
























































The social determinants of health (SDoH) are the non-medical factors that influence health outcomes and usually one of the hardest type of entities to extract with pre-trained clinical NLP models.
In recent years, there has been a growing recognition of the importance of social determinants of health (SDoH) in patient care. SDoH is the conditions in which people are born, grow, live, work, and age that impacts their health outcomes. Clinical text data can be a valuable source of information for studying SDoH. However, manually extracting entities from clinical text data can be time-consuming and resource-intensive. This is where the Social Determinants of Health NER model comes in.
The Health NER Model for SDoH data analytics
Even if there are many other clinical named entity recognition (NER) models out there, extracting social determinants of health (SDoH) entities can be a challenging task due to the reasons stated below:
- Complexity and variability: SDoH entities are complex and can vary greatly in their phrasing and expression in clinical text data. For example, “housing insecurity” can be expressed as “homelessness,” “housing instability,” “lack of affordable housing,” and so on. It can be difficult for classical NER models to accurately capture these variations.
- Context-dependency: The meaning of SDoH entities can depend heavily on the context in which they are used. For instance, “food insecurity” can refer to the lack of access to affordable and nutritious food in some contexts and in others, it can be used to describe the inability to access food due to lack of transportation or mobility. Accurately capturing the context of SDoH entities can be challenging for classical NER models.
- Lack of labeled data: Clinical text data often lacks labeled data for SDoH entities, making it challenging for classical NER models to accurately identify them. A targeted SDoH NER model trained on relevant datasets can help to address this issue by providing labeled data for SDoH entities.
- Interdisciplinary knowledge: Accurately capturing SDoH entities requires interdisciplinary knowledge in areas such as social work, public health, and community health. A targeted SDoH NER model can incorporate this knowledge and enhance the accuracy of entity extraction from clinical text data.
- Clinical relevance: SDoH entities are critical to patient care, and accurate identification can help clinicians develop better treatment plans and improve health outcomes. A targeted SDoH NER model can assist in identifying SDoH entities accurately and efficiently, thus improving the quality of patient care.
The Social Determinants of Health NER models are newly built using the Spark NLP library, which is a powerful tool for natural language processing. They are natural language processing (NLP) models that extract entities related to SDoH from clinical text. Currently, there are 8 trained SDoH models released on the Spark NLP models hub. These models include a major model with all entity labels and 7 sub-models with more specific entities. Here are the models and their explanations.
Benefits of using Social Determinants of Health Software
The Social Determinants of Health NER Model is the major model among SDoH models. Here are the entity labels that this model covers:
