This blog post explores how John Snow Labs’ Healthcare NLP & LLM library is transforming clinical trials by using advanced NER models to efficiently filter through large datasets of patient records. By automatically extracting cancer-related information from unstructured clinical notes, the solution enables researchers to quickly identify patients with specific cancer indications, accelerating trial enrolment and ensuring more accurate patient selection.
In clinical trials, identifying the right patient population is crucial for accurate results and successful outcomes. When working with massive datasets, such as ten million patient records, filtering out those with specific cancer indications can be a daunting and time-consuming task.
Also, precision medicine plays a critical role in clinical trials by ensuring that the right patient population is identified based on specific tumor mutations. In this approach, large-scale tumor sequencing of cancer patients allows researchers to categorize individuals and match them to targeted treatments, ensuring that trial participants are selected based on precise profiles. This process optimizes the effectiveness of clinical trials by focusing on patients most likely to benefit from specific therapies, ultimately leading to more accurate results and successful outcomes. By leveraging this method, clinical trials can achieve more meaningful insights into treatment efficacy and patient responses.
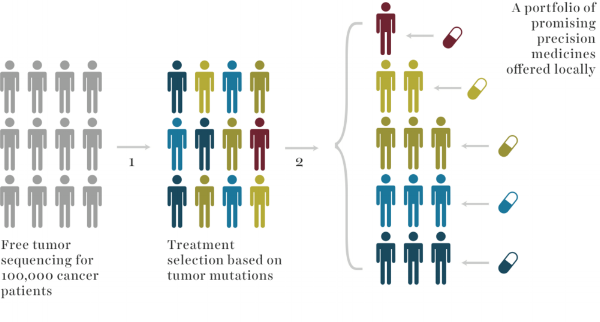
https://unclineberger.org/octr/our-research/strata-trial/
John Snow Labs’ Healthcare NLP & LLM library offers a powerful solution to streamline this process. By leveraging advanced Named Entity Recognition (NER) models, the library can automatically extract and categorize cancer-related information from unstructured clinical notes. This capability allows researchers to efficiently identify and filter patients with particular cancer types, accelerating trial enrollment and ensuring that the selected cohort meets precise criteria. With this technology, clinical trials can achieve faster, more accurate patient stratification, ultimately leading to more effective research and better outcomes for patients.
John Snow Labs, offers a powerful NLP & LLM library tailored for healthcare, empowering professionals to extract actionable insights from medical text. Utilizing advanced techniques like NER, assertion status detection, and relation extraction, this library helps uncover vital cancer information for more accurate diagnosis, treatment, and prevention.
Let us start with a short Spark NLP introduction and then discuss the details of identifying patient cohorts with some solid results.
Healthcare NLP & LLM
The Healthcare Library is a powerful component of John Snow Labs’ Spark NLP platform, designed to facilitate NLP tasks within the healthcare domain. This library provides over 2,200 pre-trained models and pipelines tailored for medical data, enabling accurate information extraction, NER for clinical and medical concepts, and text analysis capabilities. Regularly updated and built with cutting-edge algorithms, the Healthcare library aims to streamline information processing and empower healthcare professionals with deeper insights from unstructured medical data sources, such as electronic health records, clinical notes, and biomedical literature.
John Snow Labs has created custom large language models (LLMs) tailored for diverse healthcare use cases. These models come in different sizes and quantization levels, designed to handle tasks such as summarizing medical notes, answering questions, performing retrieval-augmented generation (RAG), named entity recognition and facilitating healthcare-related chats.
John Snow Labs’ GitHub repository serves as a collaborative platform where users can access open-source resources, including code samples, tutorials, and projects, to further enhance their understanding and utilization of Spark NLP and related tools.
John Snow Labs also offers periodic certification training to help users gain expertise in utilizing the Healthcare Library and other components of their NLP platform.
John Snow Labs’ demo page provides a user-friendly interface for exploring the capabilities of the library, allowing users to interactively test and visualize various functionalities and models, facilitating a deeper understanding of how these tools can be applied to real-world scenarios in healthcare and other domains.
Scenario 1: Detect Pathological Findings
Extracting detailed information from patient reports, such as tumor grade, stage, and histological type, is critical for identifying specific cancer indications. This data provides valuable insights into the clinical and biological characteristics of the cancer, which is essential for filtering patients based on precise criteria.
In this scenario, we focus on patients diagnosed with Carcinoma and further narrow down the selection to those whose reports indicate the presence of CK7, which is a protein marker belonging to the cytokeratin family that is commonly used in cancer diagnosis, and it is a type II intermediate filament protein found in many epithelial cells. This biomarker result is particularly significant, as it informs targeted treatment options and plays a crucial role in selecting the right candidates for clinical trials focused on therapies for this mutation.
Let’s start with this dataframe of patient reports:

