
























































We are incredibly excited to release NLU 1.1! This release integrates the 720+ new models from the latest Spark-NLP 2.7 + releases.
You can now achieve state-of-the-art results with Sequence2Sequence transformers on problems like text summarization, question answering, translation between 192+ languages, and extract Named Entity in various Right to Left written languages like Arabic, Persian, Urdu, and languages that require segmentation like Koreas, Japanese, Chinese, and many more in 1 line of code! These new features are possible because of the integration of Google’s T5 models and Microsoft’s Marian models transformers.
NLU 1.1 has over 720+ new pertained models and pipelines while extending the support of multi-lingual models to 192+ languages such as Chinese, Japanese, Korean, Arabic, Persian, Urdu, and Hebrew.
In addition to this, NLU 1.1 comes with 9 new notebooks showcasing training classifiers for various review and sentiment datasets and 7 notebooks for the new features and models.
NLU 1.1 New Features
- 720+ new models, you can find an overview of all NLU models here and further documentation in the models’ hub
- NEW: Introducing MarianTransformer annotator for machine translation based on MarianNMT models. Marian is an efficient, free Neural Machine Translation framework mainly being developed by the Microsoft Translator team (646+ pertained models & pipelines in 192+ languages)
- NEW: Introducing T5Transformer annotator for Text-To-Text Transfer Transformer (Google T5) models to achieve state-of-the-art results on multiple NLP tasks such as Translation, Summarization, Question Answering, Sentence Similarity, and so on
- NEW: Introducing brand new and refactored language detection and identification models. The new LanguageDetectorDL is faster, more accurate, and supports up to 375 languages
- NEW: Introducing WordSegmenter model for word segmentation of languages without any rule-based tokenization such as Chinese, Japanese, or Korean
- NEW: Introducing DocumentNormalizer component for cleaning content from HTML or XML documents, applying either data cleansing using an arbitrary number of custom regular expressions either data extraction following the different parameters
Translation
Translation example
You can translate between more than 192 Language pairs with the Marian Models. You need to specify the language your data is in as start_language and the language you want to translate to as target_language. The language references must be ISO language codes
nlu.load('<start_language>.translate.<target_language>')
Translate English to French:

Translate English to Inuktitut:

Translate English to Hungarian :

Translate English to German :

