
























































John Snow Labs’ small medical Language model (MedS) outperformed GPT-4o in factuality (by 5–10%), clinical relevance, and conciseness across tasks like summarization, information extraction, and biomedical Q/A, showcasing the impact of targeted fine-tuning on smaller, domain-specific models for healthcare.

Challenges in Trustworthy LLM Evaluation
The advent of Large Language Models (LLMs) has revolutionized natural language processing across various domains. Innovations such as Low-Rank Adaptation (LoRA) have significantly enhanced the accessibility and adaptability of these models. By minimizing the number of trainable parameters, LoRA enables efficient domain-specific fine-tuning, even with limited computational resources, while mitigating issues like overfitting and catastrophic forgetting. As a result, compact models refined through LoRA can often match or outperform their larger, general-purpose counterparts in specialized tasks. This paradigm shift has democratized LLM deployment, empowering researchers and organizations to leverage these tools without requiring extensive computational infrastructure. However, the proliferation of domain-specific LLMs has brought to light critical challenges in their evaluation.
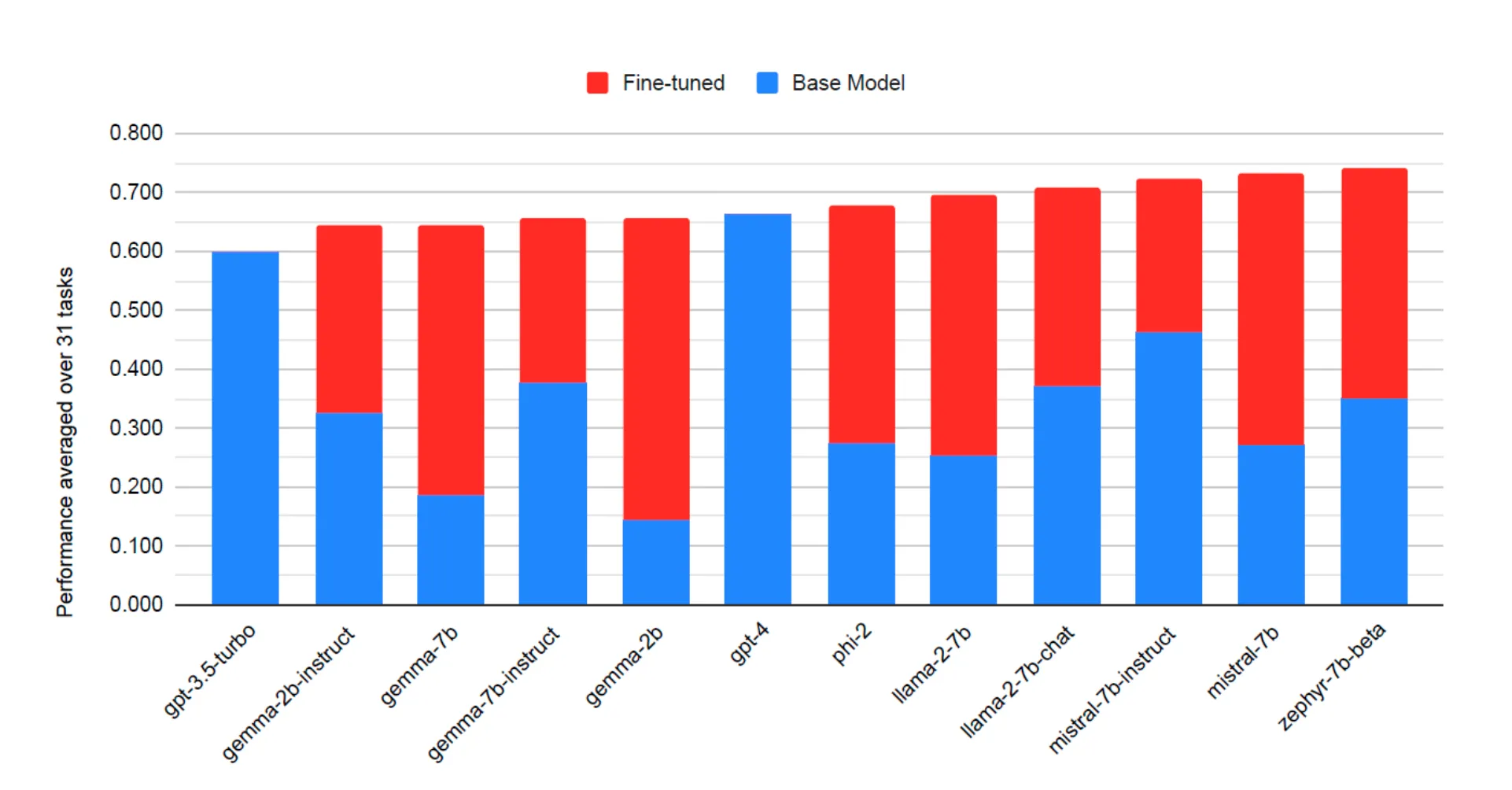
Average model performance for GPT-3.5, GPT-4, and 310 LLMs, before and after fine-tuning with LoRA, across 31 different tasks and 10 different base models. LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average (figure taken from (J. Zhao et al., 2024))
Limitations of Current Evaluation Methods
Evaluating LLMs presents a multifaceted challenge, encompassing the complexities of scoring, reproducibility, and real-world applicability. Existing methods include multiple-choice evaluations, string matching heuristics, the use of other LLMs as evaluators, and human annotations. While multiple-choice evaluations are straightforward and cost-effective, they fail to capture real-world performance nuances, particularly in open-ended tasks like free-text generation or chain-of-thought reasoning. Moreover, these methods lack compatibility with scenarios where users expect models to generate comprehensive answers rather than selecting predefined options.
