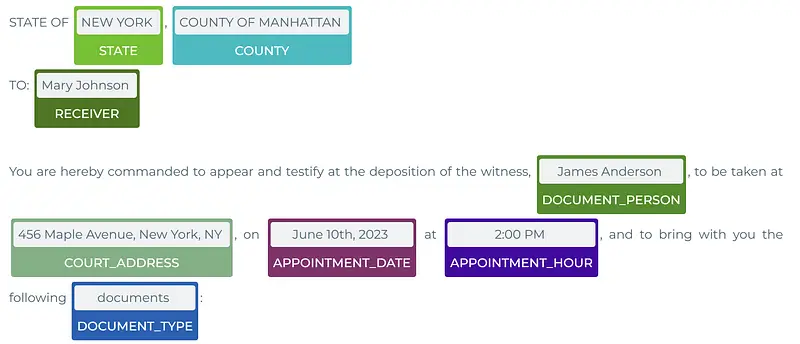
Link to the demo app: here.
The demo illustrates how to use pretrained models to identify relevant information on subpoena texts. The existing entities are:
- ADDRESS
- MATTER_VS
- APPOINTMENT_HOUR
- DOCUMENT_TOPIC
- DOCUMENT_PERSON
- COURT_ADDRESS
- APPOINTMENT_DATE
- COUNTY
- CASE
- SIGNER
- COURT
- DOCUMENT_DATE_TO
- DOCUMENT_TYPE
- STATE
- DOCUMENT_DATE_FROM
- RECEIVER
- MATTER
- SUBPOENA_DATE
- DOCUMENT_DATE_YEAR
Classifying Subpoena sections

Link to the demo app: here.
This demo shows the capabilities of our pretrained model to classify sections of the subpoena into a specific category. Available categories are:
- ATTACHMENT
- INSTRUCTION
- ARGUMENT
- DEFINITION
- REQUEST_FOR_ISSUANCE_OF_SUBPOENA
- NOTIFICATION
- DOCUMENT_REQUEST
- PRELIMINARY_STATEMENT
- CERTIFICATE_OF_SERVICE
- STATEMENT_OF_FACTS
- CONCLUSION
- BACKGROUND
- CERTIFICATE_OF_FILING
- INTRODUCTION
- DECLARATION
Our library can expand and customize NER and Classification models for specific use cases. If you have specific needs, contact us!
Fancy trying?
We’ve got 30-day free licenses for you with technical support from our legal team of technical and SMEs. This trial includes complete access to more than 926 models, including Classification, NER, Relation Extraction, Similarity Search, Summarization, Sentiment Analysis, Question Answering, etc. and 120+ legal language models.
Just go to https://www.johnsnowlabs.com/install/ and follow the instructions!
Don’t forget to check our notebooks and demos.
How to run
Legal NLP is extremely easy to run on both clusters and driver-only environments using johnsnowlabs library:
Install the johnsnowlabs library:
pip install johnsnowlabs
Then, in Python, install Legal NLP with:
from johnsnowlabs import nlp nlp.install(force_browser=True)
You are ready to use all the capabilities of the library. You can start a spar session and start analyzing legal texts.
# Start Spark Session spark = nlp.start()
For alternative installation methods of how to install in specific environments, please check the docs.




