

























































The realm of Natural Language Processing has been growing exponentially, bringing about a host of advancements that are pushing the boundaries of technology and its application. The NLP Lab, a No-Code prominent automatic annotation tool in this field, has been at the forefront of such evolution, constantly introducing cutting-edge features to simplify and improve document analysis tasks. Among its many advances, the Section Based Annotation feature stands out and facilitates annotators and machine learning models to work with more efficiency and accuracy. The recently published enhancements of this feature have significantly boosted its utility when dealing with large documents.
What is Section-Based Annotation?
Section Based Annotation comes into play when annotating large documents. Traditional annotation methods become daunting in these cases due to the volume of text involved. Here is where Section Based Annotation makes a significant difference. It aids annotators and models to zero in on the relevant sections of the documents to be annotated while disregarding the rest. This ability to focus solely on the relevant sections eliminates wasted time spent on unnecessary content, resulting in enhanced productivity and decreased computing time.
Annotators have two options when determining relevant sections within a document: they can either meticulously specify these sections manually or leverage the automatic detection feature. The latter is particularly noteworthy, as it utilizes rules that users define during the project’s initial configuration phase. These rules are not set in stone; they offer the flexibility to be refined or adjusted as required throughout the entire duration of a project. This dynamic nature ensures that, as the project evolves or the context changes, the section detection remains relevant and aligned with the project’s objectives.
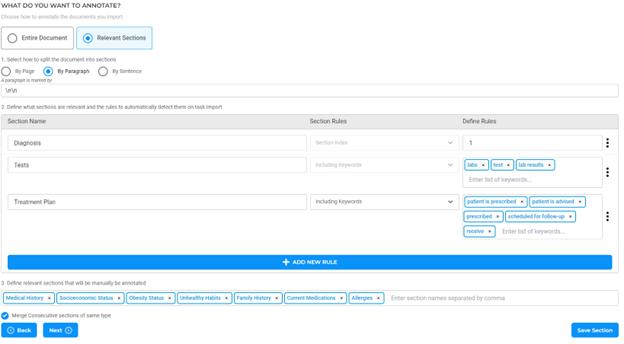
Automatic Section Identification
The NLP Lab has made section identification a breeze. It supports document splitting based on pages, paragraphs, or even sentences. These splits are then analyzed using indexes, keywords, regex-based rules, or classifiers to identify the sections relevant to the task at hand.
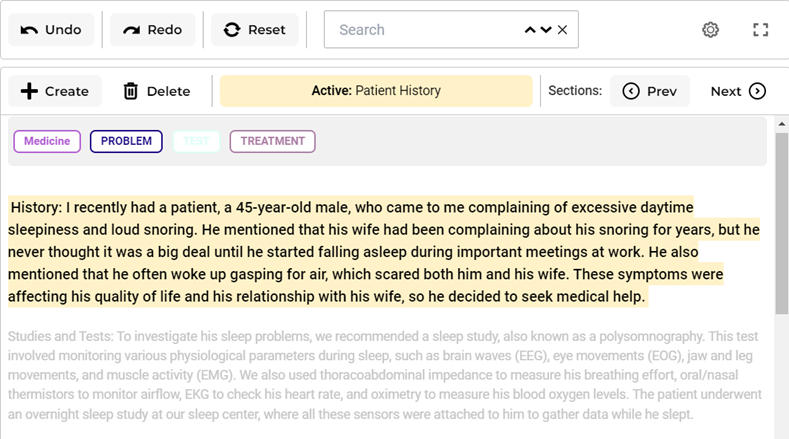
During model training, only the annotations from the relevant sections are used as training data. This focused approach has drastically slashed the required training time, preserving crucial computational resources and accelerating project timelines.
Enhanced Features
The NLP Lab has taken Section Based Annotation a step further, to provide a more streamlined user experience and more efficient workflows.
Task Splitting with External Services
Why not combine the power of other external tools or services with the power of NLP Lab to slice and dice content based on rules, or to organize, pre-annotate and train models using only content that is relevant?
Imagine you’re tasked with extracting specific clauses from a hefty real estate contract, let’s say one spanning over 100 pages. These clauses often determine specific conditions that must be met before the sale can be finalized, a critical aspect for both parties. Due to the structural nature of such contracts, this section of interest, often labeled “Contingencies and Clauses”, is usually tucked away within the last few pages.
Instead of tediously combing through the entire document, a smarter tactic can be adopted. By using an external service, such as ChatGPT, or even custom code, you can scan the last two-three pages of the contract and determine the start and end index of the “Contingencies and Clauses” section. This ensures that we zone in on the exact portion of the contract detailing the conditions that protect both the buyer and the seller, ensuring that certain criteria are satisfied before the transaction is completed. If these contingencies are not met, one or both parties may have the right to back out of the contract without facing legal consequences.
