
























































In today’s enormous digital environment, where information flows at breakneck speed, determining the sentiment concealed inside textual data has become critical. Sentiment analysis, a branch of natural language processing (NLP), has evolved as an effective method for determining the underlying attitudes, emotions, and views represented in textual information. Long Short-Term Memory (LSTM) networks have received substantial attention for their capacity to interpret and analyze sequential input, making them a vital tool in sentiment research. This article will investigate the use of the PyTorch framework to create an LSTM-based model for sentiment analysis, diving into the complexities of its design and its use in analyzing the sentiments encoded inside the famed IMDB dataset.
Understanding the IMDB Dataset and Sentiment Analysis
The Internet Movie Database (IMDB) dataset, which contains a wealth of movie reviews and ratings, is a great setting for sentiment analysis. The IMDB dataset reflects a complex tapestry of ideas, thoughts, and critiques by containing a broad assortment of reviews, each capturing the viewer’s subjective experience of a certain movie. With the proliferation of user-generated content, leveraging the power of sentiment analysis on this dataset allows for a comprehensive understanding of viewers’ perspectives and provides valuable insights for film producers, directors, and distributors to comprehend audience preferences, improve storytelling techniques, and make informed decisions.
On the other hand, Sentiment analysis is a method for automatically identifying, extracting, and categorizing subjective information from textual data. Its major goal is to analyze the text’s polarity, discriminating between positive, negative, and neutral thoughts, and assessing the author’s overall emotional tone. Sentiment analysis can uncover the underlying sentiments that impact people’s perceptions and decisions by utilizing different NLP and machine learning approaches. This can be effectively applied in medical chatbots, biomedical NLP, natural language processing in healthcare, and other products. Sentiment analysis is a flexible method for reading the rich tapestry of human emotions and opinions, whether assessing consumer feedback, analyzing social media trends, or grasping public opinion on political events.
Creating a Sentiment Analysis Model Architecture Based on LSTMs
The use of LSTM cells in sentiment analysis offers a lot of promise, especially in understanding the sequential character of textual input and identifying long-term connections between words and phrases. This article aims to build an LSTM-based model that reliably distinguishes the sentiments encoded within textual reviews by incorporating PyTorch, a sophisticated open-source machine-learning package. Using LSTM networks’ inherent ability to store historical knowledge over long periods, the model architecture will be developed to efficiently capture the rich contextual cues and intricacies found in the IMDB dataset. The creation of the LSTM-based sentiment analysis model will provide a thorough method for using deep learning techniques for analyzing human sentiment from textual data, leveraging PyTorch’s flexibility and efficiency.
PyTorch Implementation of LSTM
Now, let’s delve into the implementation of a simple LSTM model using the PyTorch framework in Python. The provided code demonstrates the structure of an LSTM-based sentiment analysis model. Let’s break down the key components of the code:
class LSTMClassifier(nn.Module):
def __init__(self, embedding_dim, hidden_dim, vocab_size):
super(LSTMClassifier, self).__init__()
self.embedding = nn.Embedding(
vocab_size, embedding_dim, padding_idx=0)
self.lstm = nn.LSTM(embedding_dim, hidden_dim)
self.dense = nn.Linear(in_features=hidden_dim, out_features=1)
self.sig = nn.Sigmoid()
self.word_dict = None
def forward(self, x):
x = x.t()
lengths = x[0, :]
reviews = x[1:, :]
embeds = self.embedding(reviews)
lstm_out, _ = self.lstm(embeds)
out = self.dense(lstm_out)
out = out[lengths - 1, range(len(lengths))]
return self.sig(out.squeeze())
By incorporating the necessary layers, such as the embedding layer, LSTM layer, and linear layer with a sigmoid activation function, we will develop a robust neural network capable of analyzing textual data and discerning the sentiment embedded within. Additionally, PyTorch’s flexibility and efficiency will enable us to fine-tune the model’s parameters and optimize its performance, ensuring precise sentiment classification for diverse textual inputs.