+--------------------+-----------------------+-------------------------+ | Education | Population_Group | Quality_Of_Life | | Housing | Substance_Frequency | Smoking | | Eating_Disorder | Obesity | Healthcare_Institution | | Financial_Status | Age | Chidhood_Event | | Exercise | Communicable_Disease | Hypertension | | Other_Disease | Violence_Or_Abuse | Spiritual_Beliefs | | Employment | Social_Exclusion | Access_To_Care | | Marital_Status | Diet | Social_Support | | Disability | Mental_Health | Alcohol | | Insurance_Status | Substance_Quantity | Substance_Use | | Hyperlipidemia | Family_Member | Legal_Issues | | Race_Ethnicity | Gender | Geographic_Entity | | Sexual_Orientation | Transportation | Sexual_Activity | | Language | Other_SDoH_Keywords | | +--------------------+-----------------------+-------------------------+
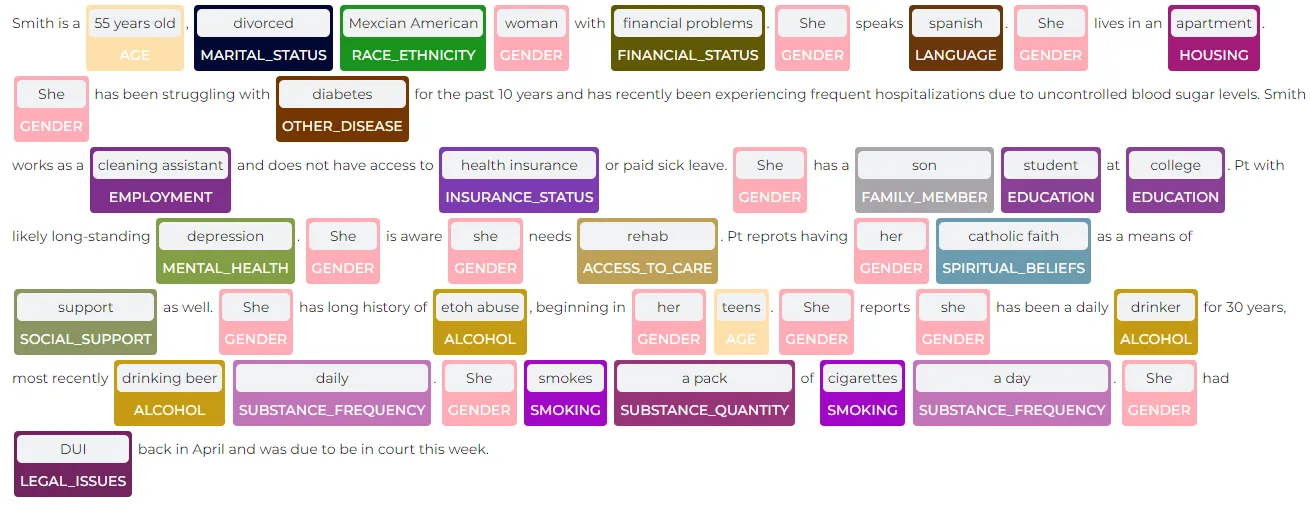
SDoH Sample NER Extraction
Social Determinants of Health NER Sub-Models
There are 7 SDoH sub-models that are concentrated on a dedicated subject of SDoH. Here are the sub-models and their entity labels:
NER SDoH Demographic: Family_Member, Age, Gender, Geographic_Entity, Race_Ethnicity, Language, Spiritual_Beliefs
NER SDoH Social Environment: Social_Support, Chidhood_Event, Social_Exclusion, Violence_Abuse_Legal
NER SDoH Income and Social Status: Education, Marital_Status, Financial_Status, Population_Group, Employment
NER SDoH Health Behaviours and Problems: Diet, Mental_Health, Obesity, Eating_Disorder, Sexual_Activity, Disability, Quality_Of_Life, Other_Disease, Exercise, Communicable_Disease, Hyperlipidemia, Hypertension
NER SDoH Access to Healthcare: Insurance_Status, Healthcare_Institution, Access_To_Care
NER SDoH Community Condition: Transportation, Community_Living_Conditions, Housing, Food_Insecurity
NER SDoH Substance Usage: Smoking, Substance_Duration, Substance_Use, Substance_Quantity, Substance_Frequency, Alcohol
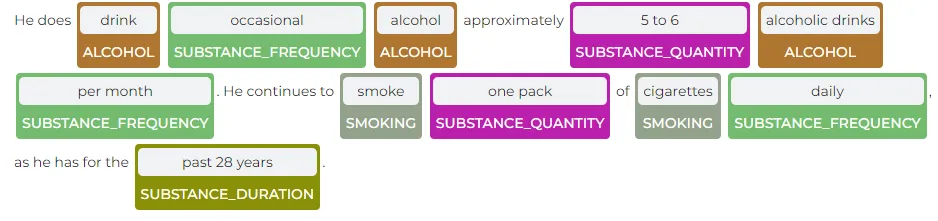
NER SDoH Substance Usage Model Sample
All SDoH models are released as WIP (work in progress) and the annotation and training process continues. The final release will include more entities and is expected to have better performance.
Getting Started
To use SDoh models, you need to install the Spark NLP Healthcare Library. After installation, you can run the below pipeline to extract SDoH entities from clinical text. You can use the above sub-models, too. To use a sub-model, please follow the link of the model, take the model’s stored name, and use the model’s name in the below pipeline.
model_name="ner_sdoh_wip"
document_assembler = DocumentAssembler()\
.setInputCol("text")\
.setOutputCol("document")
sentence_detector = SentenceDetectorDLModel.pretrained("sentence_detector_dl", "en")\
.setInputCols(["document"])\
.setOutputCol("sentence")
tokenizer = Tokenizer()\
.setInputCols(["sentence"])\
.setOutputCol("token")
clinical_embeddings = WordEmbeddingsModel.pretrained("embeddings_clinical", "en", "clinical/models")\
.setInputCols(["sentence", "token"])\
.setOutputCol("embeddings")
ner_model = MedicalNerModel.pretrained(model_name, "en", "clinical/models")\
.setInputCols(["sentence", "token", "embeddings"])\
.setOutputCol("ner")
ner_converter = NerConverterInternal()\
.setInputCols(["sentence", "token", "ner"])\
.setOutputCol("ner_chunk")
pipeline = Pipeline(stages=[
document_assembler,
sentence_detector,
tokenizer,
clinical_embeddings,
ner_model,
ner_converter
])
sample_texts = [[ """ Smith is a 55 years old, divorced Mexcian American woman
with financial problems. She speaks spanish. She lives in an apartment.