Metrics such as log likelihood and perplexity are also employed for evaluation, yet they come with inherent limitations. Log likelihood measures the truthfulness of individual tokens but provides a narrow assessment of overall model performance. Perplexity, while useful for evaluating a model’s fit to a distribution, is unsuitable for instruction-tuned models and often diverges from real-world generation quality. Additionally, these metrics are tokenizer-specific and require meticulous tuning, further complicating their application.
Challenges in Open-Text Generation Evaluation
Free-text generation remains a cornerstone of LLM applications, including summarization and open-ended question answering. However, evaluating the quality of free-form text is inherently difficult due to the need for nuanced judgment. Current evaluation techniques often rely on heuristics to extract measurable answers, leading to outputs that may be partially correct or patterned without fully addressing the task. This approach limits the ability to determine the true quality of generated responses.
Reproducibility adds another layer of complexity. Ideally, published results should include sufficient detail for replication within a narrow margin of error. However, standard evaluation libraries and test sets often fail to reflect real-world scenarios, compromising reproducibility. While LLMs have been explored as potential evaluators, this introduces a circular validation issue. If an LLM is sufficiently trained for domain-specific evaluation, it is arguably better suited for direct application to the task rather than serving as a judge.
The Importance of Domain-Specific Evaluation
The need for tailored evaluation methods is particularly critical in sensitive domains like healthcare, where accuracy and reliability are paramount. In medical applications, errors can have serious consequences, underscoring the importance of evaluations conducted by domain experts. Existing evaluation methods, primarily relying on multiple-choice questions and synthetic datasets, fail to address the complexities of real-world clinical applications. Critical aspects such as understanding complex patient cases, interpreting medical jargon, and generating coherent summaries are often overlooked.
Recent reviews, such as those by Bedi et al., highlight significant gaps in current evaluation practices for medical LLMs. Most studies prioritize accuracy metrics, often at the expense of assessing the factuality, relevance, and impact of model outputs. Moreover, there is a notable overreliance on benchmark datasets, which poses risks of data contamination and inflated performance metrics. This is particularly problematic in medical contexts, where benchmarks often consist of simplified tasks that do not reflect the intricacies of clinical practice.
Toward a More Comprehensive Evaluation Framework
The shortcomings of current evaluation methods highlight the need for a more robust and clinically relevant framework for LLM evaluation. Such a framework must go beyond synthetic datasets and generic benchmarks to incorporate real-world clinical text and domain-specific scenarios. Evaluations should prioritize not only accuracy but also linguistic accuracy, contextual relevance, and practical applicability. By addressing these challenges, the AI community can ensure that LLMs deployed in critical domains like healthcare meet the stringent requirements necessary for trust and efficacy in real-world applications.
Introducing a Comprehensive Medical LLM Evaluation Framework
Recognizing the limitations and unique requirements of medical LLMs, we developed a comprehensive evaluation framework specifically tailored for assessing LLM performance in medical applications.
This evaluation study is also presented as a keynote talk at NLP Summit in Oct, 2024 by Veysel Kocaman, PhD, the CTO of John Snow Labs.
Assembling a Panel of Medical Experts
We formed a diverse panel of medical experts from various specialties, including internal medicine, oncology, neurology, and dentistry. This multidisciplinary approach ensured that our evaluation process incorporated a wide range of clinical perspectives and expertise. The involvement of these specialists, who also possess extensive knowledge of natural language processing (NLP) and practical experience in its application, was crucial for assessing the clinical relevance and factual accuracy of the LLM-generated outputs in the context of real-world medical practice.
Assessment of LLM Performance Across Key NLP Tasks
To effectively evaluate the capabilities of the language models, we conducted a thorough assessment across four critical medical natural language processing (NLP) tasks: medical summarization, question answering in clinical notes, biomedical research, and open-ended question answering (closed-book) in medical contexts. Each task was selected based on its relevance to clinical workflows and its potential impact on patient care. Our evaluation framework was grounded in three fundamental pillars:
- Factuality: Assesses the accuracy of information.
