

























































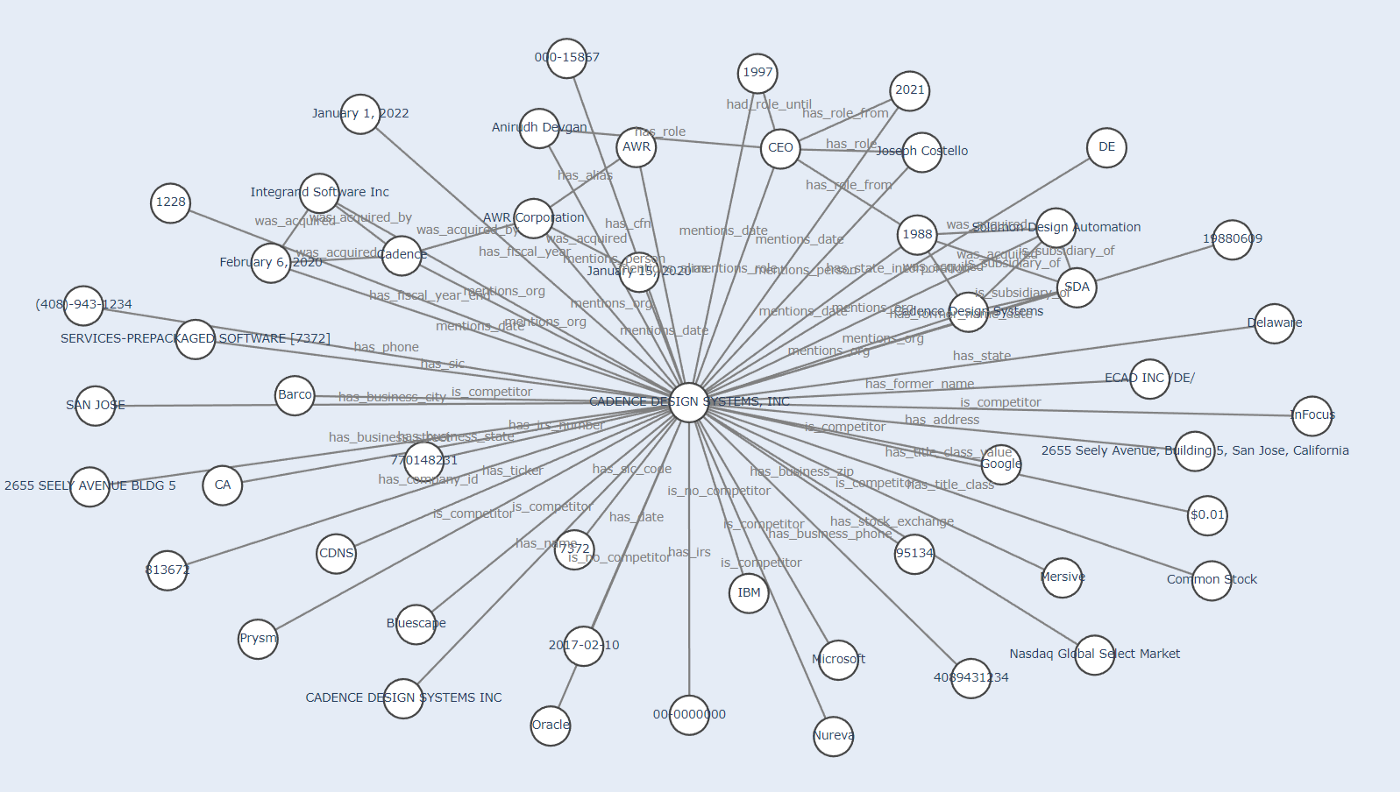
Graph Generation with John Snow Labs Finance NLP
In Oct, 2022 John Snow Labs released Financial NLP, a new addition to the Spark NLP ecosystem to natively carry out NLP at scale in Spark clusters.
By Nov, 2022, the 1.1.0 version already saw the light, and we would like to put some of the models we are realising into a good use: creating a graph of companies.
To do that, we will use the following modules of Financial Spark NLP:
- >Financial Named Entity Recognition;
- Financial Relation Extraction;
- Financial Understanding of Entities in Context (Assertion Status);
- Normalization and Financial Data Augmentation;
To create the graph we will use networkX. To visualize the graph we will use Plotly.
Stay tuned to the 2/2 article showcasing how to run Graph Embeddings with our graphs and carry out node / edge / subgraph similarity and entity prediction.
Notebook
If you want to follow the notebook as we progress on this article, feel free to do so by visiting this link.
Motivation
The notebook will help you process Financial Annual Reports (10K filings) or even Wikipedia data about companies, using John Snow Labs Finance NLP Named Entity Recognition, Relation Extraction and Assertion Status, to extract the following information about companies:
- >Information about the Company itself (
Trading Symbol,State,alias,former name). - Other Companies mentioned in the report as
competitors: we will also run a “Competitor check”, to understand if another company is just in the ecosystem / supply chain of the company or it is really a competitor - People (usually management and C-level) working in that company and their past experiences, including roles and companies
Acquisitionsevents, including the acquisition dates.Subsidiariesmentioned.- Temporality (
past,present,future) and Certainty (possible) of events described, includingForward-looking statements.
Also, John Snow Labs provides with offline modules to check for Edgar database (Entity Linking to resolve an organization name to its official name and Chunk Mappers to map a normalized name to Edgar Database), which are quarterly updated. We will using them to retrieve the official name of a company, former names, dates where names where changed, etc.
The final aim of this accelerator is to help you analyze companies information and, in our next 2/2 article, to run Graph Embeddings on top of the graph you extract (for example, to infer new relations to green nodes given the grey ones in the picture);

