



























































A practical guide on how to set up and run John Snow Labs NLP libraries on a Databricks instance.

Introduction
John Snow Labs is an award-winning AI company that helps healthcare and life science organizations put AI to work faster. In the last couple of years, John Snow Labs has emerged as a clear industry leader for state-of-the-art NLP in healthcare through the use of the highly popular libraries it builds and maintains: Spark NLP, Spark NLP for Healthcare, Spark OCR, and NLU.
As a way to facilitate the deployment and quick usage of the NLP libraries, it is now possible to automatically deploy them on your Databricks account by filling in a 5 fields form and letting John Snow Labs handle the rest.
Why use John Snow Labs NLP on Databricks?
Databricks is a highly scalable data platform for data engineering and data science which offers a zero-management cloud platform built around Spark that delivers:
- fully managed Spark clusters,
- an interactive workspace for exploration and visualization,
- a production pipeline scheduler, and
- a platform for powering your favorite Spark-based applications.
So instead of tackling data headaches, you can use the Databrics platform and focus on finding answers that make an immediate impact on your business. If you handle large amounts of unstructured text documents or scanned pdfs that you need to digitize and then analyze, you also need NLP and/or OCR.
To help you skip the headaches of Spark configuration and libraries installations, John Snow Labs now offers a simple form that sets up the environment for you and gives you the relevant notebook examples for all the tasks you might need so you can start analyzing your data right away.
Automatic deployment
To automatically install John Snow Labs NLP libraries to your Databricks instance, fill in this form with your contact info and the details of your Databricks account.
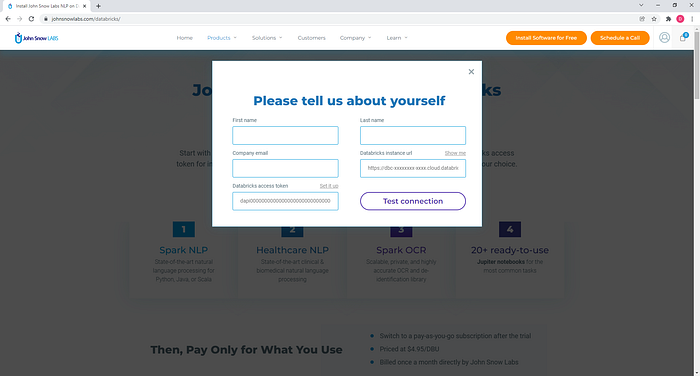
You need to provide the complete instance URL as described here. The instance URL should have the following structure:
https://<databricks-instance>/?o=6280049833385130
Multi-Tenant accounts
If you have a multi-tenant account, there should be an oparam in the deployment URL. The value of this oparam represents the Databricks workspace ID. Make sure the URL you provide in the install form includes the o param.
Single Tenant accounts
In case you have a single tenant account, the instance URL does not contain the o parameter. In this situation, you will have to validate the correctness of the data by thicking the confirmation checkbox before initiating the installation process.
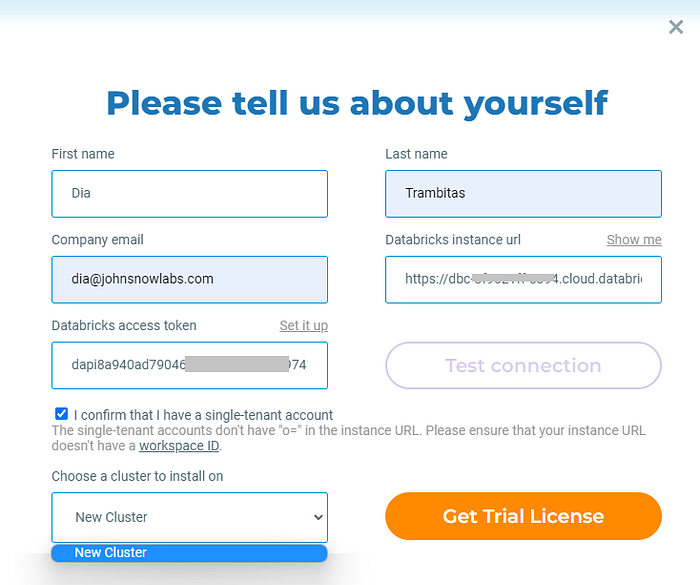
Databricks access token
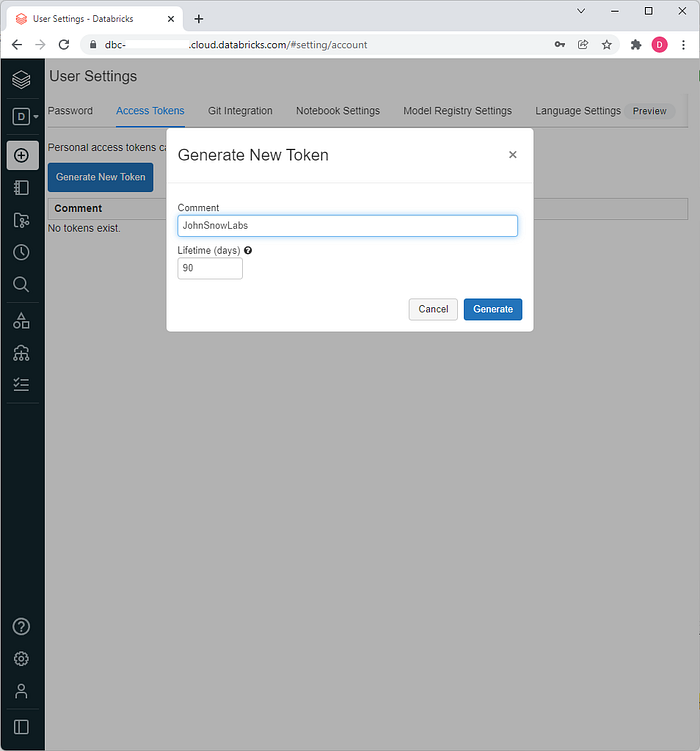
In order to grant John Snow Labs access to your account for performing the installation, you need to set up a dedicated access token. For this, go to your Databricks account >User Settings > Access Tokens and click the Generate New Token button. Make sure you save the newly generated token for later use.
To initiate the deployment, click on the “Get Trial License” button. This will request a Spark NLP for Healthcare and Spark OCR trial license on your behalf. Next, you will receive an email from John Snow Labs to check that the provided e-mail address is valid. Click on the “Validate my email” link. You will be redirected to the below link and the installation process will start.
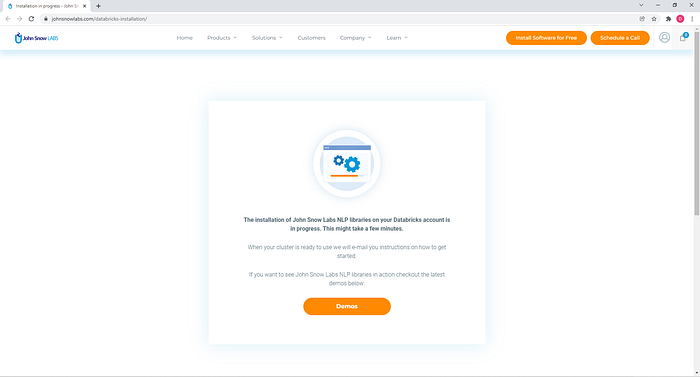
Use John Snow Labs NLP on Databricks
If you check your Databricks account, you will notice a new cluster is being created and the libraries are being installed.