- Clinical Relevance: Evaluates the applicability of the information to real-world scenarios.
- Conciseness: Measures how effectively the models convey necessary information without unnecessary verbosity.
Mitigating Data Contamination Issues
To address concerns regarding data contamination and ensure an unbiased evaluation, we generated 500 novel clinical test cases specifically tailored for LLM tasks. These test cases were developed from scratch to avoid any overlap with existing benchmark datasets that may have been used during model training. By creating unique scenarios that reflect actual clinical situations, we aimed to provide a fair assessment of the models’ true capabilities in handling complex medical information.
Ensuring Scientific Rigor
To uphold scientific rigor throughout our evaluation process, we employed a randomized blind experimental design that incorporated various comparative tests. This design minimized bias by ensuring that evaluators were unaware of which model generated each response during assessment. Additionally, we implemented measures to track the validity of our results, including:
- Inter-annotator agreement analysis to assess consistency among expert evaluations.
- Inter-class correlation coefficient calculations to quantify reliability across different raters.
- Washout period assessments to evaluate the stability of model performance over time, providing insights into reproducibility.
Results of the Study
This study presents the results of applying our evaluation framework to compare GPT-4o (OpenAI et al., 2024), trained by OpenAI, with two healthcare-specific LLMs trained by John Snow Labs: MedS, which has 8 billion parameters, and MedM, which has 70 billion parameters. The results demonstrated that after fine-tuning on a domain-specific dataset, these specialized LLMs outperformed GPT-4o in the measured tasks, notably using a model with less than 10 billion parameters that can be deployed on-premise. These findings validate our proof of concept for evaluations, confirming that our methodology is effective. Furthermore, they support the theory that smaller models trained with domain-specific data can indeed surpass larger models, a hypothesis proven through our rigorous benchmarking process.
Through a randomized blind study conducted with medical doctors as evaluators, we assessed LLM performance based on three essential dimensions — factuality, clinical relevance, and conciseness. This approach aligned with best practices in clinical research and acknowledged the inherent complexity of medical information, necessitating comprehensive evaluation metrics. Our methodology aimed to transform these theoretical insights into actionable practices within healthcare. By providing a structured framework for evaluation, this approach not only facilitated the effective integration of LLMs into clinical workflows but also highlighted critical areas for enhancement, ensuring that these models could reliably support healthcare professionals in delivering high-quality patient care.
Methodology
Data
For this study, we generated 500 test cases, 100 of which were reserved for inter-annotator agreement (IAA) analysis and evaluated by four Subject Matter Expert (SME) physicians. These medical questions were created from scratch, adhering to the principle that “when a measure becomes a target, it ceases to be a good measure.” This concept is particularly relevant in LLM evaluation, where mainstream benchmarks often risk contamination due to models encountering benchmark datasets during training.
Research has shown that many prominent open-source LLMs have been exposed to benchmark datasets during training, leading to inflated and potentially unreliable performance scores. For example, Deng et al. demonstrated that ChatGPT could guess missing options in a benchmark with 57% accuracy, raising concerns about data contamination. Similarly, studies have detected test set contamination in language models by analyzing canonical orderings compared to shuffled examples. By creating a unique dataset tailored to medical LLM tasks, this study aimed to minimize such risks and provide a fair assessment of model performance.
Medical Experts
Medical professionals played an essential role in evaluating the LLMs due to their domain-specific expertise, accuracy, and ability to assess potential risks. Studies have shown that medical experts significantly outperform LLMs in diagnostic accuracy and clinical decision-making. For instance, physicians achieved an 82.3% accuracy compared to 64.3% for Claude3 and 55.8% for GPT-4 on identical medical questions.
To ensure a diverse range of expertise, we convened a panel comprising:
- A Professor of Human Pathophysiology (MD, PhD) with 25 years of clinical experience and 2 years in AI solutions.
- A Neurologist (MD) with 1 year of clinical practice and 3 years in AI solutions.
- An ECFMG-certified Hematologist-Oncologist (MD) with 3 years of clinical experience and 3 years in AI solutions.
- A Dentist (DDS) with 3 years of clinical practice and 5 years in AI solutions.
This multidisciplinary team brought a wealth of medical and AI expertise, ensuring robust and nuanced evaluations.
Evaluation Rubrics
Our evaluation framework was built on three critical rubrics:
- Factuality: Focuses on the accuracy and correctness of LLM-generated answers. Evaluators assessed the veracity of the information, referencing medical literature and clinical guidelines to ensure reliability. The absence of false or misleading information was also a key consideration.
- Clinical Relevance: Examines the applicability and utility of the LLM-generated information in real-world clinical scenarios. This criterion evaluated how well the responses addressed specific medical questions and their practicality in patient care.
- Conciseness: Measures the ability of the LLM to convey necessary information succinctly and clearly. Evaluators assessed whether the responses effectively summarized complex concepts without unnecessary jargon or verbosity, ensuring the information was easily digestible in clinical settings.
