

























































In a previous blog post, we compared John Snow Labs Medical Chatbot and ChatGPT-4 in Biomedical Question Answering. The blind test with independent medical annotators showed how the proprietary Healthcare-GPT Large Language Model outperformed ChatGPT-4 in medical correctness, explainability, and completeness.
Another use case popular among Healthcare professionals is Clinical Question Answering – it can potentially improve clinical care quality and patient outcomes. This blog post explores how John Snow Labs and ChatGPT-4 compare in addressing real-world clinical questions, based on completeness, writing style, and clinical correctness and explainability.
Biomedical Questions Answering vs Clinical Practice Question Answering: Why a New Benchmark?
The Generative AI In Healthcare 2024 Survey highlighted that the most popular use cases among practitioners were:
- Answering Patient Questions (31%)
- Information Extraction (31%)
- Biomedical Research (29%)
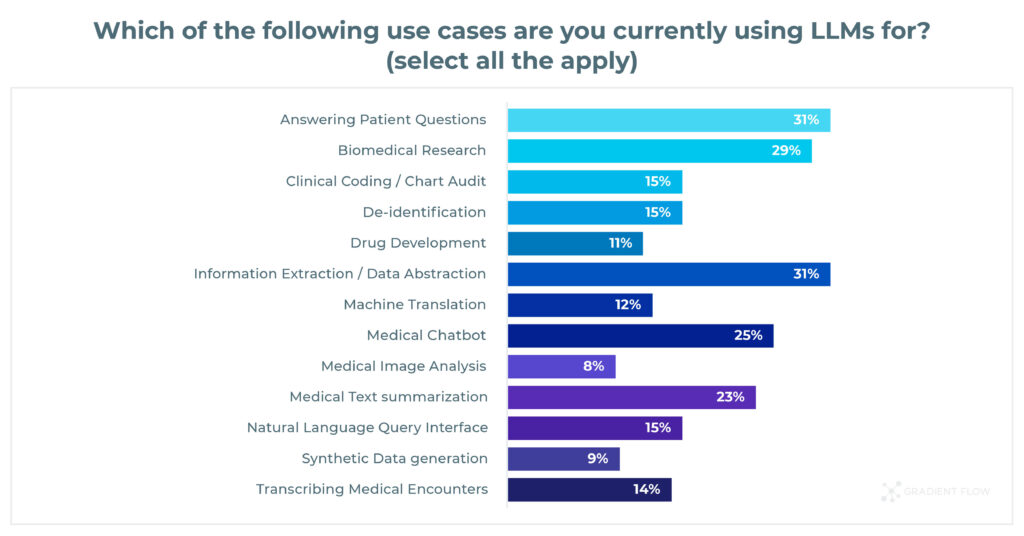
Clinical Practice and Biomedical Research are in the top 3 use cases among Healthcare professionals, yet they need distinct benchmarks for a fair evaluation:
- Clinicians have a goal of providing direct patient care, while biomedical research seeks to advance scientific knowledge;
- Clinical practice requires using established medical knowledge and protocols, while researchers rely on scientific methods like experimentation;
- Clinicians are looking for immediate and practical benefits, while biomedical research has a long-term focus and impacts broader populations rather than individual patients.
Another critical testing aspect was how Healthcare LLMs are somewhat ‘tainted’ by public benchmarks:
- Public benchmarks may not capture the diversity and complexity of real-world healthcare data, lacking comprehensive task representation;
- Standard metrics may not reflect clinical relevance or safety needs, with benchmarks often overlooking crucial healthcare metrics like patient outcomes and diagnostic accuracy;
- Models fine-tuned to benchmarks may fail to generalize to real-world clinical data, lacking domain-specific knowledge essential for healthcare applications;
- Public benchmarks avoid sensitive personal health information due to privacy regulations, missing ethical considerations vital for healthcare applications;
- Real-world healthcare requires contextual understanding and interdisciplinary collaboration, which benchmarks do not adequately simulate.
Benchmarking Accuracy: A Randomized Blind Test, Evaluated by Medical Doctors
To create a fair test environment, we invited independent medical doctors to write questions that come up often in their specialty. Examples of such questions are:
- What is the pharmacological treatment of asthma-chronic obstructive pulmonary disease overlap syndrome (ACOS)?
- What are the genetic factors linked to rapidly destructive hip osteoarthritis?
- Are there any contraindications that might make someone ineligible for bronchoscopy?
- How does chronic kidney disease impact oral health?
- Does Tisotumab vedotin show durable antitumor activity in women with previously treated recurrent or metastatic cervical cancer?