Link Prediction
First source of information: Financial NER
The first model we use is Finance NLP NER trained to extract information the first page of SEC 10K filings on the example of Cadence Design Systems, available here.
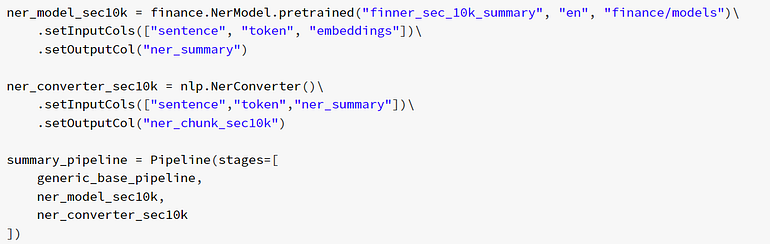
Piece of code for Financial NER
These are some of the entities we extracted.
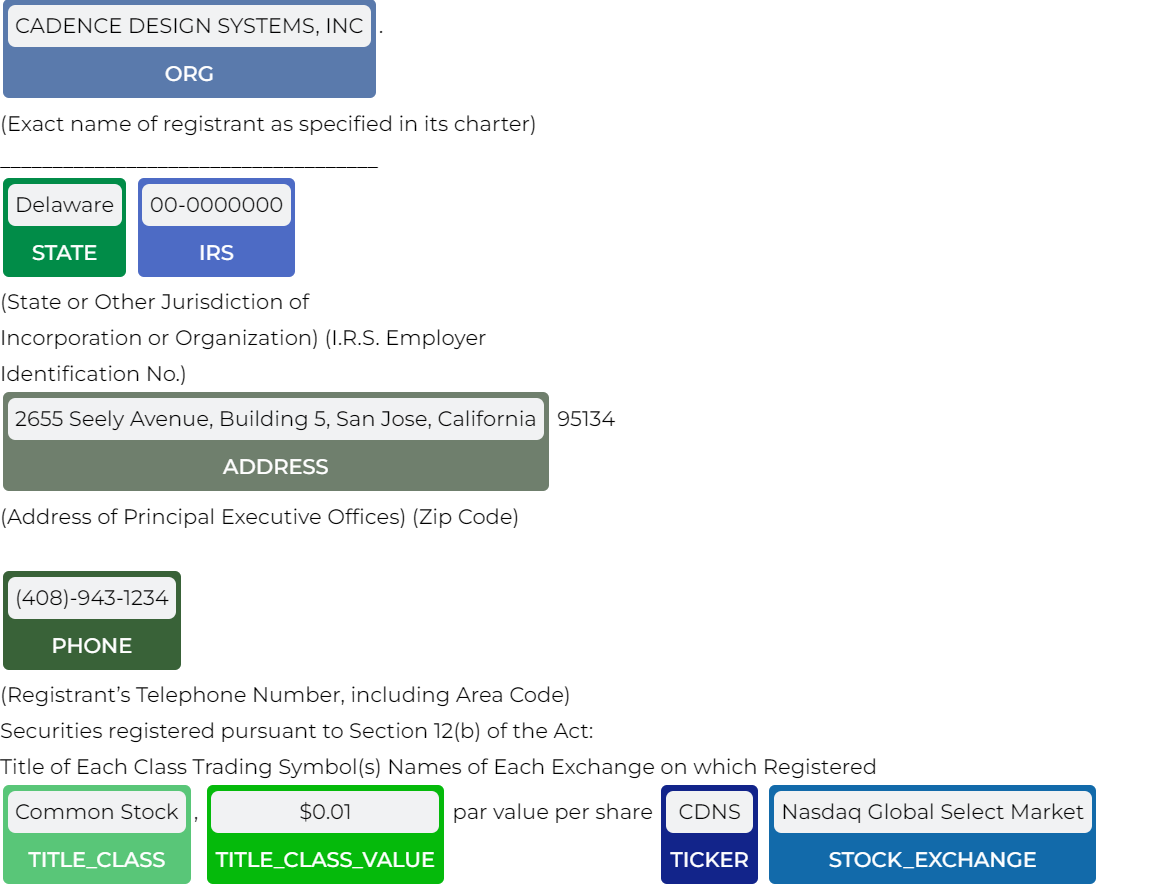
Financial NER visualization
Even though here we don’t have relations, just isolated entities, we know that all the entities extracted are related to the ORG entity. So we can start building our graph with ORG in the center and all the rest of entities connected to it.
Resulted subgraph after processing the first datasource
Second source of information: External Datasources
With Finance NLP Normalization and Data Augmentation, we can get the official version of our company name and map it to external datasources as SEC Edgar. Keep in mind there is no internet connection required to do so, we provide up-to-date annotators with that information in our ChunkMappers in NLP Models Hub.
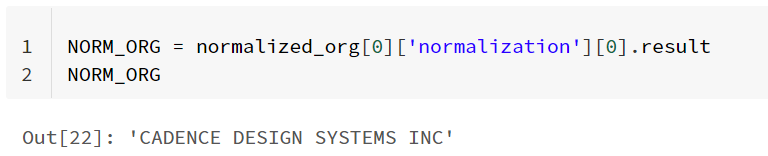
We obtain the normalized company name