Translate English to Welch
Overview of every task available with T5
The T5 model is trained on various datasets for 17 different tasks which fall into 8 categories.
- Text summarization
- Question answering
- Translation
- Sentiment analysis
- Natural Language inference
- Coreference resolution
- Sentence Completion
- Word sense disambiguation
Every T5 Task with explanation:
| Task Name | Explanation |
|---|---|
| 1.CoLA | Classify if a sentence is grammatically correct |
| 2.RTE | Classify whether a statement can be deducted from a sentence |
| 3.MNLI | Classify for a hypothesis and premise whether they contradict or imply each other or neither of both (3 class). |
| 4.MRPC | Classify whether a pair of sentences is a rephrasing of each other (semantically equivalent) |
| 5.QNLI | Classify whether the answer to a question can be deducted from an answer candidate. |
| 6.QQP | Classify whether a pair of questions is a rephrasing of each other (semantically equivalent) |
| 7.SST2 | Classify the sentiment of a sentence as positive or negative |
| 8.STSB | Classify the sentiment of a sentence on a scale from 1 to 5 (21 Sentiment classes) |
| 9.CB | Classify for a premise and a hypothesis whether they contradict each other or not (binary). |
| 10.COPA | Classify for a question, premise, and 2 choices which choice the correct choice is (binary). |
| 11.MultiRc | Classify for a question, a paragraph of text, and an answer candidate, if the answer is correct (binary), |
| 12.WiC | Classify for a pair of sentences and a disambiguous word if the word has the same meaning in both sentences. |
| 13.WSC/DPR | Predict for an ambiguous pronoun in a sentence what it is referring to. |
| 14.Summarization | Summarize text into a shorter representation. |
| 15.SQuAD | Answer a question for a given context. |
| 16.WMT1. | Translate English to German |
| 17.WMT2. | Translate English to French |
| 18.WMT3. | Translate English to Romanian |
- Every T5 Task example notebook to see how to use every T5 Task.
- T5 Open and Closed Book question answering notebook
Open book and Closed book question answering with Google’s T5
T5 Open and Closed Book question answering tutorial
With the latest NLU release and Google’s T5 you can answer general knowledge-based questions given no context and in addition answer questions on text databases. These questions can be asked in natural human language and answered in just 1 line with NLU!.
What is an open book question?
You can imagine an open book question similar to an exam where you are allowed to bring in text documents or cheat sheets that help you answer questions in an exam. Kinda like bringing a history book to a history exam.
In T5’s terms, this means the model is given a question and an additional piece of textual information or so-called context.
This enables the T5 model to answer questions on textual datasets like medical records , news articles, wiki-databases , stories and movie scripts , product descriptions, ‘legal documents’ and many more.
You can answer an open-book question in 1 line of code, leveraging the latest NLU release and Google’s T5.
All it takes is:
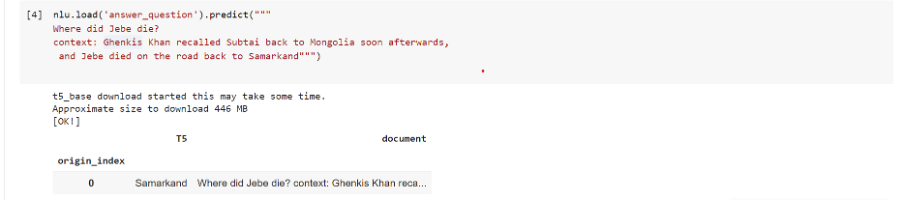
Example for answering medical questions based on medical context
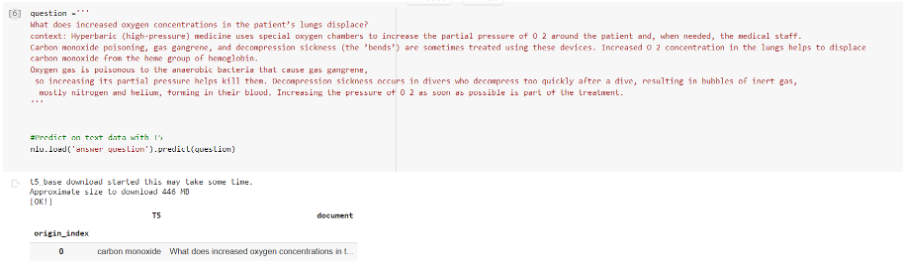
Take a look at this example on a recent news article snippet:
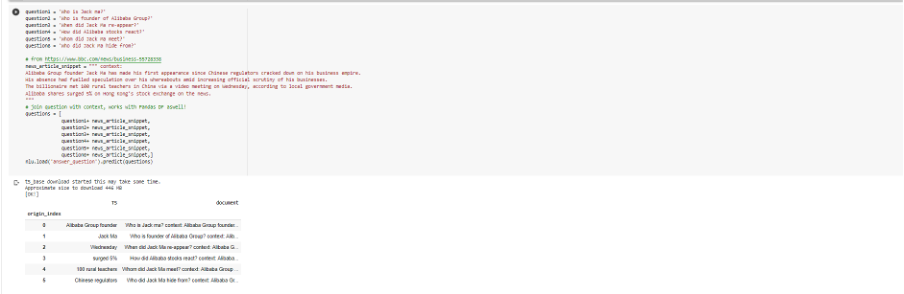
What is a closed book question?
A closed book question is the exact opposite of an open book question. In an exam scenario, you are only allowed to use what you have memorized in your brain and nothing else.
In T5’s terms, this means that T5 can only use it’s stored weights to answer a question and is given no additional context. T5 was pre-trained on the C4 dataset which contains petabytes of web crawling data collected over the last 8 years, including Wikipedia in every language.
This gives T5 the broad knowledge of the internet stored in its weights to answer various closed book questions. You can answer closed book questions in 1 line of code, leveraging the latest NLU release and Google’s T5.
You need to pass one string to NLU, which starts which a question and is followed by a context: tag and then the actual context contents. All it takes is:

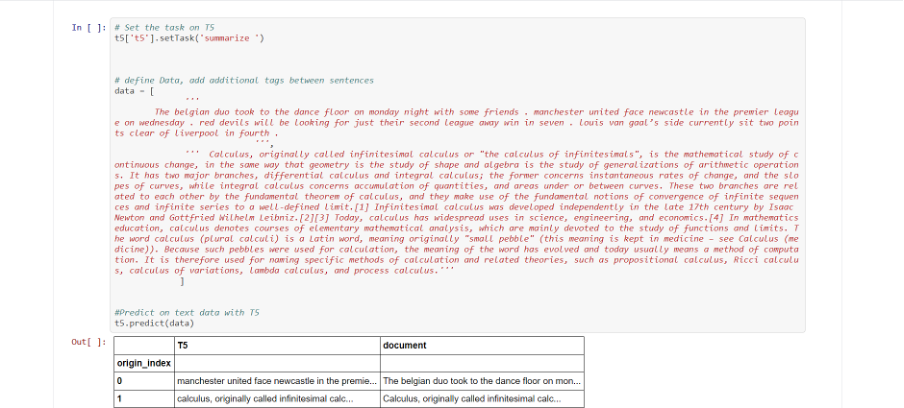
Text Summarization with T5
Summarizes a paragraph into a shorter version with the same semantic meaning, based on this paper.
Binary Sentence similarity/ Paraphrasing
Binary sentence similarity example Classify whether one sentence is a re-phrasing or similar to another sentence
This is a sub-task of GLUE and based on MRPC – Binary Paraphrasing/ sentence similarity classification
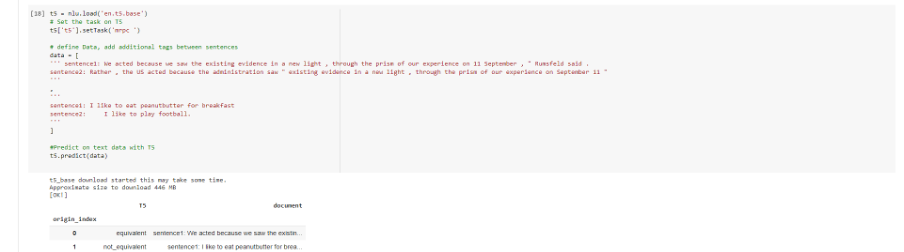
How to configure T5 task for MRPC and pre-process text
.setTask('mrpc sentence1:) and prefix second sentence with sentence2:
Example pre-processed input for T5 MRPC – Binary Paraphrasing/ sentence similarity
mrpc
sentence1: We acted because we saw the existing evidence in a new light, through the prism of our experience on 11 September, ” Rumsfeld said.
sentence2: Rather, the US acted because the administration saw ” existing evidence in a new light, through the prism of our experience on September 11″,
Regressive Sentence similarity/ Paraphrasing
Measures how similar two sentences are on a scale from 0 to 5 with 21 classes representing a regressive label.
This is a sub-task of GLUE and based onSTSB – Regressive semantic sentence similarity.

