



























































Spark NLP for Healthcare NER models outperform ChatGPT by 10–45% on key medical concepts, resulting in half the errors compared to ChatGPT.
Introduction
In the last few months, large language models (LLMs) like ChatGPT have made significant strides in various industries, including clinical and biomedical sectors. As the demand for efficient and accurate solutions in these fields grows, it is crucial to evaluate the performance of these models in clinical and biomedical NLP benchmarks. This blog post focuses on comparing the performance of ChatGPT with Spark NLP for Healthcare, a leading NLP library designed specifically for healthcare applications. We will examine the strengths and weaknesses of both models on clinical named entity recognition, an essential healthcare NLP tasks, with the goal of providing valuable insights for professionals, researchers, and decision-makers to better understand the potential of AI-driven tools in revolutionising the healthcare industry and addressing its complex challenges.
Named Entity Recognition in Spark NLP for Healthcare
Spark NLP for Healthcare comes with 1100+ pretrained clinical pipelines & models out of the box and is consistently making 4–6x less error than Azure, AWS and Google Cloud on extracting medical named entities from clinical notes. It comes with clinical and biomedical named entity recognition (NER), assertion status, relation extraction, entity resolution and de-identification modules that are all trainable. Spark NLP for Healthcare already has 100+ clinical named entity recognition (NER) models that can extract 400+ different entities from various taxonomies.

Spark NLP for Healthcare comes around 300+ clinical NER models that can extract 500+ entities
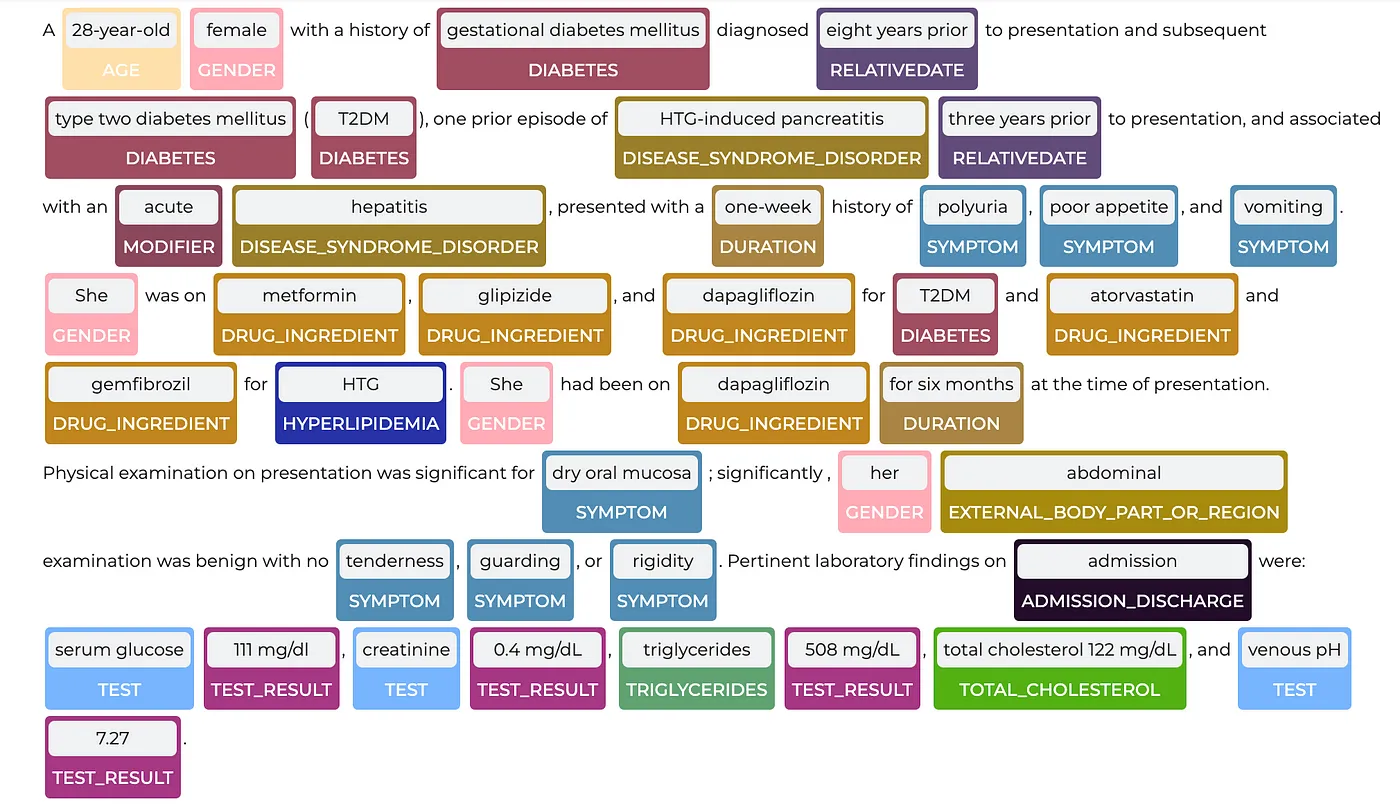
ner_jsl, one of the most popular clinical NER models, can return more than 80 entities at once
Comparison Approach
Our comparison initially focused on ChatGPT’s extraction capability of clinical Named Entity Recognition (NER) entities, specifically on the following entities: Treatments, Test, Problem, Symptom, Oncology, BodyPart, Modifier, Procedure, Laterality, Gender, and Age. To optimize the quality and richness of the prompts, we carefully crafted them with detailed examples and instructions, similar to how human annotators would be guided, employing a few-shot approach (see a detailed prompt below for a single entity).