Piece of code for Normalization
We augment with information from Edgar datasource
Piece of code for Data Augmentation with Chunk Mappers
Some information registered in our ChunkMapper was already in our document, but some other it was not, so it’s very useful to augment our graph with information it’s not in our current document.
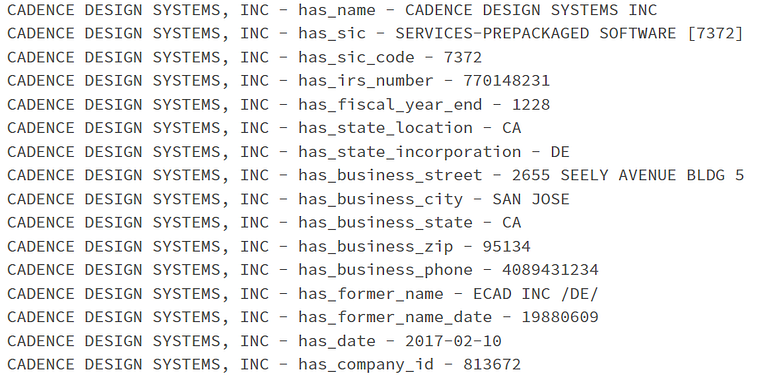
Information stored in Finance NLP Edgar Chunk Mapper
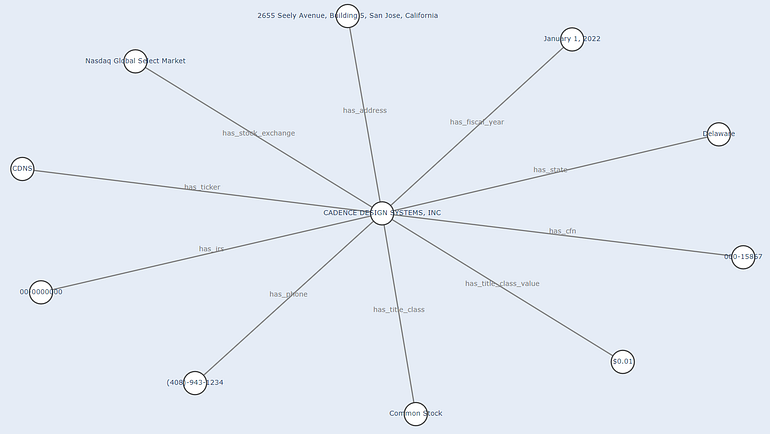
The final graph with all the previous information looks like this:

