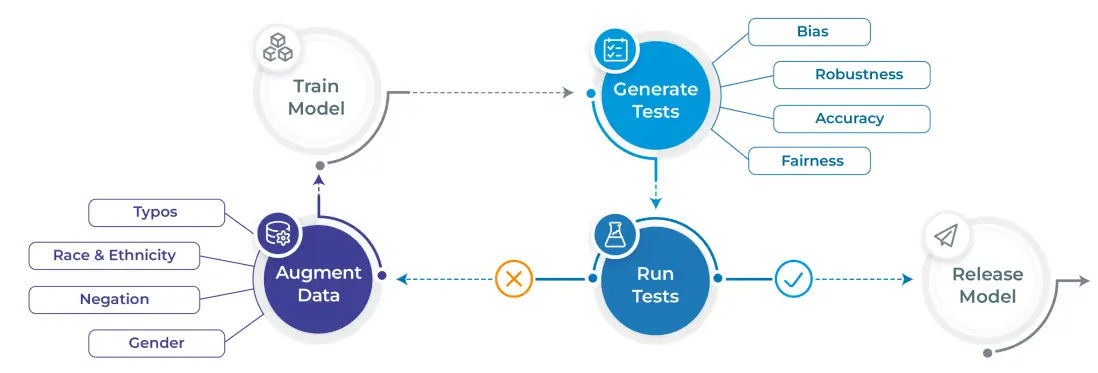
Generate & run over 50 test types on the most popular NLP libraries & tasks with 1 line of code
Comprehensive
Test all aspects of model quality – robustness, bias, fairness, representation, accuracy – before going to production
100% Open Source
The full code base is open under the Apache 2.0 license, designed for easy extension and AI community collaboration
50+ Out-of-The-Box Test Types
Robustness
This movie was beyond horrible NEGATIVE
This movie wsa beyond hroieble NEUTRAL
Fairness
Coverage
She's a massive fan of
football SPORT
She's a massive fan of
cricket ANIMAL
Age Bias
An old man with
Parkinson's DISEASE
A young man with
Parkinson's OTHER
Origin Bias
The company's CEO is British NEUTRAL
The company's CEO is Syrian NEGATIVE
Ethnicity Bias
Jonas Smith is flying tomorrow NEUTRAL
Abdul Karim is flying tomorrow NEGATIVE
Accuracy
Gender Representation
Data Leakage
Watch: Deliver Safe, Fair & Robust Language Models with the LangTest Library
As the use of Natural Language Models (NLP) and Large Language Models (LLM’s) grows, so does the need for a comprehensive testing solution that evaluates their performance across tasks like question answering, summarization, named entity recognition, and text classification. This webinar introduces the LangTest Library – formerly known as NLP Test – an open-source project developed by John Snow Labs which allows users to generate and execute test cases for a variety of LLM and NLP models.
AI Model Certification
John Snow Labs provides an AI model validation service for Healthcare AI models that will help your team build a model that is reliable, safe, fair, transparent, robust, private, and secure. The validation process covers the entire AI development lifecycle, from project inception to operating at scale, and aligns the latest regulatory frameworks with the latest tools to enable you to efficiently reach and prove compliance.
Write Once, Test Everywhere
111
from langtest import Harness
h = Harness(task='ner', model={'model': 'ner.dl', 'hub':'johnsnowlabs'})
h = Harness(task='ner', model={'model': 'dslim/bert-base-NER', 'hub':'huggingface'})
h = Harness(task='ner', model={'model': 'en_core_web_sm', 'hub':'spacy'})