She has been struggling with diabetes for the past 10 years and
has recently been experiencing frequent hospitalizations due to
uncontrolled blood sugar levels. Smith works as a cleaning assistant and
does not have access to health insurance or paid sick leave.
She has a son student at college. Pt with likely long-standing depression.
She is aware she needs rehab. Pt reprots having her catholic faith
as a means of support as well. She has long history of etoh abuse,
beginning in her teens. She reports she has been a daily drinker for 30 years,
most recently drinking beer daily. She smokes a pack of cigarettes a day.
She had DUI back in April and was due to be in court this week.
""" ]]
data = spark.createDataFrame(sample_texts).toDF("text")
result = pipeline.fit(data).transform(data)
Result:
+------------------+-----+---+-------------------+ |chunk |begin|end|ner_label | +------------------+-----+---+-------------------+ |55 years old |11 |22 |Age | |divorced |25 |32 |Marital_Status | |Mexcian American |34 |49 |Race_Ethnicity | |woman |51 |55 |Gender | |financial problems|62 |79 |Financial_Status | |She |82 |84 |Gender | |spanish |93 |99 |Language | |She |102 |104|Gender | |apartment |118 |126|Housing | |She |129 |131|Gender | |diabetes |158 |165|Other_Disease | |cleaning assistant|307 |324|Employment | |health insurance |354 |369|Insurance_Status | |She |391 |393|Gender | |son |401 |403|Family_Member | |student |405 |411|Education | |college |416 |422|Education | |depression |454 |463|Mental_Health | |She |466 |468|Gender | |she |479 |481|Gender | |rehab |489 |493|Access_To_Care | |her |514 |516|Gender | |catholic faith |518 |531|Spiritual_Beliefs | |support |547 |553|Social_Support | |She |565 |567|Gender | |etoh abuse |589 |598|Alcohol | |her |614 |616|Gender | |teens |618 |622|Age | |She |625 |627|Gender | |she |637 |639|Gender | |drinker |658 |664|Alcohol | |drinking beer |694 |706|Alcohol | |daily |708 |712|Substance_Frequency| |She |715 |717|Gender | |smokes |719 |724|Smoking | |a pack |726 |731|Substance_Quantity | |cigarettes |736 |745|Smoking | |a day |747 |751|Substance_Frequency| |She |754 |756|Gender | |DUI |762 |764|Legal_Issues | +------------------+-----+---+-------------------+
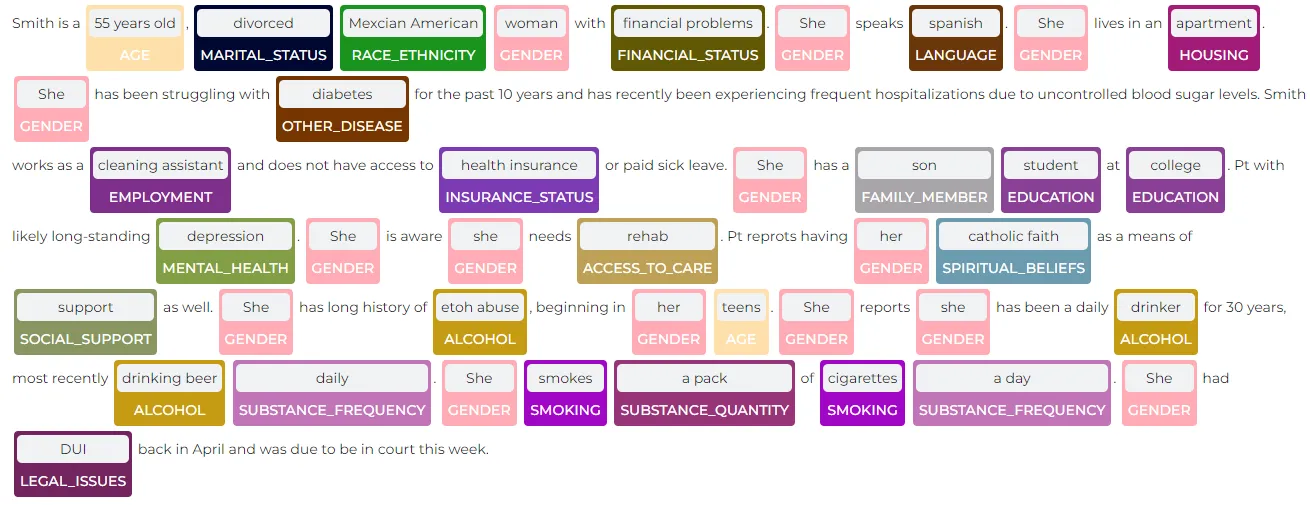
SDoH Sample Text with NER extracted
The above visualization is part of Spark NLP Library and SDoH entities are extracted with the SDoH NER model. In the above example, we can extract the patient’s financial status (financial problems) and her health insurance status (health insurance + with “absent” assertion). We can also extract the existence of social support as a spiritual belief (Catholic faith). And we can find substance usage (smoke & alcohol) status with quantity and frequency info.
