



























































The latest version of Finance NLP, 1.15, introduces numerous additional features to the existing collection of 926+ models and 125+ Language Models from previous releases of the library. Let’s examine each of these new capabilities in detail.
Updated LLM examples
We added the new Flan-T5-based models for question-answering in our example notebooks, expanding the capabilities of the existing models with the newer version of Google’s multi-task model.
New example notebooks
With the increase in the capabilities of the library, we added new examples ro help users understand how to perform certain specific tasks:
- Text summarization
The updated notebook now shows an example of how to perform summarization on long documents. This is one approach to the challenging problem of how to process long documents with the limitations of the current models in terms of number of tokens they can process on the input texts.
By splitting the document into chunks and taking into consideration the number of tokens that can be processed by the model at each run, the approach we used was able to summarize a long document by split-and-merge strategy.
- Text Generation
In this notebook, we show how to use the Flan-T5-based model to continue generating texts in the Finance domain (text generation), finetuned on Sec 10-K fillings.

- Normalizing date mentions in text
This notebook shows how to use Finance Natural Language Processing to standardize date mentions in the texts to a unique format. When working with data coming from various sources, we may incur the problem of some of the sources using the format mm/dd/yyyy, while other sources use dd/mm/yyyy, and any other format. By standardizing the date mentions, we can easily apply other analytics on the texts to obtain insights from the data.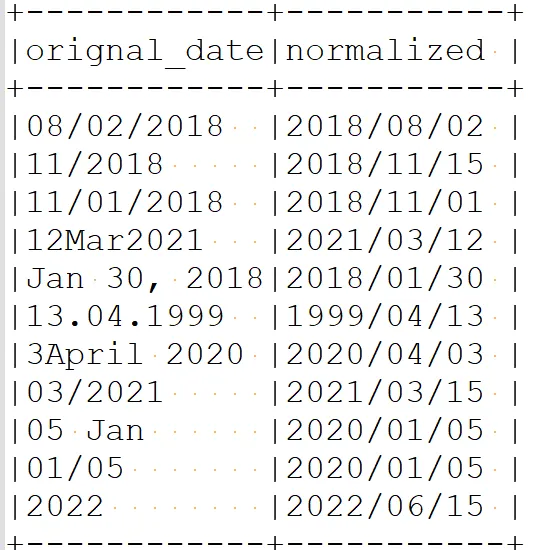
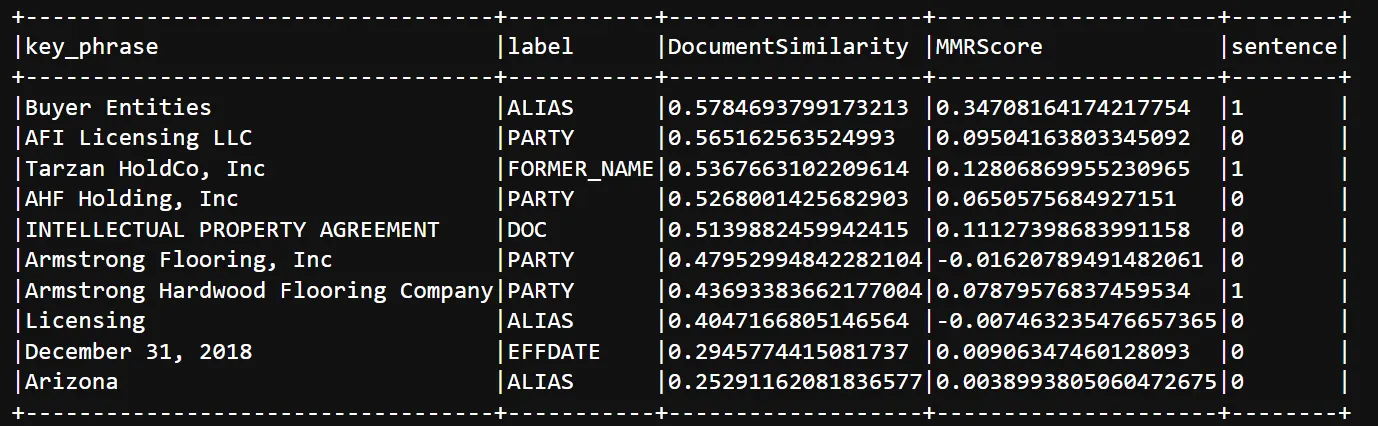
- Extracting important key phrases from text
With the legal.ChunkKeyPhraseExtraction annotator, it is possible to extract the most relevant phrases given candidates coming from either N-Grams or NER entities.
- Drawing boxes around entities in PDF files with Visual NLP and Legal NLP
This example notebook shows how to combine the power of Visual NLP and NLP for Financial services to identify entities coming from PDF/Image files by first extracting the text from the file and using one of the Legal NLP pretrained NER models. Finally, mapping the found entities back to the file and marking them visually. 
Fancy trying?
We’ve got 30-days free licenses for you with technical support from our financial team of technical and SME. This trial includes complete access to more than 150 models, including Classification, NER, Relation Extraction, Similarity Search, Summarization, Sentiment Analysis, Question Answering, etc. and 50+ financial language models.
Just go to https://www.johnsnowlabs.com/install/ and follow the instructions!
Don’t forget to check our notebooks and demos.
How to run
Finance NLP is quite easy to run on both clusters and driver-only environments using johnsnowlabs library:
!pip install johnsnowlabs
from johnsnowlabs import nlp nlp.install(force_browser=True) # Start Spark Session spark = nlp.start()





