
























































Understanding the Importance of Robustness in AI Models
In recent years, foundation models have revolutionized the AI landscape, powering applications ranging from natural language understanding to image recognition. These models are typically designed to perform exceptionally well on benchmark datasets, primarily measuring their accuracy. While accuracy is undeniably critical — ensuring the model performs correctly on expected inputs — there’s a growing consensus in the AI community that robustness is even more important. In this context, robustness refers to a model’s ability to maintain performance when faced with slight deviations, adversarial inputs, or unforeseen conditions in real-world environments. As foundation models become deeply embedded in applications that impact daily lives, robustness isn’t merely a nice-to-have feature; it’s essential for safe, reliable AI deployment.
Robustness is particularly crucial in applications where stakes are high, such as healthcare, finance, and autonomous systems. Even a small misinterpretation in these fields could lead to potentially harmful outcomes. Testing foundation models for accuracy alone may fail to reveal vulnerabilities that could compromise their integrity in dynamic, unpredictable environments. This blog post explores the need to go beyond accuracy by using tools like LangTest, which assesses robustness through a series of stress tests, providing insights into how models handle challenging scenarios that can lead to accuracy degradation.
The Limitations of Accuracy as a Sole Metric
Accuracy often serves as the primary metric in model evaluation, but an over-reliance on it can lead to an incomplete understanding of a model’s true capability. Foundation models may achieve impressive accuracy on curated, clean datasets, but these datasets rarely capture the full diversity of inputs encountered in real-world applications. When deployed, these models are exposed to nuanced, unpredictable variations in input data, leading to instances where high accuracy on benchmarks does not necessarily translate to reliable real-world performance. This phenomenon exposes a fundamental gap in traditional accuracy metrics, highlighting the need for evaluating robustness to ensure the model remains dependable across diverse scenarios.
Without robustness testing, models risk falling prey to errors caused by out-of-distribution inputs or adversarial attacks, which can cause significant accuracy drops. For example, language models may misinterpret questions with slight grammatical errors or unconventional phrasings, leading to inaccurate outputs. This limitation underscores the need for robustness as an essential metric, particularly for foundation models deployed at scale. In scenarios where slight deviations in input can lead to misclassification or inaccurate predictions, a model’s robustness — or lack thereof — becomes as important as, if not more than, its accuracy.
Enhancing Model Reliability Through Robustness Testing
