
























































Introduction
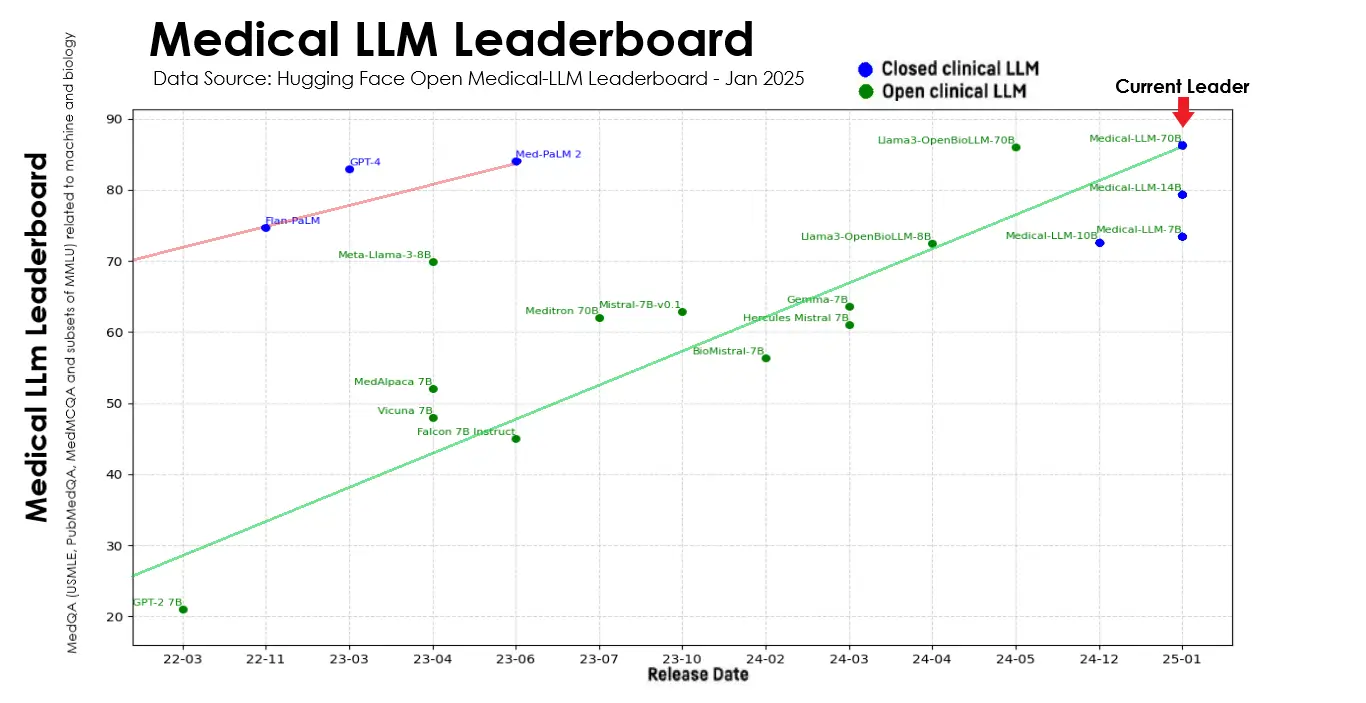
John Snow Labs’ latest 2025 release of its Medical Large Language Models advance Healthcare AI by setting new state-of-the-art accuracy on medical LLM benchmarks. This advances what’s achievable in a variety of real-world use cases including clinical assessment, medical question answering, biomedical research synthesis, and diagnostic decision support.
Leading the pack is their largest 70B model, which can read and understand up to 32,000 words at once – that’s roughly 64 pages of medical text. The model is specially trained to work with medical information, from patient records to research papers, making it highly accurate for healthcare tasks. What makes this release special is how well the model performs while still being practical enough for everyday use in hospitals and clinics – thanks to a suite of models in different sizes, that balance accuracy with speed, cost, and privacy.
OpenMed Benchmark Performance
The comprehensive evaluation of John Snow Labs’ Medical LLM suite encompasses multiple standardized benchmarks, providing a thorough assessment of their capabilities across various medical domains. These evaluations demonstrate not only the models’ proficiency in medical knowledge but also their practical applicability in real-world healthcare scenarios.