Once the installation is completed, a set of ready-to-use notebooks covering the most important NLP and OCR tasks are copied to your workspace, under the John Snow Labs folder.
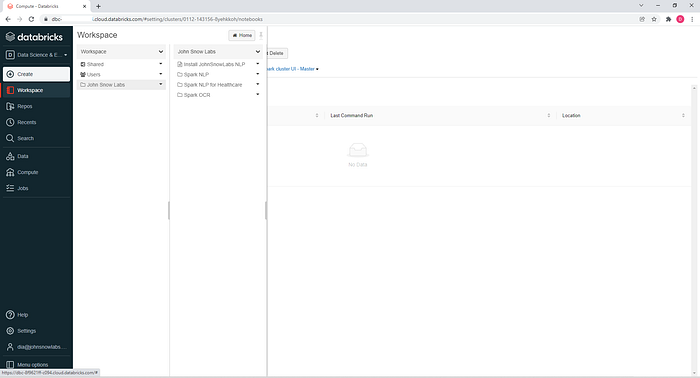
In summary, you will get:
- Spark NLP — State-of-the-art natural language processing for Python, Java, or Scala.
- Spark NLP for Healthcare — State-of-the-art clinical & biomedical natural language processing.
- Spark OCR — Scalable, private, and highly accurate OCR and de-identification library.
- 20+ ready-to-use Jupiter notebooks for the most common tasks.
All you need to do in order to use one of the predefined notebooks is double-click on the name of the file to open it and attach it to the new cluster from the upper left side dropdown.

Access your trial license
The Databricks install form also generates a 30 days trial license for Spark NLP for Healthcare and Spark OCR. This will be automatically deployed on your Databricks account as part of your installation and you can use it on as many clusters as you want for as many documents as needed.
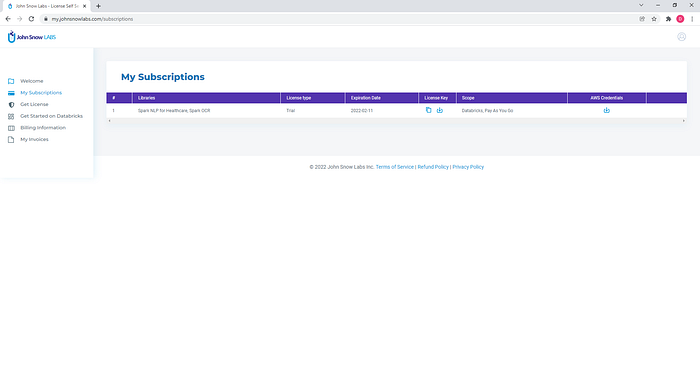
In case you need to extend or renew the license, this can be done via my.JohnSnowLabs.com website. Connect to your account (for login credentials check your email) and check “My Subscription” page. You can download your license and manually use it on your account.
Databricks licenses are bound to specific instances and organizations – the ones provided in the installation form. You will not be able to reuse them in another environment.
In case you need to install the libraries on a new cluster, you can use the Install John Snow Labs NLP notebook available on your workspace. Just attach it to your new cluster and run all cells.
What next?
After the trial license expires, the Spark NLP for Healthcare and Spark OCR libraries will stop processing documents. If you choose to buy a license, you can do so via your my.JohnSnowLabs.com account and will get new credentials that will reactivate the libraries. Otherwise, you must uninstall the software. In any case, the data you have already processed is yours to keep.
During the 30-day free trial, we will receive an email with a link to activate a paid license and provide a payment method. If you choose to do so, a commercial subscription will be automatically generated for you at the end of the trial and deployed to your instance so that your pipelines continue to work without interruption.
For more information, you can check the official website https://www.johnsnowlabs.com/databricks/




