Choosing the right Large Language Model (LLM) for biomedical question answering can spell the difference between accurate and actionable answers to unreliable information, hindering patient outcomes. However, with several chatbots on the market, selecting the best one can feel daunting. John Snow Labs’ Medical Chatbot and GPT-4 in biomedical question answering are two popular options for Healthcare practitioners looking to address real-world questions. There are critical ways these two products differ, specifically in writing style, clinical correctness and explainability, and completeness.
This blog post will dive deeper into comparing the two so you can better understand the differences between the platforms and assess the right one for you.
Biomedical Question Answering – What Do Healthcare Practitioners Value Most
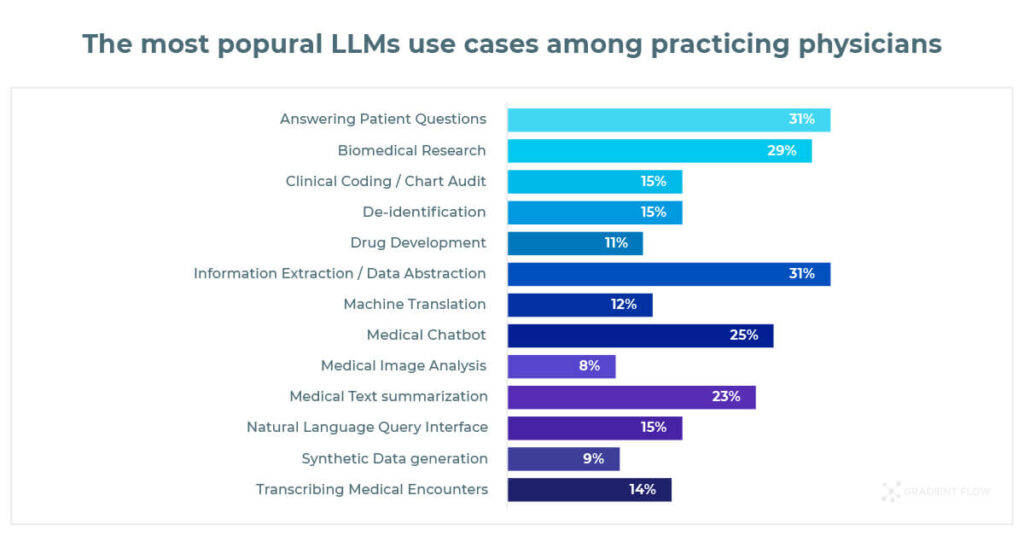
Before we compared Medical Chatbot with Chat GPT-4, we turned to the Healthcare professionals for insight into what they care about the most in LLMs. The Generative AI In Healthcare 2024 Survey highlighted that the most popular use cases among practitioners were:
- Answering Patient Questions (31%)
- Information Extraction (31%)
- Biomedical Research (29%)
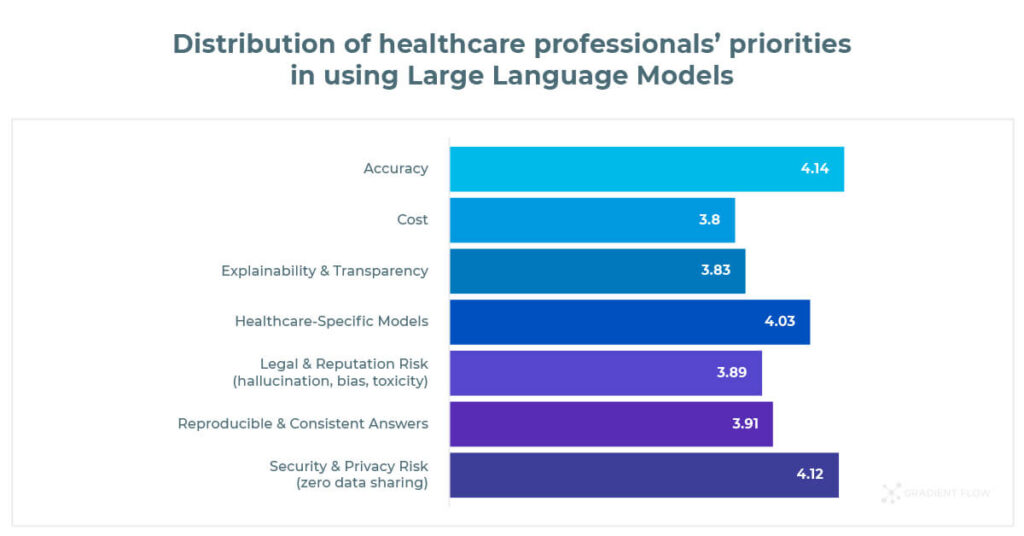
When practitioners evaluate Medical Large Language Models, they prioritize Accuracy, followed by Security & Privacy Risk and Healthcare-specific Models.
Finally, Healthcare-specific, “small” models built for a particular task, are the most popular among Enterprise companies, followed by open-source LLMs.

Benchmarking Accuracy: A Randomized Blind Test, Evaluated by Medical Doctors
After gaining valuable feedback from the industry in the Generative AI for Healthcare 2024 survey, we started our evaluation of Medical Chatbot vs Chat GPT-4. The test took place from January until March of 2024.
First, we picked questions from PubMedQA – a dataset designed specifically for Biomedical Research Question Answering. The final list had a combination of open-ended questions:
- What was the median progression-free survival rate for lenvatinib with transarterial chemoembolization?
- What is the mortality rate from EGDS?
- Is the risk of recurrent laryngeal nerve injury higher in mediastinoscopy-assisted esophagectomy?
