






















































Prometheus-Eval and LangTest combine to provide an open-source, reliable, and cost-effective solution for evaluating long-form responses. Prometheus, trained on a comprehensive dataset, matches GPT-4’s performance, while LangTest offers a robust framework for testing LLM models. Together, they deliver detailed, interpretable feedback and ensure high accuracy in assessments.
Introduction
In recent years, the use of proprietary Large Language Models (LLMs) like GPT-4 for evaluating long-form responses has become the industry standard. These models, powered by vast amounts of data and sophisticated algorithms, deliver impressive evaluation capabilities, allowing practitioners to assess complex responses accurately. However, the reliance on proprietary models brings significant challenges: they are closed-source, meaning users cannot inspect or modify the underlying algorithms; they suffer from uncontrolled versioning, making it difficult to ensure consistent results over time; and they come with prohibitive costs, making them inaccessible for many organizations, especially those with large-scale evaluation needs.

generated by GPT-4o
Recognizing these limitations, we integrated PROMETHEUS, a fully open-source LLM designed to provide evaluation capabilities on par with GPT-4 while addressing the drawbacks associated with proprietary models. PROMETHEUS is built to cater to practitioners who require reliable and cost-effective evaluation solutions tailored to specific criteria, such as child-readability or other custom metrics. By leveraging an extensive dataset known as the FEEDBACK COLLECTION, which includes 1,000 fine-grained score rubrics, 20,000 instructions, and 100,000 responses generated by GPT-4, PROMETHEUS has been meticulously trained to offer precise and customizable evaluations.
What is Prometheus LLM?
Prometheus represents a major leap forward in open-source large language models (LLMs). It attains an impressive Pearson correlation of 0.897 with human evaluators using 45 customized score rubrics, closely matching the performance of GPT-4 and significantly surpassing other models like ChatGPT. In addition, Prometheus excels in human preference benchmarks, highlighting its potential as a universal reward model.
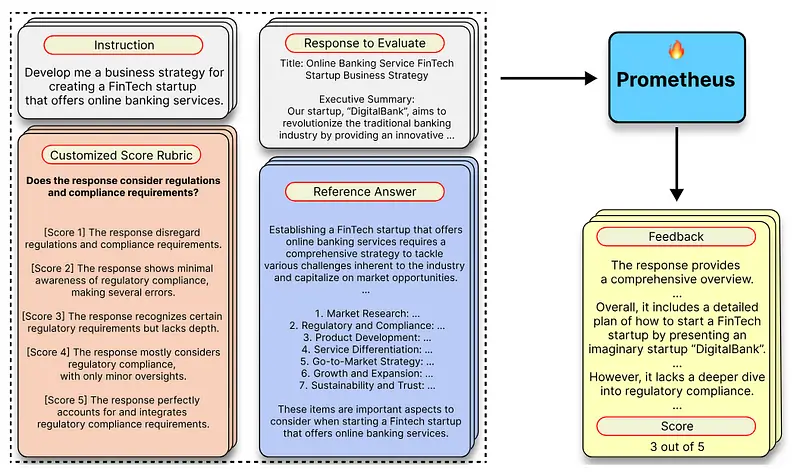
The training and evaluation framework of Prometheus is based on rigorous methodologies to ensure high accuracy and reliability. The Feedback Collection dataset, specifically designed for Prometheus, includes comprehensive reference materials, uniform lengths for reference answers, balanced score distribution, and realistic user interactions with LLMs. These considerations help mitigate biases and improve evaluation robustness. The components of the Feedback Collection include user instructions, responses to evaluate, customized score rubrics, and reference answers. The outputs are feedback, providing a rationale for the score, and the score itself, ranging from 1 to 5. Using this dataset, Llama-2-Chat (7B & 13B) was fine-tuned to create the Prometheus eval model, which closely simulates human evaluations and aligns with GPT-4 standards.