Test Setup
We conducted randomized blind evaluations to minimize potential biases. By shuffling the order of model responses for each question, we aimed to prevent evaluators from recognizing patterns and introduced a fairer comparison of outputs. Our primary evaluation method was pairwise comparison, involving GPT-4o, MedS, and MedM. This method simplifies decision-making by comparing two models at a time, mimicking real-world decision processes.
We augmented the comparison framework with four options: “Model A,” “Model B,” “Neutral,” and “None.” This allowed evaluators to indicate preferences, recognize similarities, or highlight when none of the responses met required standards. This nuanced approach provided richer insights into the strengths and weaknesses of each model.
By employing these rigorous methodologies, we aimed to establish a reliable and robust framework for evaluating medical LLMs, ensuring their outputs are accurate, relevant, and applicable to real-world clinical workflows.
Annotators/ evaluators used this Excel sheet to mark their preferences.
Clinical Tasks Evaluation
Clinical Summarization
Clinical summarization (CS) is a critical task in healthcare that involves distilling and synthesizing complex medical information into concise, accurate, and actionable summaries. A well-adapted large language model (LLM) capable of producing CS can match the expertise of medical professionals (Van Veen et al., 2024), enabling healthcare providers to efficiently interpret patient information and make informed decisions (Ben Abacha et al., 2023). Evaluating language models on CS tasks provides valuable insights into their capacity to process and interpret large volumes of medical data, significantly enhancing the efficiency of healthcare delivery.
Information Synthesis: A focal point of CS evaluation is the ability to extract and combine relevant details from diverse sources such as electronic health records, laboratory results, and clinical notes. Effective CS requires a deep understanding of medical terminology, procedures, and the relationships between health factors. Additionally, understanding the chronology of medical events and their implications for patient care highlights the need for temporal reasoning capabilities within these models.