26 patient reports, involving the mentions of diagnoses, symptoms and tests.
The pipeline below will utilize the ner_cancer_types_wip model to extract oncological entities from the documents, followed by the DocumentFiltererByNER annotator, which will filter for documents containing Carcinoma. This approach allows us to efficiently identify and select the patients of interest for this clinical trial.
# Step 1: Transforms raw text to `document`type
document_assembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol( "document")
# Step 2: Sentence Detection/Splitting
sentence_detector = SentenceDetectorDLModel.pretrained("sentence_detector_dl_healthcare","en","clinical/models") \
.setInputCols(["document"]) \
.setOutputCol("sentence")
# Step 3: Tokenization
tokenizer = Tokenizer()\
.setInputCols(["sentence"])\
.setOutputCol("token")\
# Step 4: Clinical Embeddings
word_embeddings = WordEmbeddingsModel.pretrained("embeddings_clinical", "en", "clinical/models") \
.setInputCols(["sentence", "token"]) \
.setOutputCol("embeddings")
# Step 5: NER Model
ner_cancer_types = MedicalNerModel.pretrained("ner_cancer_types_wip", "en", "clinical/models") \
.setInputCols(["sentence","token", "embeddings"]) \
.setOutputCol("cancer_types_ner")
# Step 6: Converter
ner_cancer_types_converter = NerConverterInternal() \
.setInputCols(["sentence","token","cancer_types_ner"]) \
.setOutputCol("cancer_types_chunk")\
# Step 7 Filterer to get only the texts of ineterst for the use case
filterer = DocumentFiltererByNER() \
.setInputCols(["sentence", "final_ner_chunk"]) \
.setOutputCol("filterer") \
.setWhiteList(["Carcinoma_Type"])
# Define the pipeline
nlp_pipeline = Pipeline(stages=[
document_assembler,
sentence_detector,
tokenizer,
word_embeddings,
ner_cancer_types,
ner_cancer_types_converter,
])
# Create an empty dataframe
data = spark.createDataFrame([[""]]).toDF("text")
# Fit the dataframe to the pipeline to get the model
nlp_model = nlp_pipeline.fit(data)
Here are the patient records (11 out of a total of 26 patient reports), which include the diagnosis of various Carcinoma types.
By using the code below, we can produce a dataframe, which involves the columns for the original text, extracted original chunk, the label assigned by the NER model and the prediction confidence.
result.select('idx', 'filterer',F.explode(F.arrays_zip(result.oncology_chunk.result,
result.oncology_chunk.metadata)).alias("cols")) \
.select('idx', 'filterer',F.expr("cols['0']").alias("chunk"),
F.expr("cols['1']['entity']").alias("ner_label"),
F.expr("cols['1']['confidence']").alias("confidence")) \
.filter(F.col("ner_label") == "Carcinoma_Type") \
.show(truncate=120)

Clinical reports that include mentions of various types of carcinoma.
By applying further filters to the dataset, we can extract only those patient records that include the CK7 biomarker.
result.select('idx',F.explode(F.arrays_zip(result.final_ner_chunk.result,
result.final_ner_chunk.metadata)).alias("cols")) \
.select('idx',F.expr("cols['0']").alias("chunk"),
F.expr("cols['1']['entity']").alias("ner_label"),
F.expr("cols['1']['confidence']").alias("confidence")) \
.filter(F.col("chunk") == "CK7") \
.show(truncate=False)