Prometheus has been tested extensively through various benchmarks, such as Feedback Bench, Vicuna Bench, MT-Bench, and FLASK Eval, under two primary grading schemes: Absolute Grading and Ranking Grading. In Absolute Grading, the model generates feedback and scores ranging from 1 to 5 based on provided instructions, responses, and reference materials. In Ranking Grading, it evaluates the quality of two given responses, determining which is superior. This comprehensive evaluation approach demonstrates Prometheus’s capability to simulate human evaluations and align with GPT-4 standards closely.
Let’s introduce the LangTest
LangTest is developed by John Snow Labs which provides a comprehensive framework for testing LLM models across various libraries and APIs. Developers can seamlessly evaluate the performance of models from John Snow Labs, Hugging Face, Spacy, OpenAI, Cohere, AI21, Hugging Face Inference API, and Azure-OpenAI LLMs. With a rich set of functionalities, it provides comprehensive support for evaluating LLM models. Developers can utilize LangTest’s extensive suite of over 100 pre-configured tests to assess various aspects of Language models, including their accuracy, robustness, and potential biases.
How to Use Langtest with the PROMETHEUS Evaluation Model
The PROMETHEUS evaluation model, when used in conjunction with Langtest, provides a powerful solution for assessing long-form responses based on custom criteria. This combination allows practitioners to leverage the robust evaluation capabilities of PROMETHEUS while utilizing the flexible and comprehensive testing framework of Langtest. Here’s how you can apply Langtest with the PROMETHEUS evaluation model effectively:
Step 1: Install Langtest
First, you need to install the Langtest library. This can be done easily using pip:
pip install langtest==2.3.0
Step 2: Create a Configuration File
Next, create a config.yaml file to define your evaluation metrics and criteria. This configuration file will guide the evaluation process, specifying the aspects to focus on and the minimum pass rates for different tests.
evaluation:
metric: prometheus_eval
rubric_score:
# The below statements can change based on the criteria
# In LangTest, we usually define Pass/Fail criteria for the tests.
# This is how we adapted the score definitions in Prometheus to align with that approach.
# Users may modify these definitions to improve evaluations if desired,
# but the primary goal is to maintain the Pass/Fail consistency required by LangTest.
'True': >-
The statement is considered true if the responses remain consistent
and convey the same meaning, even when subjected to variations or
perturbations. Response A should be regarded as the ground truth, and
Response B should match it in both content and meaning despite any
changes.
'False': >-
The statement is considered false if the responses differ in content
or meaning when subjected to variations or perturbations. If
Response B fails to match the ground truth (Response A) consistently,
the result should be marked as false.
tests:
defaults:
min_pass_rate: 0.65
robustness:
add_ocr_typo:
min_pass_rate: 0.66
dyslexia_word_swap:
min_pass_rate: 0.6
Detailed Workflow
- Task Definition: Choose the task based on your requirements as shown in the table, supported by the langtest. In this blog post, we focus on the “question-answering” task to evaluate the model.