LangTest developed by John Snow Labs offers a comprehensive solution for testing and enhancing model robustness by providing a suite of tests specifically designed to assess how well models perform under stress. LangTest simulates different real-world variations by incorporating adversarial examples, paraphrasing, and noise injection, each designed to probe weaknesses that may not be apparent through accuracy testing alone. For example, LangTest can evaluate how a model responds to typos, slang, or unconventional language structures, which are common in user-generated content. This kind of testing is vital for understanding where models may falter and offers a roadmap for fine-tuning them to handle these variations more effectively.
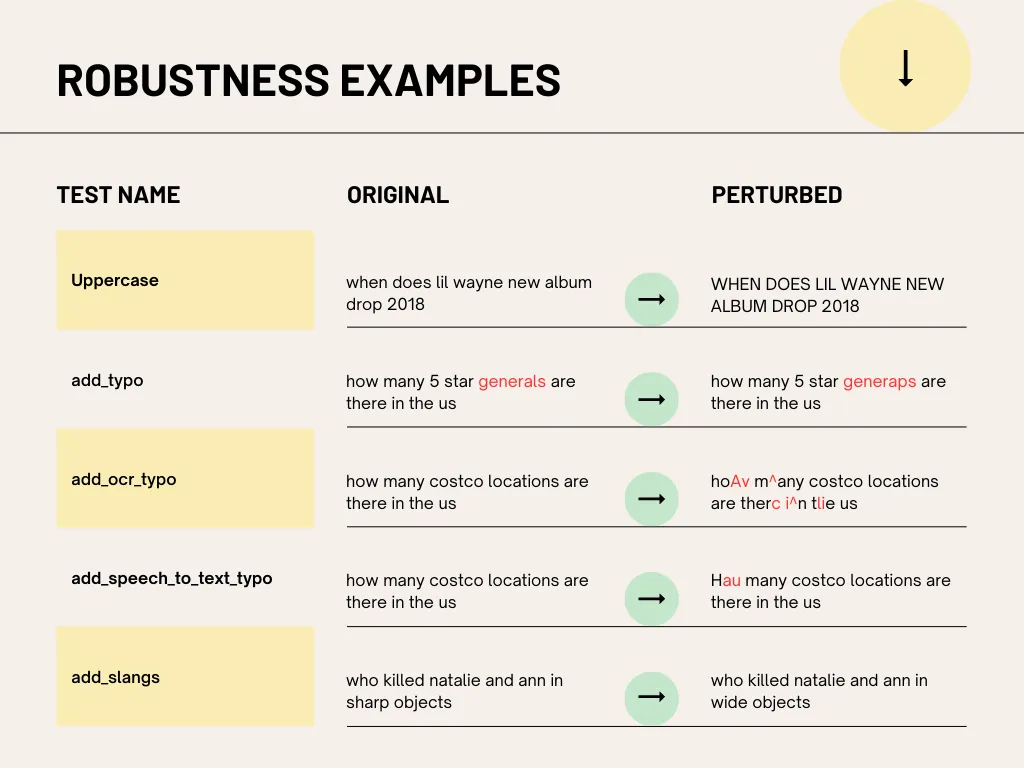
By analyzing how accuracy fluctuates over these robustness tests, LangTest provides insights into a model’s reliability across various input types. If a model’s accuracy drops significantly on these tests, developers gain actionable insights into specific weaknesses, enabling targeted improvements. This approach shifts the focus from achieving high accuracy on standard benchmarks to creating models that deliver consistently accurate and reliable results, even in less-than-ideal input conditions. With LangTest, model developers are better equipped to build foundation models that are not only accurate but resilient, meeting the complex demands of real-world applications.
Let’s do Degradation Testing with Langtest
Degradation analysis tests are designed to evaluate how the performance of a model degrades when the input data is perturbed. These tests help in understanding the robustness and bias of the model. The process typically involves the following steps:
- Perturbation:The original input data is then perturbed. Perturbations can include various modifications such as adding noise, changing word order, introducing typos, or other transformations that simulate real-world variations and errors.
- Ground Truth vs. Expected Result:This step involves comparing the original input data (ground truth) with the expected output. This serves as a baseline to understand the model’s performance under normal conditions.
- Ground Truth vs. Actual Result:The perturbed input data is fed into the model to obtain the actual result. This result is then compared with the ground truth to measure how the perturbations affect the model’s performance.
- Accuracy Drop Measurement:The difference in performance between the expected result (from the original input) and the actual result (from the perturbed input) is calculated. This difference, or accuracy drop, indicates how robust the model is to the specific perturbations applied.
Initialize the Harness form Langtest:
#Import Harness from the LangTest library from langtest import Harness
Configure the Tests required to Test
from langtest.types import HarnessConfig
test_config = HarnessConfig({
"tests": {
"defaults": {
"min_pass_rate": 0.6,
},
"robustness": {
"uppercase": {
"min_pass_rate": 0.7,
},
"lowercase": {
"min_pass_rate": 0.7,
},
"add_slangs": {
"min_pass_rate": 0.7,
},
"add_ocr_typo": {
"min_pass_rate": 0.7,
},
"titlecase": {
"min_pass_rate": 0.7,
}
},
"accuracy": {
"degradation_analysis": {
"min_score": 0.7,
}
}
}
})
Dataset Config
data = {
"data_source": "BoolQ",
"split": "dev-tiny",
}
Setup the Harness Instance with test_config
harness = Harness(
task="question-answering",
model={
"model": "llama3.1:latest",
"hub": "ollama",
"type": "chat",
},
config=test_config,
data=data
)
Generate and run the test cases on the model