You can try SDoH models with the Social Determinants of Health Colab Notebook. This notebook includes all Spark NLP Healthcare Library installations, NER pipelines, NER visualizations, and result outputs. You can also try the Social Determinants of Health Live Demo page to see models’ offline outputs at a glance.
Conclusion
Using the Social Determinants of Health NER model can save time and resources in the extraction of SDoH entities from clinical text. This can enable healthcare providers to better understand and address the social determinants that impact their patient’s health outcomes. The model can also be used in research studies to analyze the relationship between SDoH and health outcomes.
One of the key emerging trends is the integration of SDoH extraction with predictive analytics and risk stratification systems in hospitals. Many healthcare networks are increasingly using SDoH insights alongside clinical risk scores to enhance early detection of patients with elevated risk profiles. This enables providers to intervene proactively with tailored care plans, helping to reduce avoidable hospitalizations and associated costs. Another development is the growing role of multimodal NLP approaches. Instead of focusing solely on clinical text, new pipelines are increasingly integrating unstructured notes with imaging reports, lab results, and patient-reported outcomes. This holistic perspective helps identify hidden social factors that might otherwise be overlooked, such as links between food insecurity and chronic disease progression. The use of multimodal data has shown clear potential for improving the accuracy and reliability of SDoH entity recognition. Finally, the adoption of federated learning frameworks is transforming how sensitive SDoH data is processed. By training models across multiple institutions without centralizing patient data, organizations are able to strengthen privacy protections while improving model performance through access to more diverse datasets. These developments are paving the way for scalable, privacy-preserving collaboration in healthcare NLP.
In conclusion, the Social Determinants of Health NER model is a powerful tool for extracting SDoH entities from clinical text. It offers a way to quickly and accurately identify SDoH entities, which can help healthcare providers and researchers better understand the social determinants that impact health outcomes. With its constantly improving accuracy and performance, the model is a valuable asset in the field of healthcare and public health research.
FAQ
1. What SDoH categories can the model reliably extract from clinical text?
The SDoH NER covers demographics (age, gender, race/ethnicity, language), socioeconomic signals (employment, education, financial status, insurance), living conditions (housing, transportation, food insecurity), health behaviors (smoking, alcohol, substance use), social context (social support, exclusion, violence/abuse), access to care, and quality-of-life indicators. You can also use focused sub-models to target narrower domains when you need higher precision.
2. How do I improve accuracy on my hospital’s data?
Start with the released SDoH models, then fine-tune on a small, representative sample of your own notes to capture local phrasing and templates. Add assertion status and negation handling, normalize synonymous phrases (e.g., “unhoused,” “no fixed address”), and include weakly-labeled data via data augmentation to reduce variance.
3. How should I evaluate SDoH extraction before using it in workflows?
Create a stratified test set across note types (ED, discharge, social work), populations, and documentation styles. Track precision/recall/F1 at the entity level, plus error analyses for ambiguous spans and context-dependent labels; also monitor fairness by comparing performance across demographic subgroups.
4. Can SDoH outputs be used for risk stratification and care management?
Yes, map extracted entities to structured features (e.g., binary, frequency, recency) and feed them into existing risk scores or care-gap rules. Pairing SDoH features with clinical variables often improves early identification of high-risk patients and enables targeted interventions (transport vouchers, nutrition programs, benefits counseling).
5. How do we handle privacy, governance, and deployment at scale?
Run pipelines inside your secure environment, pseudonymize PHI where possible, and log model decisions for auditability. For multi-site learning without sharing raw data, consider federated training; for production, containerize the pipeline, set SLAs for throughput/latency, and monitor model drift with periodic re-evaluation and clinician feedback loops.