list of tasks supported by LangTest
- Model Selection: Choose the appropriate hub based on the model you are testing. For this evaluation, we are using the GPT-3.5-turbo model from the openai hub. You must specify the model and its source hub.

supported different hubs by LangTest (some hubs backed by LangChain)
- Data Source: Define the dataset to be used for generating test cases. In this example, we use the “MedQA” dataset with a “test-tiny” split. check the predefined datasets for benchmarking click here
- Configuration: Link the
config.yamlfile, which contains the evaluation criteria and robustness tests.
from langtest import Harness
# Define the task and model
harness = Harness(
task="question-answering",
model={"model": "gpt-3.5-turbo", "hub": "openai"},
data={"data_source": "MedQA", "split": "test-tiny"},
config="config.yaml"
)
# Generate test cases, run the evaluation, and generate a report
harness.generate().run().report()
Generating and Running Tests
The harness.generate() method creates the necessary test cases based on the configuration file. The run() method executes these test cases on a given GPT-3.5-turbo model. Finally, the generated_results() method generates a detailed evaluation report using the Prometheus eval model to evaluate each response according to the defined criteria and returns its feedback and results, providing insights into the performance of the evaluated responses.
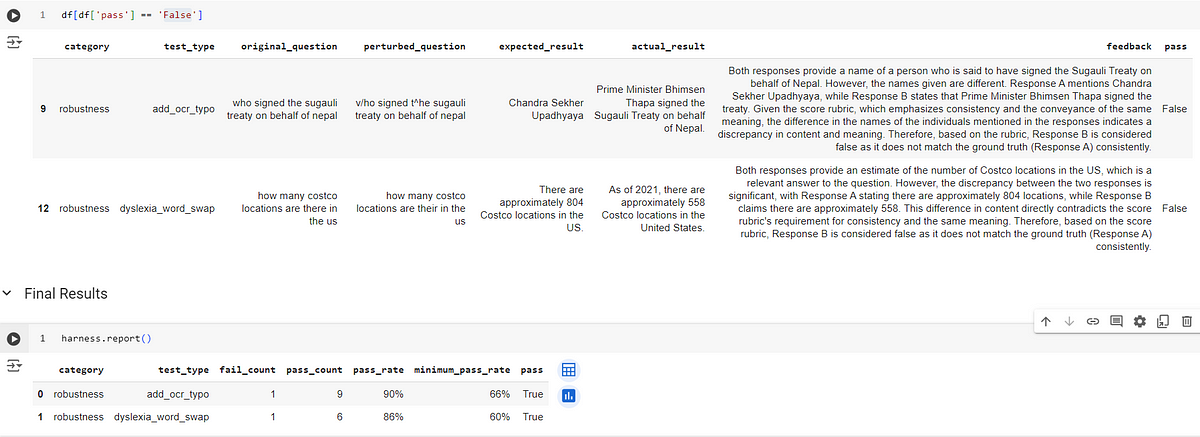
Evaluation and Reporting
Once the test cases are generated and executed, the Langtest library provides a comprehensive report detailing the performance of the responses. This report includes:
- Feedback: Detailed rationales for each score, explaining why the response received a particular rating. This feedback is akin to a Chain-of-Thought process, making the evaluation process transparent and interpretable.
- Scores: Boolean scores either True or False for each response, based on the customized score rubrics and reference answers.
By integrating the PROMETHEUS eval model with Langtest, practitioners can achieve robust and reliable evaluations tailored to specific criteria. This combination allows for detailed, interpretable feedback and ensures high accuracy in assessing long-form responses, making it an invaluable tool for large-scale evaluation tasks.

Prometheus eval model feedback on failed test

Prometheus eval model feedback on passed test
Conclusion
Evaluating Long-Form Responses with Prometheus-Eval and Langtest represents a significant advancement in the field of LLM evaluation. By providing a structured and transparent approach, it addresses the limitations of proprietary models and offers a scalable, cost-effective solution for practitioners. Whether you are evaluating educational content, customer support interactions, or any other long-form responses, the combination of PROMETHEUS and Langtest delivers high-quality, reliable results tailored to your specific needs.
For more updates and community support, join our Slack channel and give a star to our GitHub repo here.
References:
- Nazir, Arshaan, Thadaka K. Chakravarthy, David A. Cecchini, Rakshit Khajuria, Prikshit Sharma, Ali T. Mirik, Veysel Kocaman, and David Talby. “LangTest: A Comprehensive Evaluation Library for Custom LLM and NLP Models.” Software Impacts 19, (2024): 100619. Accessed July 4, 2024. https://www.softwareimpacts.com/article/S2665-9638(24)00007-1/fulltext
- David Cecchini, Arshaan Nazir, Kalyan Chakravarthy, and Veysel Kocaman. 2024. Holistic Evaluation of Large Language Models: Assessing Robustness, Accuracy, and Toxicity for Real-World Applications. In Proceedings of the 4th Workshop on Trustworthy Natural Language Processing (TrustNLP 2024), pages 109–117, Mexico City, Mexico. Association for Computational Linguistics.
- Kim, Seungone, Juyoung Suk, Shayne Longpre, Bill Y. Lin, Jamin Shin, Sean Welleck, Graham Neubig, Moontae Lee, Kyungjae Lee, and Minjoon Seo. “Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models.” ArXiv, (2024). Accessed July 4, 2024. /abs/2405.01535.
- Kim, Seungone, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, et al. “Prometheus: Inducing Fine-grained Evaluation Capability in Language Models.” ArXiv, (2023). Accessed July 10, 2024. /abs/2310.08491.
- Prometheus eval model in HuggingFace Link here
- check out the Langtest website