We then used Medical Chatbot and GPT-4 to generate responses, which medical annotators subsequently reviewed in a blind test consisting of 14 questions. The evaluation focused on Writing Style, Correctness, and Completeness.
The ideal responses should address the question in the opening sentence and provide pertinent details afterward. We aim for a text that is easy to read, grammatically sound, and conveys an empathetic tone—an essential aspect when communicating in clinical settings with patients. To assess Writing Style, we sought input from practitioners:
Read the answer. Is it:
- Given in the first sentence?
- Then adds relevant detail?
- Grammatically correct & easy to read?
- Uses an empathic tone of voice?
Hallucinations, where false or misleading information is presented as fact, are a frequent issue with GPTs. We must ensure that responses, particularly to medical prompts, do not include any plausible-sounding but incorrect information. To assess Correctness, we asked:
Review the answer medically. Is it:
- Free from hallucinations?
- Medically correct & current?
- Conforms to medical consensus?
- Are the references correct?
- Are the references believable?
Lastly, we seek responses supported by recent meta-analyses that can stand alongside high-impact articles and papers. To evaluate Completeness, we asked:
Do your own research. Can you find:
- More recent papers or content, that provide a better answer?
- A more recent meta-analysis on this?
- A higher impact journal article?
- A paper with a better trial design?
- Indications that the paper was retracted or corrected?
The Results: Comparing Writing Style, Correctness, and Completeness
A randomized blind test with medical doctors showed that a system specifically tuned for medical content, like Medical Chatbot, outperforms ChatGPT-4 in terms of writing style, medical correctness, explainability, and completeness:
- Healthcare-GPT got 91% versus GPT-4 at 43% on Correctness & Explainability:
- Healthcare-GPT scored 91% versus GPT-4 at 66% on Completeness & Freshness.
- Healthcare-GPT achieved 81% versus GPT-4 at 72% on Writing Style
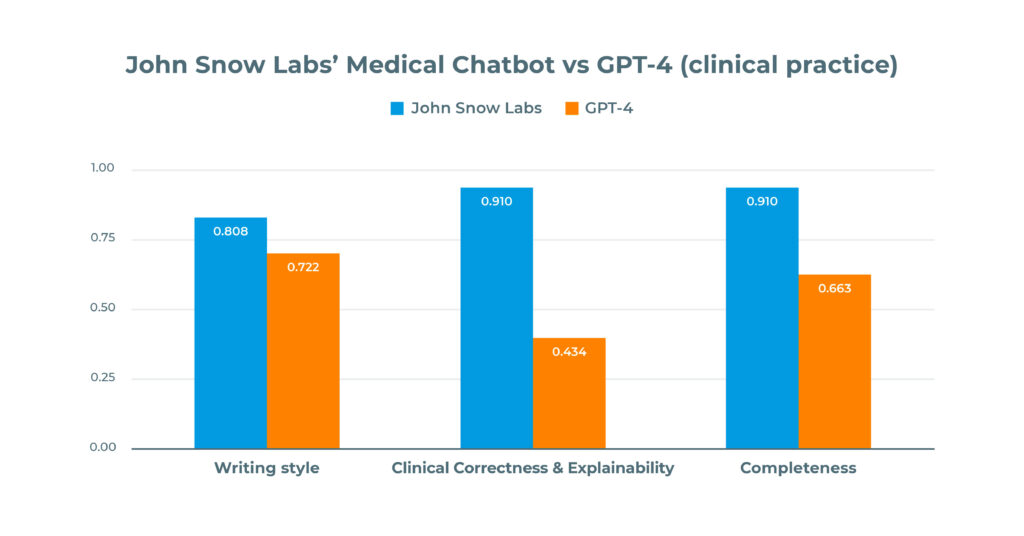
A subset of the questions from the test will be made public to enable reproducibility.
What makes Medical Chatbot an optimal solution for Clinical Practice?
Medical Chatbot by John Snow Labs goes beyond simply providing answers—it explains them with references and exact citations, enabling you to verify, explore, and delve deeper into the information. With daily updates on clinical insights, terminologies, and datasets, you always have access to the most current medical knowledge. Why is Medical Chatbot the ideal choice for healthcare practitioners?
- Ensures superior accuracy for healthcare-specific tasks
- Operates privately behind your firewall with no third-party APIs or data sharing
- Updates medical knowledge daily
- Consistently reproduces results
- Avoids hallucinations by citing its sources
- Provides detailed explanations for its answers
- Integrates private knowledge bases
- Offers tunable guardrails and brand voice customization
Try Medical Chatbot today by signing up for a 7-day trial with full access to features. Join the community of Healthcare professionals and enjoy regular new feature updates as we optimize the chatbot for literature reviews, summarization, real-world data analysis, and more.