The OpenMed evaluation framework represents one of the most rigorous testing environments for medical AI models, covering a broad spectrum of medical knowledge and clinical reasoning capabilities. Our models have undergone extensive testing across multiple categories, achieving remarkable results that validate their exceptional performance:
Model Performance Matrix
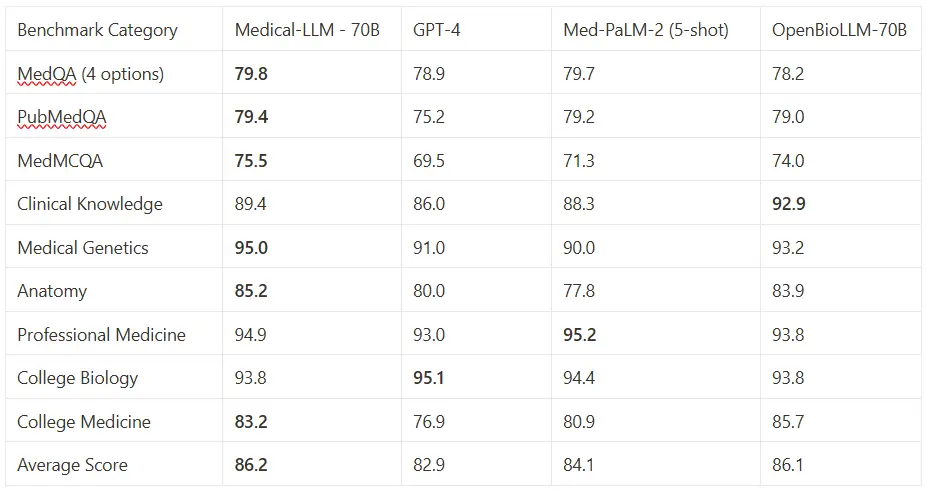
Large (70B+) Models Comparison
- All scores are presented as percentages (%)
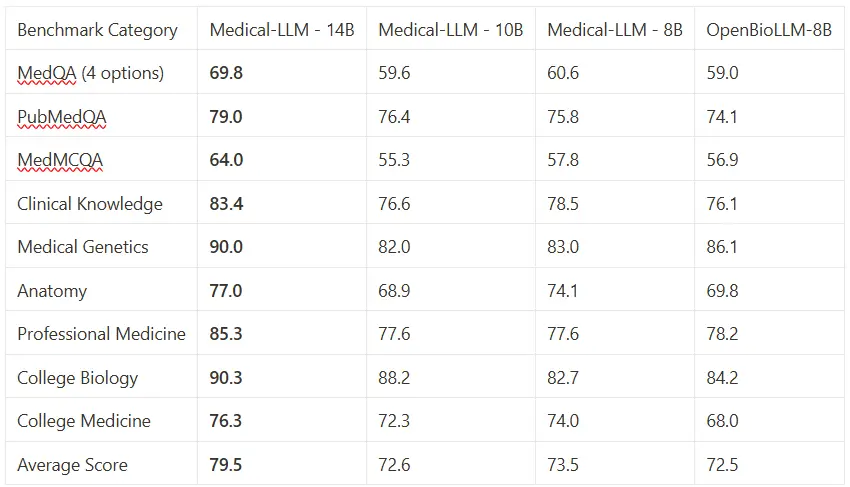
Smaller Models Comparison
- All scores are presented as percentages (%)
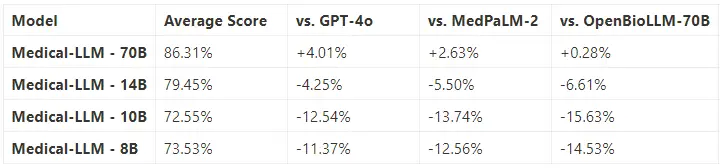
Performance Against Industry Leaders
Open Medical Leaderboard Performance Analysis
The Medical LLMs demonstrate strong performance across specialized medical domains, showing particular strength in clinical reasoning, research comprehension, and medical education. The following table provides a detailed breakdown of performance across key medical
1. Clinical Knowledge
- Outperforms GPT-4 in clinical knowledge assessment (89.43% vs 86.04%)
- Shows stronger diagnostic and treatment planning capabilities
2. Medical Genetics
- Exceeds both GPT-4 and Med-PaLM-2 in genetic analysis (95% vs 91% and 90%)
- Demonstrates advanced understanding of genetic disorders and inheritance patterns
3. Medical Knowledge: Anatomy
- Superior anatomical knowledge compared to both alternatives (85.19% vs 80% and 77.8%)
- Shows stronger grasp of structural and functional relationships
4. Clinical Reasoning: Professional Practice
- Surpasses GPT-4 in professional medical scenarios (94.85% vs 93.01%)