Extracting clinical concepts and named entities is a challenging task, even for highly trained physicians. Research studies that prompt large language models (LLMs) with only entity names in a zero-shot manner may not give these models a fair opportunity to understand and extract the desired information. To ensure a more balanced comparison with Spark NLP Healthcare NER models, we carefully crafted prompts that mimic the explanation and instruction provided to physician annotators in medical NLP annotation projects. This approach, essentially a few-shot method with additional guidance, aims to remove bias and enable a fair evaluation of the LLM’s capabilities in extracting clinical named entities.
We also observed that ChatGPT’s ability to extract multiple entities simultaneously was limited, especially when dealing with similar concepts. Consequently, we decided to extract only 1–2 entities at a time using proper prompting. Considering that Spark NLP for Healthcare’s NER model can extract even 100+ entities, ChatGPT’s limitations in this regard were noteworthy but not surprising.

Few-shot prompting of ChatGPT for extracting ‘Problem’ entities
Study Design
- Data Selection:We selected 100 sentences from the MTSamples website and annotated them for the entity classes of interest.
- Model Preparation:To prevent data leakage, we examined the dataset of the selected NER models from Spark NLP for Healthcare, retraining some models from scratch and uploading them to Model Hub for evaluation purposes.
- Prediction Collection:We ran the prompts per entity in a few shot settings, and collected the predictions from ChatGPT, which were then compared with the ground truth annotations.
- Performance Comparison: We obtained predictions from the corresponding NER model and compared those with the ground truth annotations as well (even a single token overlapping was considered a hit).
- Reproducibility:All prompts, scripts to query ChatGPT API (ChatGPT-3.5-turbo, temperature=0.7), evaluation logic, and results are shared publicly at a Github repo. Additionally, a detailed Colab notebook to run NER models step by step can be found at the Spark NLP Workshop repo.
Results and Analysis
The comparison of Spark NLP for Healthcare and ChatGPT on key medical NLP concepts reveals that Spark NLP consistently outperforms ChatGPT in all tested entities. The largest difference is observed in Oncology entities, with Spark NLP achieving a score of 0.84 and ChatGPT only 0.45 — nearly half the performance. ChatGPT also underperforms significantly in BodyPart, Test, and Drug entities.