Example Questions:
- Summarize the patient’s medical history and initial presentation: A model must extract details from various clinical notes, laboratory results, and imaging reports to provide a cohesive summary of a patient’s condition at the time of admission.
- Summarize the final diagnosis of the lesion and the patient’s follow-up and recovery after surgery: This task requires the model to trace the diagnosis process, summarize surgical interventions, and highlight key recovery milestones.
Our comparative analysis of an 8 billion parameter model fine-tuned on medical data and GPT-4o revealed significant performance differences:
- Factuality: MedS was preferred 47% of the time, compared to 25% for GPT-4o, with 22% rated as equal.
- Clinical Relevance: MedS was favored in 48% of cases, versus 25% for GPT-4o.
- Conciseness: MedS outperformed GPT-4o with a preference rate of 42% versus 25%.
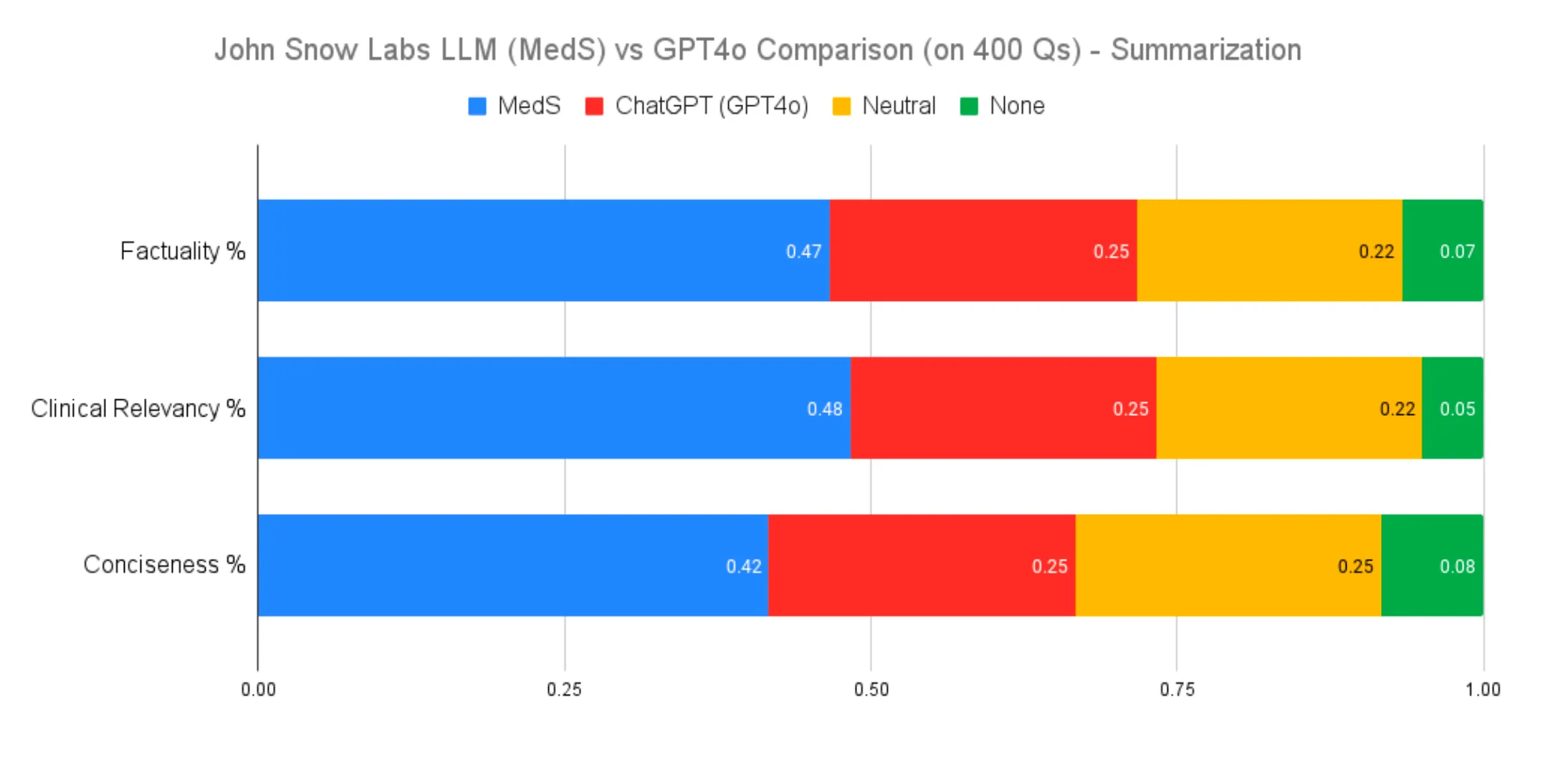
Clinical Text Summarization Performance Comparison
Evaluations included tasks such as summarizing a patient’s medical history and summarizing the final diagnosis and follow-up after surgery. These results underscore the value of domain-specific fine-tuning for improving model performance in specialized fields like medicine.
Clinical Information Extraction
Clinical question-answering (Q/A) tasks are vital for evaluating language models in the medical domain. This task involves answering specific clinical questions based on provided context, such as “What were the bone marrow smear findings?” or “What procedures did the patient undergo?” These tasks assess a model’s ability to interpret clinical data accurately.
Example Questions:
- ‘What were the bone marrow smear findings?’: The model must identify and summarize diagnostic details from clinical notes, such as the presence of atypical cells or hematological abnormalities.
- ‘What procedures did the patient undergo?’: The model must extract procedural details from surgical reports, noting the sequence and type of interventions performed.
Performance comparisons showed:
- Factuality: MedS exhibited a 10% advantage (35% vs. 24%) over GPT-4o, with 33% neutral evaluations.