Graph with information from NER and Normalization+Data Augmentation
Third source of information: NER and RE (Relation Extraction)
Acquisitions, subsidiaries, other names (aliases)
NER only extracts isolated entities by itself. But you can combine some NER with specific Relation Extraction Annotators trained for them, to retrieve if the entities are related to each other. This is an example of acquisitions, subsidiaries and aliases of companies.

Piece of the pipeline containing only the RE components, skipping the rest (please check the notebook for the whole pipeline)
If we run this pipeline on texts from Cadence Wikipedia, you will find the following relations:
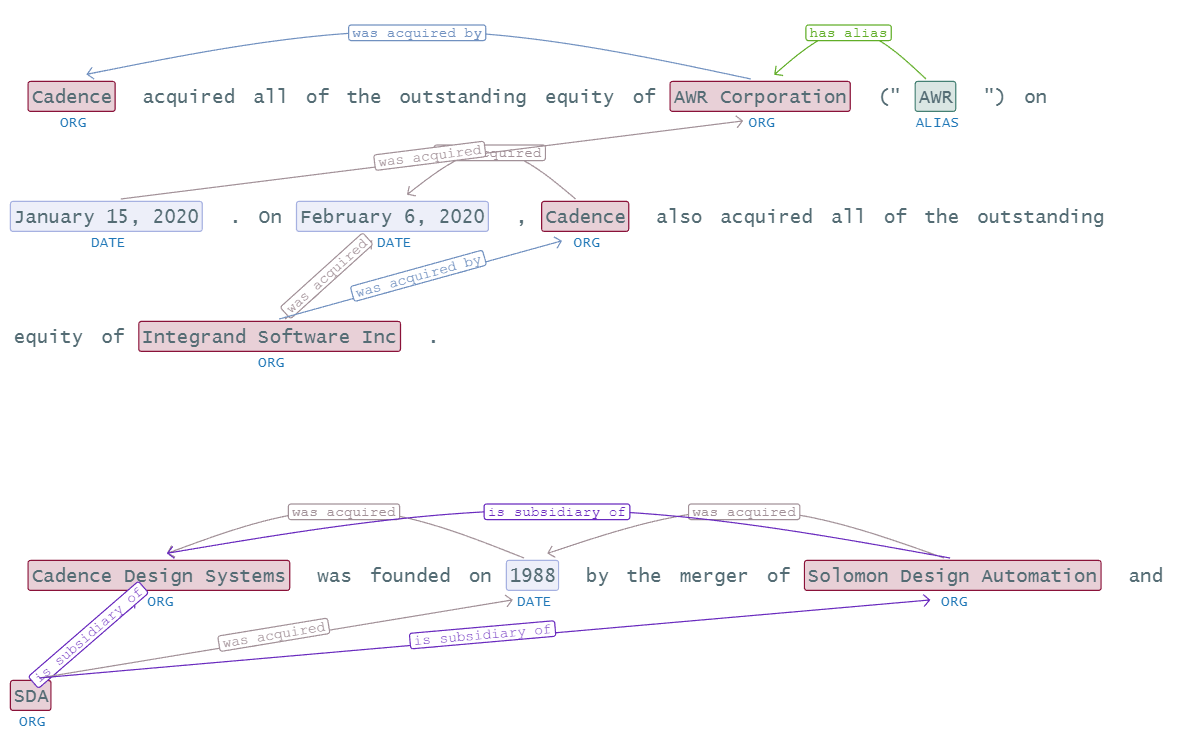
Visualization of extracted Relations
Relation Extraction already extracts nodes (entities) and edges (relations) for us, so we only need to add those to our graph.