- Better understanding of medical protocols and clinical guidelines
5. Cross-Domain Capability: Life Sciences
- Slightly lower than GPT-4 but comparable to Med-PaLM-2 (93.75% vs 95.14% and 94.4%)
- Strong foundation in biological sciences and medical principles
6. Medical Knowledge: Core Concepts
- Significantly outperforms both models (83.24% vs 76.88% and 80.9%)
- Better understanding of fundamental medical concepts
7. Clinical Case Analysis
- Slightly better performance in clinical case scenarios (79.81% vs 78.87% and 79.7%)
- More accurate in diagnostic decision-making
8. Medical Research Comprehension
- Notable improvement over GPT-4 in research analysis (79.4% vs 75.2%)
- Better at interpreting medical literature and research findings
9. Clinical Assessment
- Substantially higher performance in clinical assessments (75.45% vs 69.52% and 71.3%)
- Superior ability in evaluating clinical scenarios and treatment options
General Intelligence: Nous Benchmark Analysis
The Nous benchmark represents a comprehensive evaluation framework that assesses models’ capabilities across various cognitive tasks, from basic comprehension to complex reasoning.
This benchmark is particularly valuable as it evaluates both general intelligence and specialized medical knowledge application. Evaluating domain-specific LLMs on general-purpose benchmarks is important to validate that they are not overfit on that domain, and can still converse and answer questions well on general knowledge topics.
- Medical-LLM-70B: 72.5 on GPT4All evaluation
- Medical-LLM-14B: 65.0 on GPT4All evaluation
- Medical-LLM-10B: 58.3 on GPT4All evaluation
- Medical-LLM-8B: 55.7 on GPT4All evaluation