- Relevance and Conciseness: MedS demonstrated a 12% and 13% lead, respectively, highlighting its strength in domain-specific applications.
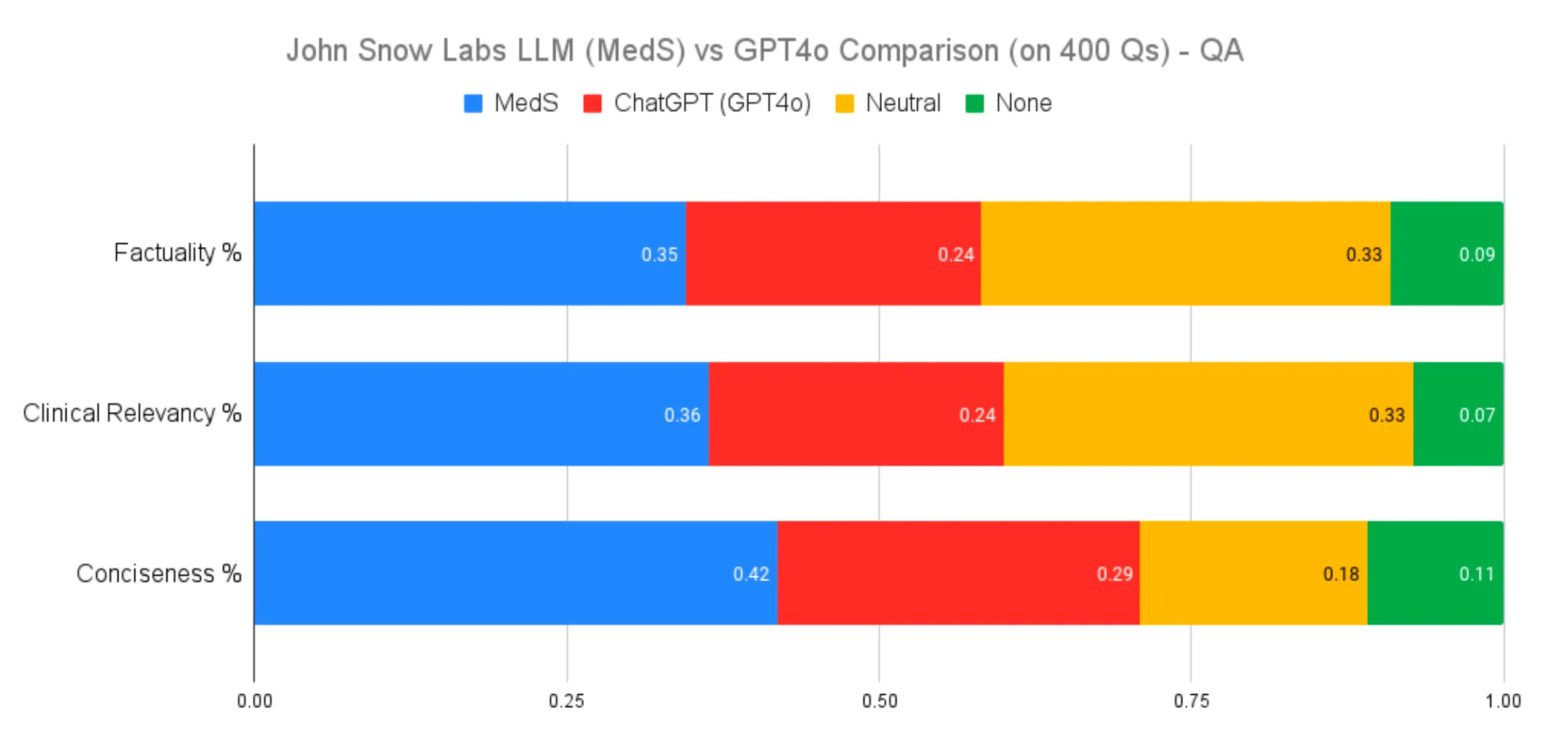
Clinical Information Extraction Performance Comparison
Biomedical Question Answering
Biomedical Q/A tasks evaluate a model’s ability to interpret scientific literature and research findings. These tasks include answering questions such as “What biomarkers are negative in APL cases?” or “Why is chemotherapy the main treatment for TNBC patients?” By focusing on biomedical research, these tasks test a model’s ability to synthesize complex medical information.
Example Questions:
- ‘What biomarkers are negative in APL cases?’: The model is required to identify and summarize relevant findings from research articles.
- ‘Why is chemotherapy the main treatment for TNBC patients?’: This task evaluates the model’s understanding of treatment rationales and disease mechanisms based on scientific evidence.
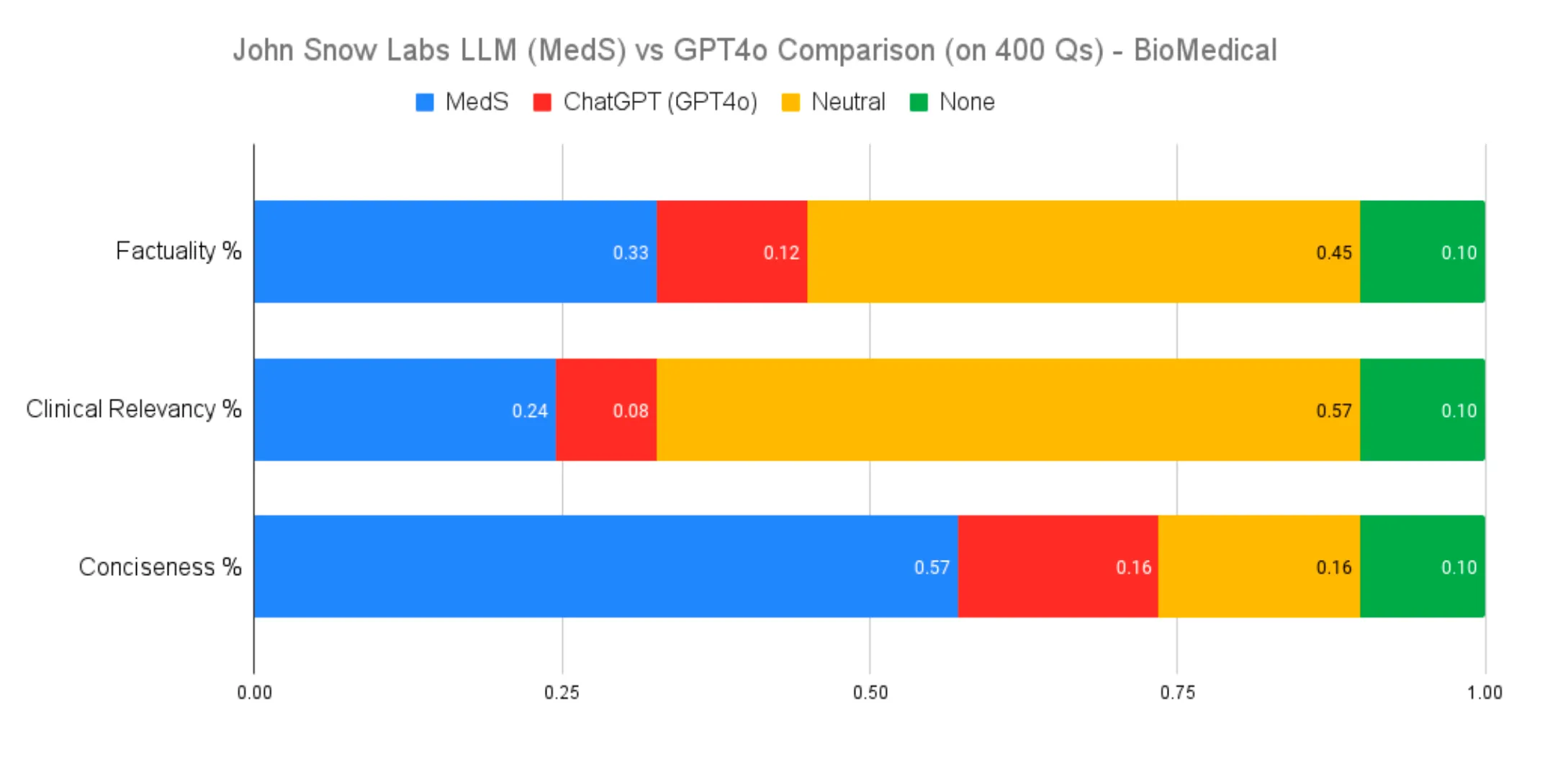
Biomedical Question Answering Performance Comparison
MedS consistently outperformed GPT-4o in factuality and contextually relevant tasks, demonstrating the impact of fine-tuning on specialized datasets for improving accuracy and utility.
Open-Ended Medical Question Answering
Open-ended Q/A tasks assess the depth of understanding and ability to navigate complex medical topics. While GPT-4o’s broader training data provided advantages in diverse questions, MedS excelled in factual accuracy within its specialized domain, outperforming GPT-4o by 5 percentage points in this metric. These results highlight the trade-offs between specialized and generalist models, emphasizing the importance of task-specific training in AI model performance.
Example Questions:
- ‘What biopsy techniques confirm malignant bone tumors?’: The model must synthesize procedural and diagnostic knowledge to provide a comprehensive answer.
- ‘Are there any over-the-counter sleep aids that contain barbiturates?’: This question requires the model to integrate pharmacological knowledge with regulatory considerations.
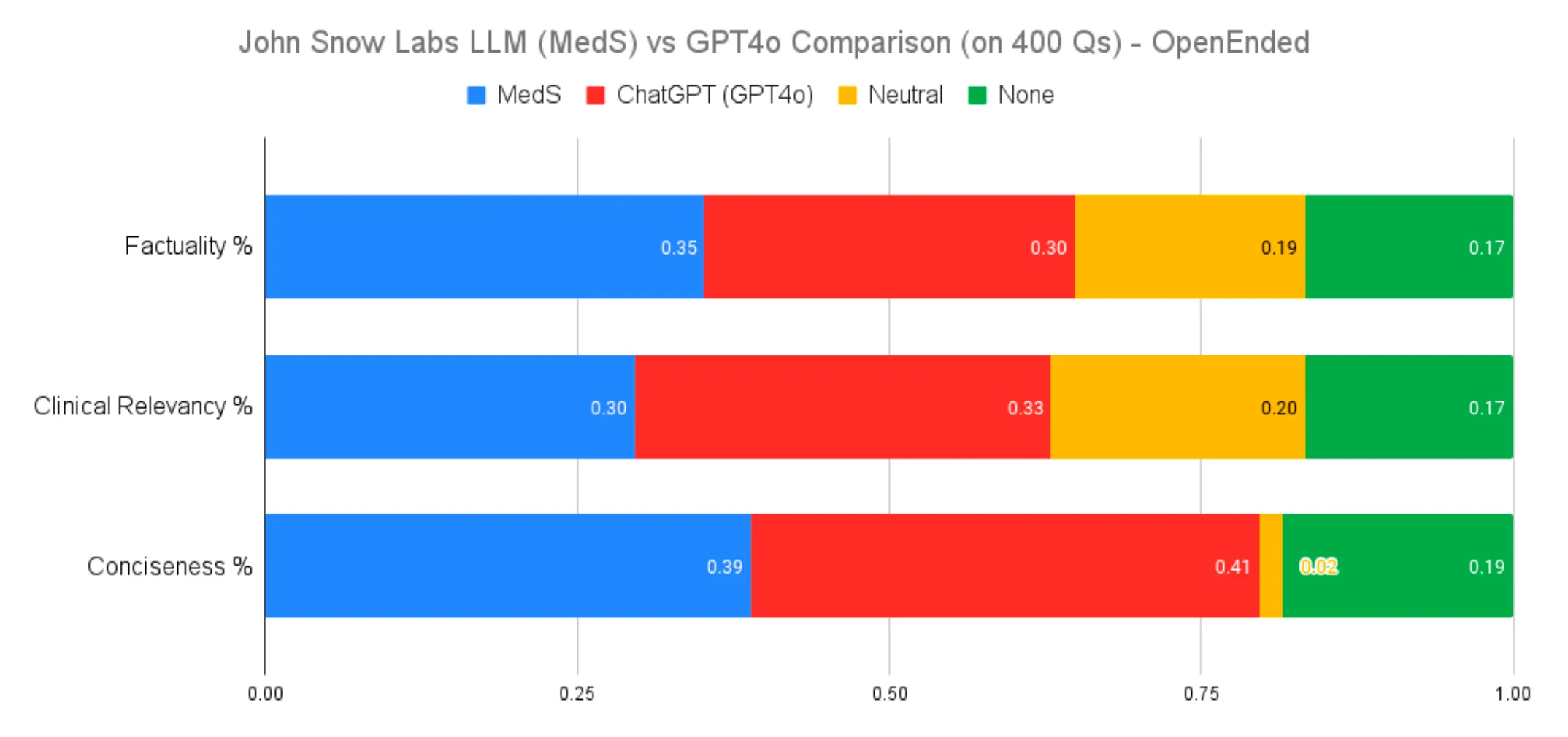
