We are happy to announce the first release of 2023 – Legal NLP 1.5.0!
Legal NLP is a John Snow Lab’s product, launched 2022 to provide state-of-the-art, autoscalable, domain-specific NLP on top of Spark.
With more than 500 models, featuring Deep Learning and Transformer-based architectures, Legal NLP 1.5.0 includes:
- Annotators to carry out Name Entity Recognition, Relation Extraction, Assertion Status / Understanding Entities in Context, Data Mapping to external sources, Deidentification, Question Answering, Table Question Answering, Sentiment Analysis, Summarization and much more, both training and inference!
- Zero-shot Name Entity Recognition and Relation extraction;
More than 580 pretrained Deep Learning / Transformer-based models;
- Full integration with Databricks, AWS or Azure;
- A bunch of notebooks and demos ready to showcase its features.
- Full integration with NLP Lab (former Annotation Labs) for managing your annotation projects and train your legal models in a zero-code fashion.
- Compatiblity with Visual NLP, to combine OCR/Visual capabilities, as Signature Extraction, Form Recognition or Table detection, to Legal NLP.
More than 20 notebooks in Legal NLP 1.5.0
We have updated and improved our more than 20 Legal NLP notebooks, available. Our Certification training is happening Jan, 2023, where we will be taking a look at all of them and testing some of the features of NLP for Legal documents.
# Legal NLP notebooks
## Splitting, Tokenization, Embeddings
[1.Page_Splitting.ipynb]
[2.Sentence_Splitting_Tokenization.ipynb]
[3.Word_Sentence_Embeddings.ipynb]
## Classification
[4.0.Clause_Document_Classification.ipynb]
[4.1.Training_Legal_Classifiers.ipynb]
## Named Entity Recognition
[5.0.NER_and_ZeroShotNER.ipynb]
[5.1.Training_Legal_NER.ipynb]
[5.2.Clause_based_NER.ipynb]
[5.3.ZeroShot_Legal_NER.ipynb]
## Relation Extraction
[6.0.Relation_Extraction.ipynb]
[6.1.Relation_Extraction_and_ZeroShotRE.ipynb]
[6.2.Relation_Extraction_Training.ipynb]
## Assertion Status: Understanding Entities in Context
[7.0.Understand_Entities_in_Context.ipynb]
[7.1.Training_Legal_Assertion.ipynb]
## Question&Answering
[8.0.Answering_Questions_Legal_Texts.ipynb]
[8.1.Automatic_Question_Generation_Legal_Texts.ipynb]
[8.2.NER_using_Question_Answering.ipynb]
##
## Normalization and Entity Linking
[9.0.Normalization_with_Entity_Resolution_Edgar.ipynb]
[9.1.Entity_Resolution_Edgar_unique_IDs.ipynb]
[9.2.Entity_Resolution_Training.ipynb]
## Augmentation with external sources with Chunk Mappers
[10.0.Data_Augmentation_with_ChunkMappers.ipynb]
[10.1.Chunk_Mappers_Training.ipynb]
## Deidentification
[11.Deidentification.ipynb]
## Coreference Resolution
[12.Coreference_Resolution.ipynb]
## Graphs
[80.0.WIP_Use_Case_Legal_Agreements.ipynb]
[80.1.Legal_Graphs_Neo4j.ipynb]
## Combining with Visual NLP
[90.0.Legal_Visual_Document_Understanding.ipynb]
[90.1.Layout_Classification_with_VisualNLP.ipynb]

2 new Assertion Status models to Understand Entities in Context
- Negation Detection comes to Legal NLP. Use
legassertion_negationtounderstand if an entity, extracted with NER, is negated in the context or not - Time Assertion gets an improvement with a new round of training and new data:
legassertion_time_md
Data Augmentation models updated in Legal NLP 1.5.0
Our offline-accessible Entity Resolvers (legel_edgar_company_name,legel_edgar_irs)and Chunk Mappers (legmapper_edgar_companyname,legmapper_edgar_irs)for US Sec’s Edgar database have been updated with the information of the last quarter of 2022. Let’s remember what they are useful for:
- Entity Resolvers allow you to normalize strings to an official version or an unique identified from an exernal data source. This is very useful when you try to query a data source, as Edgar, with the name of a company you have extracted with NER. The problem arises with the high variations of the company names you can get in your documents. With Entity Resolution, no matters what you get as ORG NER (g., Cadence, Cadence INC, Cadence Inc., Cadence Incorporated…) all of them will be normalized to Edgar’s official Cadence Inc. and its unique ID (IRS) inEdgar.
- Chunk Mappers allow you to use a normalized string (as the normalized company name using Edgar Entity Resolver) to retrieve information from data sources we make available for you on-premises/offline. For example, by using Edgar Chunk Mappersa Candence ORG, you can obtain information as:

New NER models in Legal NLP 1.5.0
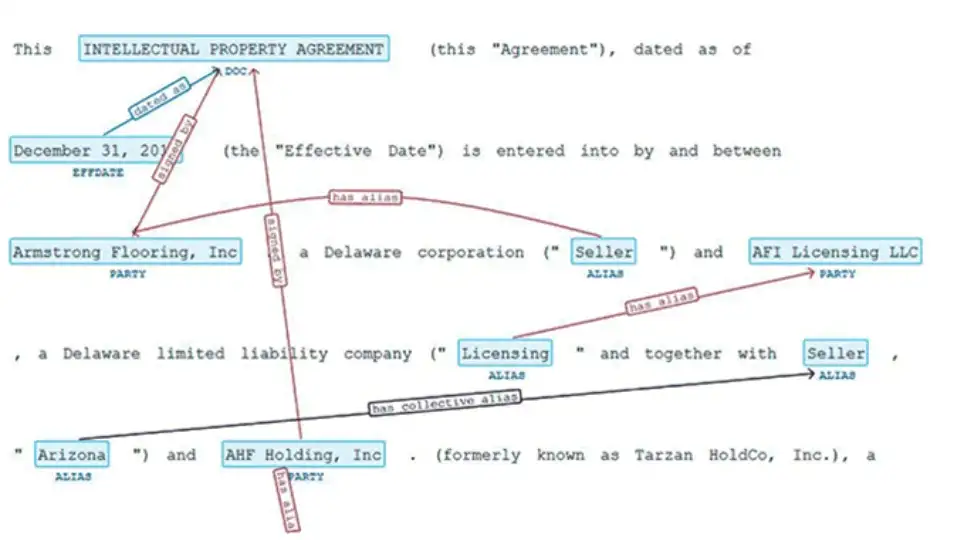
legner_roles: NER model trained to detect roles of parties in agreements. For example: Borrower, Supplier, Lender, Attorney, Provider, etc.
legner_org_per_role_date: Retrieves Organizations, People names, Job Titles and Dates from legal agreements;
How to run
Legal NLP is very easy to run on both clusters and driver-only environments using johnsnowlabs NLP library:
!pip install johnsnowlabs
nlp.install(force_browser=True) nlp.start()
Fancy trying?
We’ve got 30-days free licenses for you with technical support from our financial team of technical and SME. Just go to https://www.johnsnowlabs.com/install/ and follow the instructions!