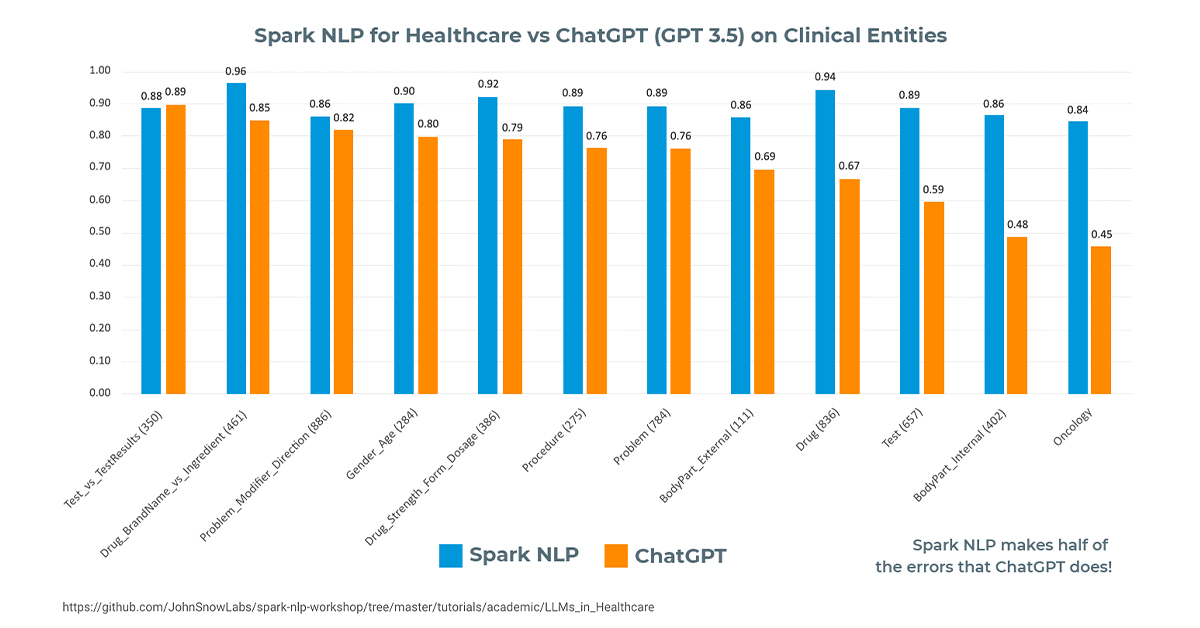
The comparison chart of Spark NLP for Healthcare and ChatGPT on key medical NLP concepts. The numbers within the parentheses denote the number of entities in ground truth
Interestingly, when we prompt ChatGPT to extract conceptually related entities simultaneously, such as Test vs Test Result or Drug vs Dosage, Form, and Strength, its performance improves and comes closer to Spark NLP’s NER model. However, when prompted with unrelated entities, its performance declines.
These results align well with another study on ChatGPT’s zero-shot learning capabilities shows its strength in reasoning tasks but highlights its struggles in specific tasks like sequence tagging (i.e., NER). Both ChatGPT and GPT-3.5 exhibit subpar performance on CoNLL03, a popular named entity recognition dataset, with ChatGPT’s average accuracy being 53.7%. In contrast, Spark NLP NER model achieves > 98% accuracy on the same dataset. This suggests that despite being generalist models, current large language models still face challenges in addressing specific tasks like named entity recognition.
Conclusion
Despite its capabilities, ChatGPT (and GPT-4) has similar limitations as earlier GPT models, as illustrated clearly in this blogpost. Most importantly, it still is not fully reliable (it “hallucinates” facts and makes reasoning errors). Great care should be taken when using language model outputs, particularly in high-stakes contexts (e.g. healthcare), with the exact protocol (such as human review, grounding with additional context, or avoiding high-stakes uses altogether) matching the needs of a specific use-case.
In summary, Spark NLP outperforms ChatGPT by 10–45% on key medical concepts, resulting in half the errors compared to ChatGPT. This highlights the strengths of Spark NLP in tackling medical NLP tasks more effectively. Although ChatGPT shows potential in some aspects, healthcare providers and researchers should consider Spark NLP solutions for Healthcare as a more reliable and robust solution for extracting valuable insights from medical data.