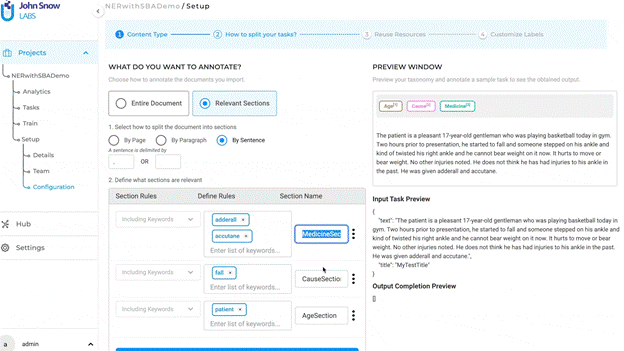
With the boundaries of the section accurately identified, you can easily import both the contract and the section specifics into the NLP Lab platform. The image below shows an example of the expected format for section defitions. Now, rather than being overwhelmed by the entirety of the 100+ page contract, the focus is solely on annotating the clauses within the ” Contingencies and Clauses ” section.

This pinpointed approach not only saves invaluable time but also ensures the accuracy of our data extraction model by concentrating on key sections and synergizing the prowess of NLP Lab with external services and tools.
Advanced Filtering in Annotation Screen
With the introduction of the Section Based Annotation feature, the annotation screen was set to filter out the list of available labels/choices based on their association with the active sections. This setup can be conveniently accomplished via the project configuration page, which provides an intuitive UI for label customization.
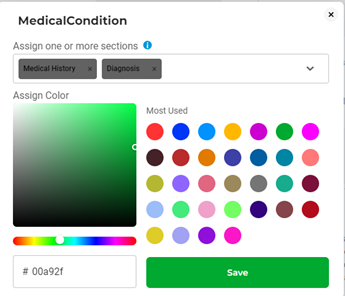
Furthermore, in Section-Based Annotation projects, users have the flexibility to combine Deep Learning (DL) models, rules, and prompts to pre-annotate sections in alignment with their distinct taxonomies. By segmenting tasks into pertinent sections, the pre-annotation process utilizes the trained and deployed models to produce predictions tailored to these specific text segments. This approach greatly optimizes the pre-annotation procedure, allowing users to capitalize on the accuracy and efficiency of predictions sourced from DL models, LLM prompts, and established rules.
Preannotations for Union of Sections
This enhancement ensures that pre-annotations cover all relevant sections, be it imported from outside sources, manually added by annotators, or automatically detected by the tool. It offers a more comprehensive coverage, allowing annotators to work seamlessly across multiple sections.
With this feature, collaboration is enhanced, and all points of view are taken into account during pre-annotation, resulting in a more precise and efficient annotation process.
Imagine there’s a task Task-1, and two annotators, Annotator-1 and Annotator-2, are working on it. Annotator-1 decides to customize the sections and manually deletes all the relevant sections generated through section rules. Instead, he adds a new relevant section manually. On the other hand, Annotator-2 prefers to keep the sections automatically detected and also manually creates a new relevant section, different from what Annotator-1 added. Now, when the project manager runs pre-annotation on Task-1, the pre-annotation process will consider the union of sections added by both annotators, along with the relevant sections generated from the section rules or imported from external sources.
To further optimize the annotation experience, NLP Lab provides a checkbox “Filter pre-annotations according to my latest completion” within the Predictions card on the right-hand side of the labeling screen. Enabling this option ensures that the pre-annotation process only includes sections present in the latest completion of the current user.
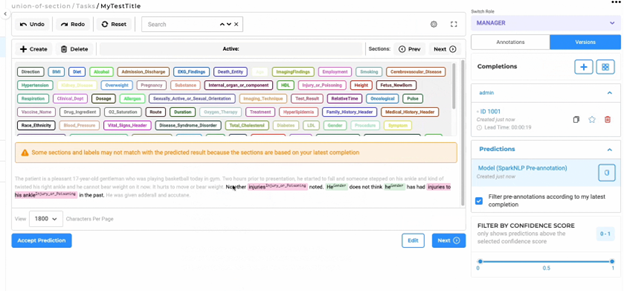
Auto resplit for Imported Tasks
In a highly dynamic project environment, the rules for splitting tasks may change over time. NLP Lab has catered to this by enabling automatic re-splitting of already split tasks when the rules change. So evertyime a rule is tweaked, a new one is added or removed, a mapping between a label and a particular section is created or changed, NLP Lab detects the change and offers to re-split the tasks with a singe click of a button! The choice is to leave existing tasks un-touched and apply the new splitting rules from that point onward or to apply the new rules across all tasks.
This feature removes the need for manual intervention, saving time and maintaining consistency across the project.
Conclusion
These innovations are aimed at optimizing the process of section-based annotation, making it more flexible, efficient, and user-friendly. The NLP Lab’s commitment to continually enhancing their services, keeping up with the needs of the users and the industry, speaks volumes about their dedication. Whether you’re an individual annotator or an organization running large-scale projects, these improvements to the Section Based Annotation feature will undoubtedly elevate your productivity and the quality of your work.
Getting Started is Easy
The NLP Lab is a free text annotation tool that can be deployed in a couple of clicks on the AWS, Azure or OCI Marketplaces, or installed on-premise with a one-line Kubernetes script.
Get started here: https://nlp.johnsnowlabs.com/docs/en/alab/install
Start your journey with NLP Lab and experience the future of data analysis and model training today!