Open-Ended Medical Question Answering Performance Comparison
When evaluating clinical relevancy for open-ended medical questions without specific context, our 8-billion-parameter model fell short of GPT-4o’s performance. This result is not unexpected, given the fundamental differences in the training objectives and datasets of the two models. GPT-4o, as a generalist model trained on an expansive and diverse dataset, benefits from a broad knowledge base that proves advantageous in addressing a wide range of medical questions without contextual anchors.
In contrast, our model is finely tuned for targeted biomedical tasks, where it excels. However, its specialization means it is not optimized to handle the entire spectrum of global medical knowledge as effectively. Despite this, our model demonstrated superior factual accuracy, outperforming GPT-4o by 5 percentage points in this metric — a testament to its precision in its specialized domain.
This comparison highlights the inherent trade-offs between specialized and generalist models. It underscores the critical role of context and task-specific training in achieving optimal AI performance for different use cases.
Overall Metrics
Clinical Summarization
- Factuality: MedS was preferred 47% of the time versus 25% for GPT-4o.
- Clinical Relevance: MedS outperformed GPT-4o with 48% preference compared to 25%.
- Conciseness: MedS led with 42% preference, compared to 25% for GPT-4o.
Clinical Information Extraction
- Factuality: MedS showed a 10% advantage (35% vs. 24%) over GPT-4o, with 33% of evaluations being neutral.
- Relevance: MedS led by 12%, demonstrating stronger domain applicability.
- Conciseness: MedS held a 13% lead, reflecting efficient information presentation.
Biomedical Question Answering
- Factuality: MedS consistently outperformed GPT-4o in identifying and synthesizing relevant findings.
- Contextual Accuracy: MedS excelled in tasks requiring integration of biomedical knowledge, showcasing the value of fine-tuning.
Open-Ended Medical Question Answering
- Factuality: MedS achieved a 5% higher accuracy than GPT-4o, emphasizing precision in specialized domains.