How to configure T5 task for stsb and pre-process text
.setTask('stsb sentence1:) and prefix second sentence with sentence2:
Example pre-processed input for T5 STSB – Regressive semantic sentence similarity
stsb sentence1: What attributes would have made you highly desirable in ancient Rome? sentence2: How I GET OPPERTINUTY TO JOIN IT COMPANY AS A FRESHER?’,
Grammar Checking
Grammar checking with T5 example Judges if a sentence is grammatically acceptable.
Based on CoLA – Binary Grammatical Sentence acceptability classification.

Document Normalization
Document Normalizer example
The Document Normalizer extracts content from HTML or XML documents, applying either data cleansing using an arbitrary number of custom regular expressions either data extraction following the different parameters.

Word Segmenter
Word Segmenter Example
The WordSegmenter segments languages without any rule-based tokenization such as Chinese, Japanese, or Korean.

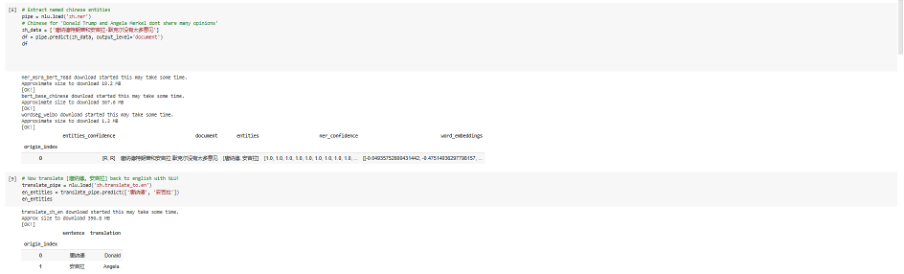
Named Entity Extraction (NER) in Various Languages
NLU now supports NER for over 60 languages, including Korean, Japanese, Chinese, and many more!
New NLU Notebooks
NLU 1.1.0 New Notebooks for new features
- Translate between 192+ languages with marian
- Try out the 18 Tasks like Summarization Question Answering and more on T5
- T5 Open and Closed Book question answering tutorial
- Tokenize, extract POS and NER in Chinese
- Tokenize, extract POS and NER in Korean
- Tokenize, extract POS and NER in Japanese
- Normalize documents
- Aspect based sentiment NER sentiment for restaurants
NLU 1.1.0 New Classifier Training Tutorials
1. Binary Classifier training Jupyter tutorials
- 2 class Finance News sentiment classifier training
- 2 class Reddit comment sentiment classifier training
- 2 class Apple Tweets sentiment classifier training
- 2 class IMDB Movie sentiment classifier training
- 2 class Twitter classifier training
2. Multi-Class Text Classifier training Jupyter tutorials
- 5 class WineEnthusiast Wine review classifier training
- 3 class Amazon Phone review classifier training
- 5 class Amazon Musical Instruments review classifier training
- 5 class Tripadvisor Hotel review classifier training
NLU 1.1.0 New Medium Tutorials
- 1 line to Glove Word Embeddings with NLU with t-SNE plots
- 1 line to Xlnet Word Embeddings with NLU with t-SNE plots
- 1 line to AlBERT Word Embeddings with NLU with t-SNE plots
- 1 line to CovidBERT Word Embeddings with NLU with t-SNE plots
- 1 line to Electra Word Embeddings with NLU with t-SNE plots
- 1 line to BioBERT Word Embeddings with NLU with t-SNE plots
Installation
# PyPi !pip install nlu pyspark==2.4.7 #Conda # Install NLU from Anaconda/Conda conda install -c johnsnowlabs nlu