Small Yet Powerful: Efficiency Meets Performance
A key strength of this model suite is its ability to deliver exceptional performance with smaller, more efficient models – demonstrating that state-of-the-art medical AI can be both powerful and resource-efficient.
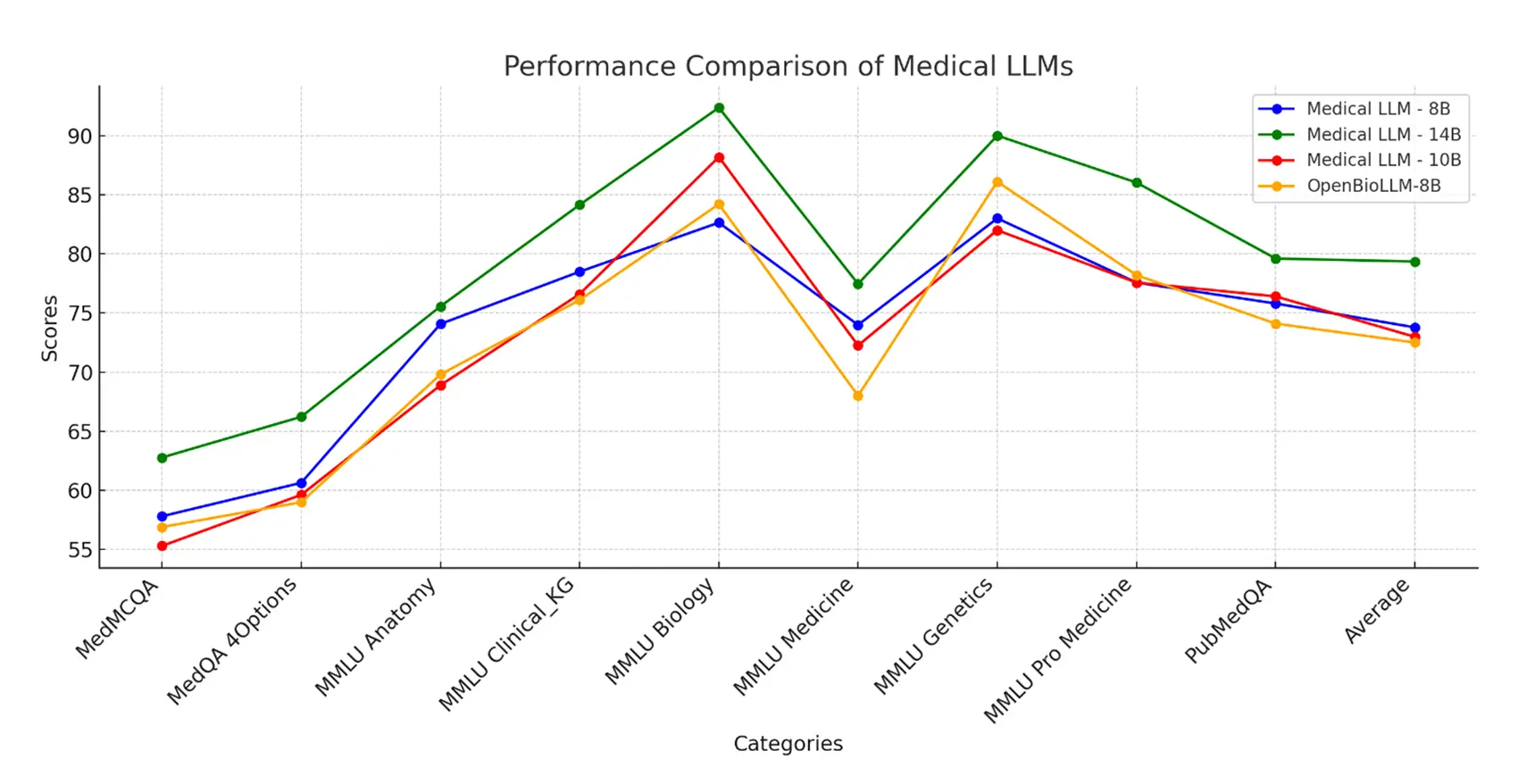
The figures demonstrate the comparative performance metrics of our models across key medical benchmarks and clinical reasoning tasks.

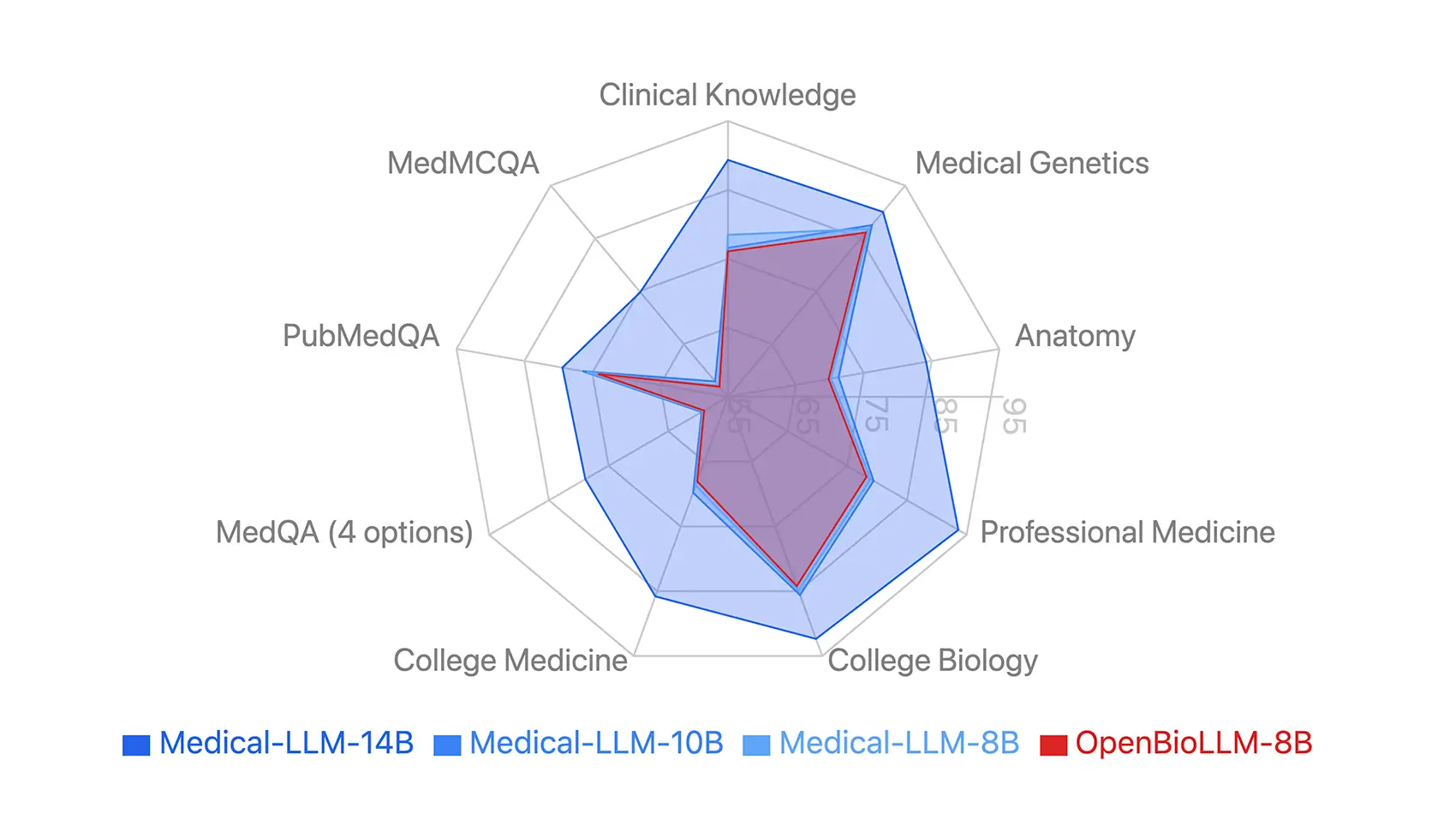
Medical-LLM – 14B
- Achieves 81.42% average score vs GPT-4’s 82.85% and Med-PaLM-2’s 84.08%
- Clinical knowledge score of 92.36% vs Med-PaLM-2’s 88.3%
- Medical reasoning at 90% matches Med-PaLM-2’s performance
- Higher accuracy than Meditron-70B while using 5x less parameters
- Suitable for deployment scenarios with compute constraints
Medical-LLM – 10B
- Average score of 75.19% across medical benchmarks
- Clinical analysis score of 88.19% vs Med-PaLM-1’s 83.8%
- Medical Genetics score of 82% vs Med-PaLM-1’s 75%
- Comparable performance to models requiring 7x more parameters
- Balanced option for resource-conscious implementations
Medical-LLM – 7B
- Clinical reasoning score of 86.81% vs Med-PaLM-1’s 83.8%
- Average score of 71.70% on OpenMed benchmark suite
- PubMedQA score of 75.6%, higher than other 7B models
- Matches GPT-4’s accuracy on medical QA with 100x fewer parameters
- Efficient choice for high-throughput clinical applications
Performance-to-Size Comparison

*Inference speed measured on standard hardware for typical medical queries