Graph containing also acquisitions, subsidiaries and aliases of Cadence.
People and roles
Let’s also extract People’s name with their current roles and past experiences in other companies (including the dates).

Piece of a pipeline. Relation Extraction for People, Roles and Dates. Please check the notebook for the whole pipeline.
Again, let’s run this model on some Wikipedia text about Cadence.

Relation Extraction results
Let’s add also that information to the graph.

Graph containing also current and previous Cadence’s CEO and their working periods.
Fourth source of information: Companies mentioned as competitors in the context
Finance NLP includes an annotator called Assertion Status, which basically analyzes the context of an entity and is able to assert different conditions, as temporary events (present, past, future), certainty (probable) or even if a company is mentioned to be a competitor or not. We will use for the graph this last one.
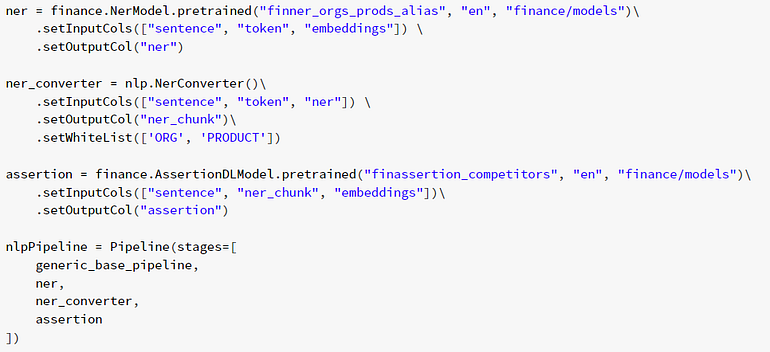
Pipeline to extract ORGS and PRODUCTS and assert if they are mentioned to be competitors
This is an example of result from Cadence 2022 10K filing.

Some ORG entities detected to be COMPETITORS and NO COMPETITORS
We can also add this information to the graph.
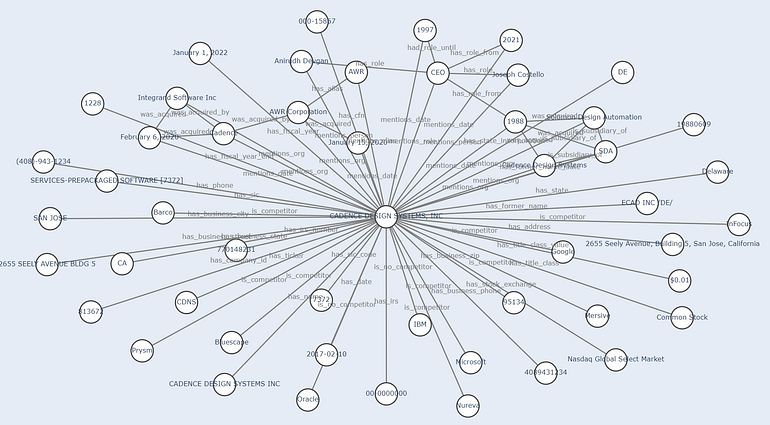
Graph with other ORGs, including Competitors and no competitors
Graph Embeddings
We got an example graph of a company. We can continue processing SEC and Wikidata information and populating the graph to get a better understanding of the company’s ecosystem.
After we are happy with the information contained in it, we can use Graph Embeddings to:
- >Obtain a numerical representation of the company’s ecosystem;
- Be able to compare company graphs and check for similarity between companies. For example, for competition analysis.
- Be able to compare specific nodes or specific edges and check for similarity between them. For example, for new link prediction.
Check out the upcoming 2/2 version of this notebook about how to use that using Spark NLP. Or use node2vec as shown in the notebook.
Want to see more?
- Check our Spark NLP models
- Check our Notebooks
- Check our Demos
How to install
!pip install johnsnowlabsfrom johnsnowlabs import *
jsl.install(json_license_path=[your_finance_license_path])
jsl.start(json_license_path=[your_finance_license_path])
Do you want to request a free trial?
Go to our self-service installation page here and request a trial. Write to support@johnsnowlabs.com if you have enquiries, or find us at our Financial Named Entity Recognition(#finance)