harness.generate().run()
To get a report from the harness
harness.report()
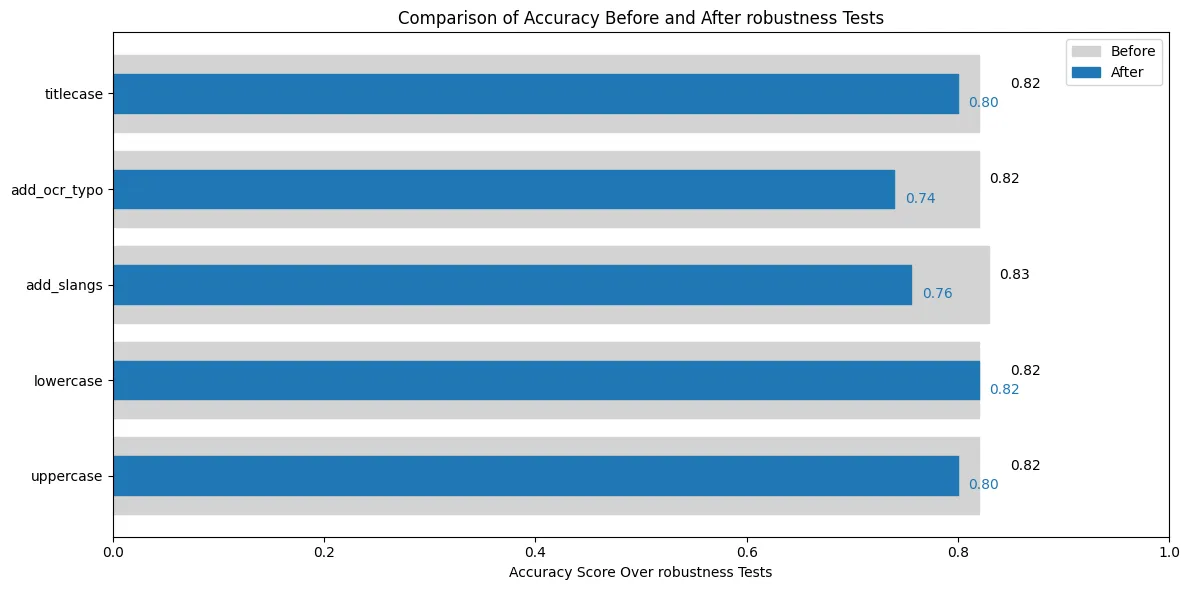
Before and After Robustness Testing with Accuracy Comparison
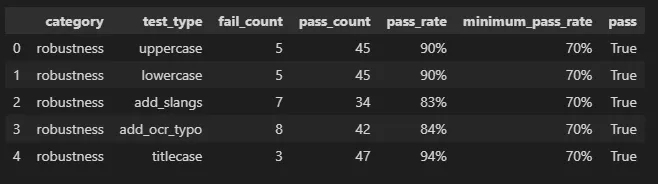
harness report
By conducting degradation analysis tests, you can identify weaknesses in the model’s robustness, and take steps to improve its performance under varied and potentially noisy real-world conditions.
The degradation analysis on the Llama3.1 model evaluates its robustness under various perturbation tests such as uppercase, lowercase, titlecase, add_ocr_typo, and add_slangs. The results indicate the following observations:
- Minimal Degradation:
– For lowercase and uppercase perturbations, the accuracy remained consistent at 82%, showing that the model is robust to case changes.
– Titlecase perturbations had a slight drop, where accuracy decreased from 0.82 to 0.80. - Moderate Degradation:
Perturbations involving add_slangs caused a noticeable drop in accuracy from 0.83 to 0.76. This indicates that the model struggles to interpret inputs with informal or slang language. - Significant Degradation:
The add_ocr_typo perturbation resulted in a significant accuracy drop from 0.82 to 0.74, highlighting that the model is less robust to typos or errors typically found in OCR-processed text.
Key Insights:
- Robustness to Case Changes: The model performs well with variations in text case, maintaining consistent accuracy scores.
- Vulnerability to Typos and Slangs: The model’s accuracy drops notably with OCR typos and slang words, which suggests a need for improvement in handling noisy or informal text.
Actionable Recommendations:
To improve the robustness of the Llama3.1 model:
- Train the model with augmented datasets containing typos, OCR noise, and slang variations.
- Implement text pre-processing steps to correct common typos or noisy inputs before feeding them into the model.
- Use adversarial training strategies to address weaknesses in handling informal and perturbed inputs.
Conclusion
In a landscape where foundation models are increasingly deployed in high-stakes applications, robustness testing has become imperative. High accuracy on benchmark datasets alone can no longer be the sole criterion for evaluating the reliability of AI models, particularly when they are intended for use in environments where unpredictability is the norm. Robustness tests, like those offered by LangTest developed by John Snow Labs, provide a deeper, more practical evaluation by simulating real-world variations, enabling developers to understand and mitigate potential weaknesses before deployment. This focus on robustness ultimately enhances user trust and ensures safer, more dependable AI systems.
Going forward, the integration of robustness testing should become a standard practice in model evaluation, complementing traditional accuracy metrics. The insights gained from robustness testing not only empower developers to improve model performance across diverse scenarios but also foster greater confidence in AI’s ability to handle unexpected situations. By prioritizing robustness alongside accuracy, we move closer to achieving foundation models that are not just intelligent but resilient, enabling them to play a more trustworthy role in the real world.