**Efficiency calculated as average performance per billion parameters
These smaller models demonstrate that exceptional medical AI performance doesn’t require massive computational resources, making advanced healthcare AI more accessible and deployable across a wider range of settings.
Available Now
These models are available through leading cloud marketplaces, making deployment and integration straightforward for healthcare organizations. The marketplace availability ensures scalable access to these state-of-the-art medical AI capabilities, with enterprise-grade security and compliance features built-in. Organizations can leverage these models through flexible consumption-based pricing models, enabling both small-scale implementations and large enterprise deployments.
Amazon Bedrock Marketplace:
- Medical LLM – Medium (70B)
- Medical LLM – Small (14B)
AWS Sagemaker Marketplace:
The models are also available on Databricks, Snowflake, and on-premise so that they can be deployed locally or on any cloud provider. These LLMs are always deployed within each customer’s private infrastructure and security perimeter. This means that no data being sent to or from these LLMs is ever shared outside that environment – not with John Snow Labs and not with any third-party – meeting the strict security, privacy, and compliance requirements of even the most sensitive applications.
The release of John Snow Labs’ Medical LLM suite represents a milestone in medical AI, offering unprecedented accuracy while maintaining practical utility. These models demonstrate that carefully optimized smaller models can achieve exceptional performance, making advanced medical AI more accessible and usable in real-world healthcare settings.