- Clinical Relevance: GPT-4o’s generalist capabilities showed an advantage in broader knowledge coverage, but MedS maintained a strong presence in accuracy and context-specific tasks.
Conclusions
For over a decade, John Snow Labs has been at the forefront of healthcare innovation, delivering AI solutions that address the sector’s unique challenges. This legacy now extends into the realm of large language models (LLMs), where our healthcare-specific models are proving to be strong contenders against larger, general-purpose commercial models.
Our latest results demonstrate that size isn’t everything. By combining domain expertise with advanced data curation, optimization techniques, and fine-tuning strategies, John Snow Labs has developed an 8-billion-parameter medical LLM that competes head-to-head with larger models like GPT-4o. Not only did our model outperform GPT-4o in key metrics such as factuality (by 5 percentage points) and conciseness (by over 10%), but it also achieved these results while being deployable on-premise — ensuring compliance with strict healthcare privacy standards and enabling cost-efficient operation.
These achievements underscore a paradigm shift in the development of LLMs: success in healthcare AI is not merely about building bigger models but about crafting smarter ones. By leveraging domain-specific data, targeted fine-tuning, and optimization, we’ve proven that specialized models can excel in critical applications, even surpassing generalist counterparts in delivering accurate, concise, and clinically relevant responses.
John Snow Labs’ commitment to precision and privacy has always been at the heart of our mission, and our medical LLMs are no exception. These models are the culmination of years of expertise in healthcare AI, built to meet the unique demands of the field. Our success in this space demonstrates our ability to punch well above our weight and deliver world-class solutions tailored to the needs of medical professionals and researchers.
This study not only validates our approach but also highlights the potential of specialized LLMs to revolutionize healthcare. As the industry evolves, John Snow Labs will continue leading the way, shaping AI solutions that combine innovation, expertise, and real-world impact.





