
























































Spark NLP Short Blogpost Series:1
Spark NLP offers several pre-trained models in four languages (English, French, German, Italian) and all you need to do is to load the pre-trained model into your disk by specifying the model name and then configuring the model parameters as per your use case and dataset. Then you will not need to worry about training a new model from scratch and will be able to enjoy the pre-trained SOTA algorithms directly applied to your own data with transform().
Let’s see how we can use explain_document_dl pre-trained model in Python.
We start by importing the required modules.
Now, we load a pipeline model that contains the following annotators as a default:
- Tokenizer
- Deep Sentence Detector
- Lemmatizer
- Stemmer
- Part of Speech (POS)
- Context Spell Checker (NorvigSweetingModel)
- Word Embeddings (glove)
- NER-DL (trained by SOTA algorithm)
We simply send the text we want to transform and the pipeline does the work.

As you can see, we have misspelled two words: beautful and pictre
We can see the output of each annotator below. This one is doing so many things at once!


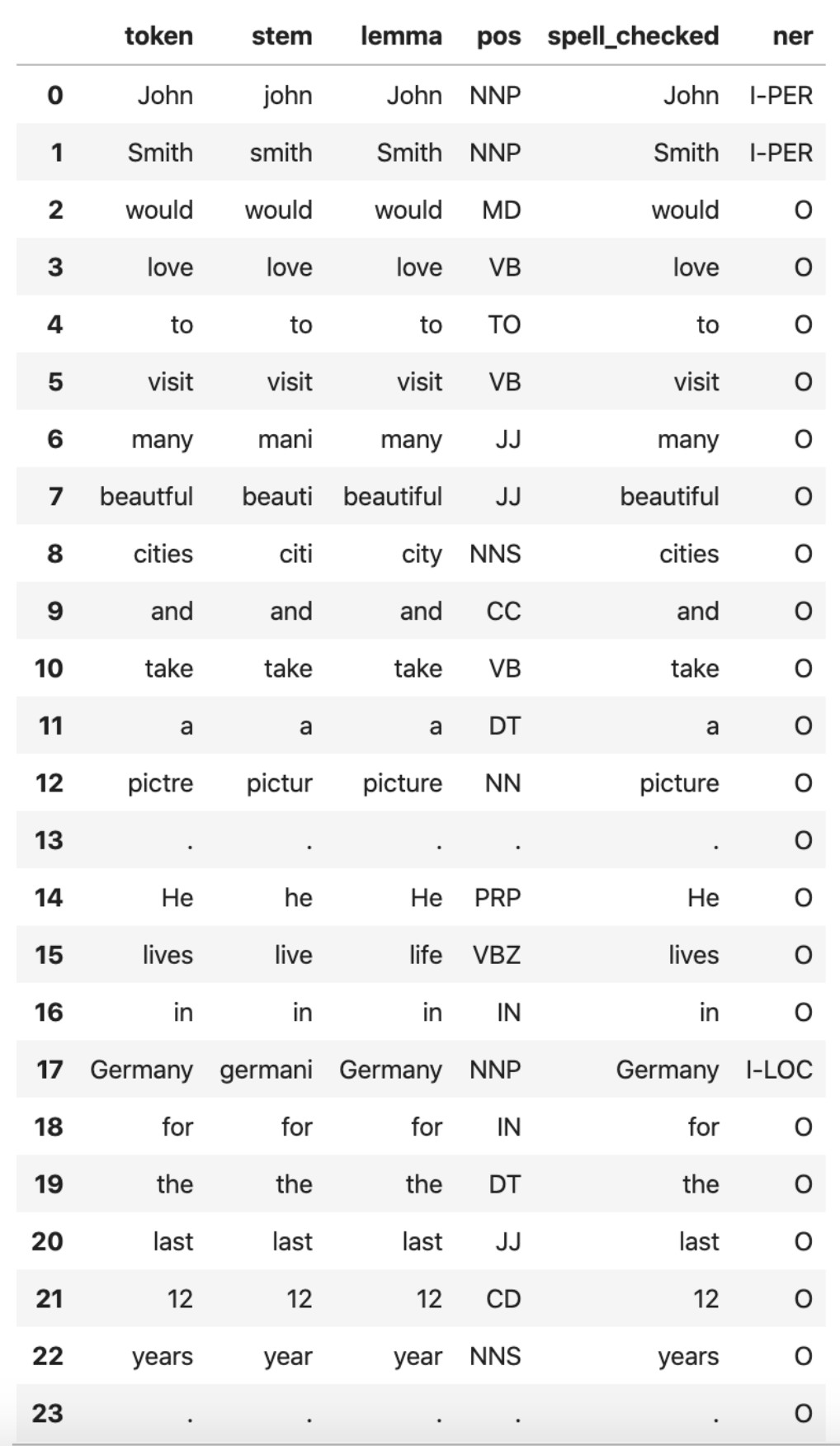
As you can see, the misspelled words are also fixed correctly.
We hope that you already read the previous articles on our official Medium page, and started to play with Spark NLP. Here are the links for the other articles. Don’t forget to follow our page and stay tuned!
With this understanding of the capabilities of Spark NLP, healthcare professionals can now harness these powerful tools to transform patient interactions and improve care outcomes. With advancements like Generative AI in Healthcare, tools such as Healthcare Chatbot are now more effective than ever, leveraging natural language processing to facilitate smoother patient interactions and more personalized care experiences.
Here is the notebook for the codes shared above.
Introduction to Spark NLP: Foundations and Basic Components (Part-I)
Introduction to: Spark NLP: Installation and Getting Started (Part-II)
Spark NLP 101 : Document Assembler




