

























































* This is the first article in a series of blog posts to help Data Scientists and NLP practitioners learn the basics of Spark NLP library from scratch and easily integrate it into their workflows. During this series, we will do our best to produce high-quality content and clear instructions with accompanying codes both in Python and Scala regarding the most important features of Spark NLP. Through these articles, we aim to make the underlying concepts of Spark NLP library as clear as possible by touching all the practical and pain points with codes and instructions. The ultimate goal is to let the audience get started with this amazing library in a short time and smooth the learning curve. It’s expected that the reader has at least a basic understanding of Python and Spark.
Natural language processing (NLP) is a key component in many data science systems that must understand or reason about a text. Common use cases include question answering, paraphrasing or summarising, sentiment analysis, natural language BI, language modeling, and disambiguation.
NLP is essential in a growing number of AI applications. Extracting accurate information from free text is a must if you are building a chatbot, searching through a patent database, matching patients to clinical trials, grading customer service or sales calls, extracting facts from financial reports or solving for any of these 44 use cases across 17 industries.
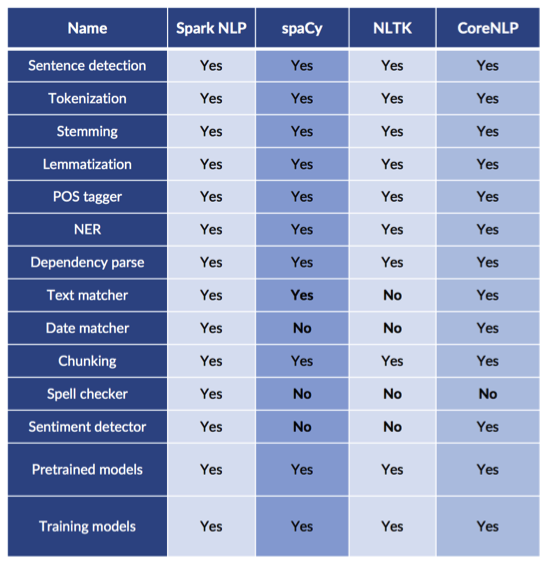
Due to the popularity of NLP and hype in Data Science in recent years, there are many great NLP libraries developed and even the newbie data science enthusiasts started to play with various NLP techniques using these open source libraries. Here are the most popular NLP libraries that have been used heavily in the community and under various levels of development.
- Natural Language Toolkit (NLTK): The complete toolkit for all NLP techniques.
- TextBlob: Easy to use NLP tools API, built on top of NLTK and Pattern.
- SpaCy: Industrial strength NLP with Python and Cython.
- Gensim: Topic Modelling for Humans
- Stanford Core NLP: NLP services and packages by Stanford NLP Group.
- Fasttext: NLP library for the learning of word embeddings and sentence classification created by Facebook’s AI Research (FAIR) lab
Obviously, there are many more libraries in the general field of NLP — but we focus here on general-purpose libraries and not ones that cater to specific use cases. Given all these libraries, you can ask why we would need another NLP library.
We will try to answer this question under the following topics:
1. A single unified solution for all your NLP needs
When you want to deliver scalable, high-performance and high-accuracy NLP-powered software for real production use, none of those libraries provides a unified solution.
Keep in mind that any NLP pipeline is always just a part of a bigger data processing pipeline: For example, question answering involves loading training data, transforming it, applying NLP annotators, building features, training the value extraction models, evaluating the results (train/test split or cross-validation), and hyperparameter estimation. We need an all-in-one solution to ease the burden of text preprocessing and connecting the dots between various steps of solving a data science problem with NLP. So, we can say that a good NLP library should be able to correctly transform the free text into structured features and let you train your own NLP models that are easily fed into the downstream machine learning (ML) or deep learning (DL) pipeline with no hassle.
2. Take advantage of transfer learning and implementing the latest and greatest algorithms and models in NLP research
Transfer learning is a means to extract knowledge from a source setting and apply it to a different target setting, and it is a highly effective way to keep improving the accuracy of NLP models and to get reliable accuracies even with small data by leveraging the already existing labelled data of some related task or domain. As a result, there is no need to amass millions of data points in order to train a state-of-the-art model.
Big changes are underway in the world of NLP for the last few years and a modern industry scale NLP library should be able to implement the latest and greatest algorithms and models — not easy while NLP is having its ImageNet moment and state-of-the-art models are being outpaced twice a month.
The long reign of word vectors as NLP’s core representation technique has seen an exciting new line of challengers such as ELMo, BERT, RoBERTa, ALBERT, XLNet, Ernie, ULMFiT, OpenAI transformer, which are all open-source, including pre-trained models, and can be tuned or reused without a major computing effort. These works made headlines by demonstrating that pre-trained language models can be used to achieve state-of-the-art results on a wide range of NLP tasks, sometimes even surpassing the human level benchmarks.
3. Lack of any NLP library that’s fully supported by Spark
Being a general-purpose in-memory distributed data processing engine, Apache Spark gained a lot of attention from industry and has already its own ML library (SparkML) and a few other modules for certain NLP tasks but it doesn’t cover all the NLP tasks that are needed to have a full-fledged solution. When you try to use Spark into your pipeline, you usually need to use other NLP libraries to accomplish certain tasks and then try to feed your intermediary steps back into Spark. But, splitting your data processing framework from your NLP frameworks means that most of your processing time gets spent serializing and copying strings back and forth and it is highly inefficient.
4. Delivering a mission-critical, enterprise-grade NLP library
Many of the most popular NLP packages today have academic roots — which shows in design trade-offs that favour ease of prototyping over runtime performance, breadth of options over simple minimalist API’s, and downplaying of scalability, error handling, frugal memory consumption, and code reuse.
The library is already in use in enterprise projects — which means that the first level of bugs, refactoring, unexpected bottlenecks, and serialization issues have been resolved. Unit test coverage and reference documentation are at a level that made us comfortable to make the code open source.
 Spark NLP is already in use in enterprise projects for various use cases
Spark NLP is already in use in enterprise projects for various use cases

In sum, there was an immediate need for having an NLP library that is simple-to-learn API, be available in your favourite programming language, support the human languages you need it for, be very fast, and scale to large datasets including streaming and distributed use cases.
Considering all these issues, limitations of the popular NLP libraries and recent trends in industry, John Snow Labs, a global AI company that helps healthcare and life science organizations put AI to work faster, decided to take the lead and developed Spark NLP library.
John Snow Labs is an award-winning data analytics company leading and sponsoring the development of the Spark NLP library. The company provides commercial support, indemnification and consulting for it. This provides the library with long-term financial backing, a funded active development team, and a growing stream of real-world projects that drives robustness and roadmap prioritization.
 John Snow Labs is a recipient of several awards in Data Analytics
John Snow Labs is a recipient of several awards in Data Analytics
By integrating Generative AI in Healthcare with advanced systems like Healthcare Chatbot technology, healthcare providers can streamline patient interactions and enhance the accuracy of medical insights, driving forward the future of personalized care.