- What are the latest developments in reconstructive surgery following facial trauma?
- Is there evidence to support the use of triptans in people with acute cluster headaches?
- What are the possible causative genes of myoclonic-astatic epilepsy?
Then, we generated answers using Medical Chatbot and GPT-4. We handed the answers to medical annotators for a blind 14-question test to evaluate Writing Style, Correctness and Completeness.
The best responses answer the question in the first sentence and provide relevant details later. We expect an easy-to-read text that is grammatically correct and uses an empathetic tone of voice – a feature particularly relevant for Healthcare. To test Writing Style, we asked practitioners:
Read the answer. Is it:
- Given in the first sentence?
- Then adds relevant detail?
- Grammatically correct & easy to read?
- Uses an empathic tone of voice?
Hallucinations are among the most common plagues of GPTs when false or misleading information appears as a fact. We want to ensure the responses are free from plausible-sounding random information, especially in medical prompts. To test Correctness, we asked:
Review the answer medically. Is it:
- Free from hallucinations?
- Medically correct & current?
- Conforms to medical consensus?
- Are the references correct?
- Are the references believable?
Finally, we’re looking for an answer backed by a recent meta-analysis that can compete with the high-impact articles and papers. To test Completeness, we asked:
Do your own research. Can you find:
- More recent papers or content, that provide a better answer?
- A more recent meta-analysis on this?
- A higher impact journal article?
- A paper with a better trial design?
- Indications that the paper was retracted or corrected?
The Results: Comparing Writing Style, Correctness, and Completeness
After a blind test with medical annotators, the results showed that a system tuned for medical content like Medical Chatbot outperforms ChatGPT-4 in medical correctness, explainability, and completeness.
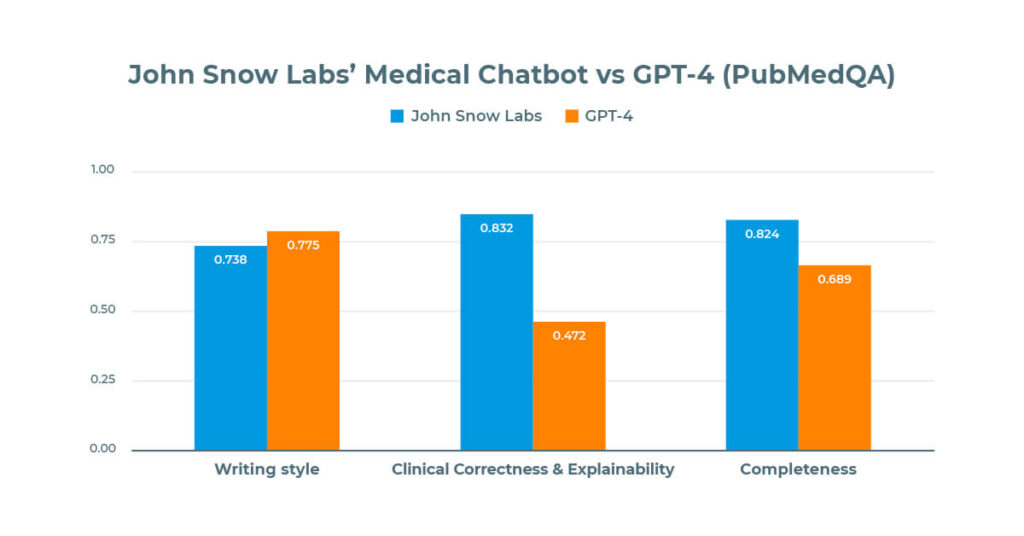
ChatGPT-4 scored slightly higher (77%) on the Writing Style than Medical Chatbot (73%), based on a randomized blind test with Healthcare professionals.
However, John Snow Labs demonstrated a higher Completeness score (82%) than ChatGPT-4 (0.689) and almost double the score on Clinical Correctness and Explainability (83%) compared to ChatGPT-4 (74%).
John Snow Labs vs. GPT-4 in Biomedical Question Answering: Differences in Clinical Correctness and Explainability
Because Correctness is the main priority for Healthcare professionals we broke it down into two sections – Medical Correctness and Reference Correctness.

To evaluate Medical Correctness, we asked if the generated response was:
- Free from hallucinations?
- Medically correct & current?
- Conforms to medical consensus?
Medical Chatbot got 87% versus ChatGPT-4 at 62% on Medical Correctness.
To evaluate Reference correctness, we asked:
- Are the references correct?
- Are the references believable?
Medical Chatbot scored 78% versus ChatGPT-4 at 24% on Reference Correctness.
The blind test showed how the proprietary Healthcare-GPT Large Language Model is tuned to understand and engage in medical conversations with unparalleled accuracy.
What Else Makes Medical Chatbot a Better Choice for Biomedical Researchers?
Medical Chatbot by John Snow Labs doesn’t just give answers – it explains them by providing references and citing exact sources, allowing you to verify better, explore, and dive deeper. With daily updates on biomedical research, terminologies and datasets, you’re always working with the latest medical knowledge. What makes Medical Chatbot the right choice for Healthcare practitioners?
- Delivers Superior Accuracy for Healthcare-Specific Tasks
- Runs privately behind your firewall: No third-party APIs or data sharing
- Updates all medical knowledge daily
- Can consistently reproduce results
- Does not hallucinate, cites its sources
- Explains its answers
- Adds private knowledge bases
- Tunable guardrails and brand voice
Try Medical Chatbot today – sign up for a 7-day trial with full access to features. Join the community of Healthcare professionals and expect a steady stream of new features regularly as we optimize the chat for literature reviews, summarization, real-world data analysis, and much more.