So, 7 patient reports may be used for this study.
Scenario 2: Map Trial Eligibility
In the current scenario, we are focusing on identifying patients who exhibit evidence of cancer in their livers. This targeted approach allows us to narrow down the pool of potential participants to those whose medical profiles match the study’s requirements for lung cancer involvement. By implementing this filter, we can efficiently isolate the subset of patient records that are most relevant to our research objectives, thereby streamlining the recruitment process and ensuring that our clinical trial population is optimally aligned with the study’s goals and scientific inquiries.
First, we get the reports with the mentions of the body sites.
filterer = DocumentFiltererByNER() \
.setInputCols(["sentence", "oncology_chunk"]) \
.setOutputCol("filterer") \
.setWhiteList(["Body_Site"])
These are the filtered reports containing references to specific anatomical sites.

Further filtering will allow us to get the reports of liver cancers.
result.select('idx', 'filterer',F.explode(F.arrays_zip(result.oncology_chunk.result,
result.oncology_chunk.metadata)).alias("cols")) \
.select('idx', 'filterer',F.expr("cols['0']").alias("chunk"),
F.expr("cols['1']['entity']").alias("ner_label"),
F.expr("cols['1']['confidence']").alias("confidence")) \
.filter(F.col("chunk") == "liver") \
.show(truncate=170)
Only 2 reports (1 and 19) include liver cancers.

Scenario 3: Find Disease Progression
Extracting detailed information from pathology reports, such as tumor grade, stage, and histological type, is vital for identifying specific cancer indications and understanding the overall characteristics of a patient’s cancer. This data serves as a critical foundation for filtering patients based on well-defined clinical criteria, allowing researchers to identify the right participants for a clinical trial.
In this particular case, we are focusing on patients diagnosed with cancer, specifically those whose pathology reports indicate that their cancer has metastasized. By targeting both the cancer diagnosis and the metastatic status, we can refine our selection process to ensure that only the most relevant patients are considered for the trial. This approach not only improves the efficiency of patient selection but also ensures that the trial’s outcomes will be more accurate and reflective of the specific disease characteristics being studied.
By making a little change in the white list of the main pipeline, first we filter for the six main cancer types and metastasis entity:
filterer = DocumentFiltererByNER() \
.setInputCols(["sentence", "oncology_chunk"]) \
.setOutputCol("filterer") \
.setWhiteList(["Metastasis", "Melanoma", "Lymphoma_Type", "Leukemia_Type",
"Carcinoma_Type", "Sarcoma_Type", "CNS_Tumor_Type"])
Here are the patient records showing any cancer diagnosis.

By applying further filters to the dataset, we can extract only those patient records that show evidence of metastatic disease.
result.select('idx','filterer', F.explode(F.arrays_zip(result.oncology_chunk.metadata)).alias("cols")) \
.select('idx','filterer',
F.expr("cols['0']['entity']").alias("ner_label"),
F.expr("cols['0']['confidence']").alias("confidence")) \
.filter(F.col("ner_label") == "Metastasis") \
.show(truncate=170)

So, only reports 3, 4, 20 and 21 will include information involving a metastatic cancer.
Conclusion
Integration of John Snow Labs’ Healthcare NLP and LLM library into clinical trial processes marks a pivotal advancement in medical research. By using sophisticated NER models to swiftly analyze vast amounts of unstructured clinical data, this technology is revolutionizing patient selection and trial enrollment. The ability to rapidly and accurately identify suitable candidates not only accelerates research timelines but also enhances the quality of trial cohorts, potentially leading to more robust and meaningful study outcomes. This efficiency gain is particularly crucial in oncology trials, where precise patient selection can significantly impact the success of new cancer treatments.
Looking ahead, the potential of this NLP technology extends far beyond its current applications. As the healthcare industry continues its digital transformation, tools like John Snow Labs’ NLP and LLM library are poised to become integral components of the research ecosystem. By streamlining the often time-consuming and error-prone process of data analysis, these advanced NLP solutions empower researchers to focus more on innovation and less on administrative tasks. As we embrace this new era of AI-assisted medical research, we move closer to a future where treatments are developed more rapidly, trials are more representative, and ultimately, patient outcomes are significantly improved.