Training and Evaluation
Upon constructing the LSTM-based sentiment analysis model, we will proceed to train it using the IMDB dataset. The training process will involve feeding the model with labeled textual reviews, allowing it to learn the underlying patterns and associations between words and sentiments. We will leverage PyTorch’s extensive functionalities to fine-tune the model’s hyperparameters, optimize the learning rate, and employ appropriate loss functions, thereby enhancing the model’s predictive capabilities and ensuring its robustness when handling real-world textual data.
class SentimentAnalysis:
def __init__(self, embedding_dim, hidden_dim, vocab_size):
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.vocab_size = vocab_size
self.device = torch.device(
"cuda" if torch.cuda.is_available()
else "cpu")
self.model = LSTMClassifier(embedding_dim, hidden_dim, vocab_size)
self.word_dict = pickle.load(
open("./sentiment_analysis/word_dict.pkl", "rb")
)
def train(self, train_loader, epochs):
optimizer = optim.Adam(self.model.parameters(), lr=1e-3)
loss_fn = torch.nn.BCELoss()
for epoch in range(1, epochs + 1):
self.model.train()
total_loss = 0
for batch in train_loader:
batch_X, batch_y = batch
batch_X = batch_X.to(self.device)
batch_y = batch_y.to(self.device)
optimizer.zero_grad()
model_output = self.model.forward(batch_X)
loss = loss_fn(model_output, batch_y)
loss.backward()
optimizer.step()
total_loss += loss.data.item()
print("Epoch: {}, BCELoss: {}".format(
epoch, total_loss / len(train_loader)))
def predict(self, x):
data_X, data_len = convert_and_pad(
self.word_dict, review_to_words(x), pad=500)
data_pack = np.hstack((data_len, data_X))
data_pack = data_pack.reshape(1, -1)
data = torch.from_numpy(data_pack)
data = data.to(self.device)
# Make sure to put the model into evaluation mode
self.model.eval()
with torch.no_grad():
output = self.model(data)
return "positive" if round(output.item()) else "negative"
def evaluate(self, x, y):
self.model.eval()
with torch.no_grad():
output = self.model(x)
predicted = output.data.round()
correct = (predicted == y).sum().item()
return correct / len(y)
Instantiating a `SentimentAnalysis` model with an embedding dimension of 32, a hidden size of 100, and a vocabulary size of 5000.
model = SentimentAnalysis(32, 100, 5000)
Training the instantiated model using a training data loader for 10 epochs.
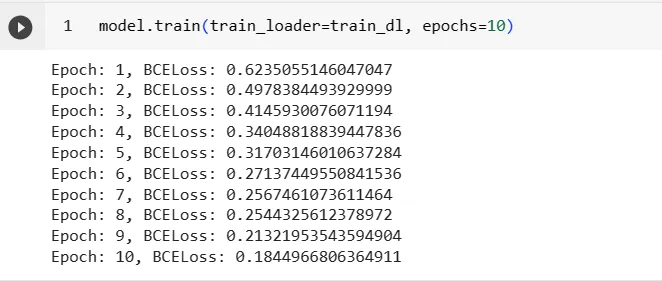
Following the training phase, we will rigorously evaluate the model’s performance using various metrics such as accuracy, precision, recall, and F1-score. This comprehensive evaluation process will enable us to assess the model’s ability to accurately classify sentiments and provide valuable insights into its overall effectiveness in processing and understanding textual data. By meticulously analyzing the model’s performance, we can identify potential areas for improvement and implement necessary adjustments to enhance its predictive accuracy and generalizability.
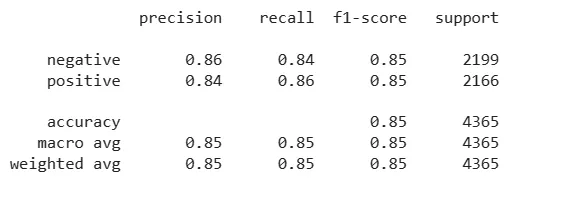
Leveraging the Power of LSTM for Sentiment Analysis
By combining the capabilities of LSTM networks and the flexibility of the PyTorch framework, we developed a robust sentiment analysis model that effectively captures and comprehends the intricate nuances of human sentiment encoded within textual data. This model will not only provide valuable insights into the emotional tone and subjective opinions expressed in textual reviews but also offer a powerful tool for businesses and organizations to analyze customer feedback, gauge public sentiment, and make informed decisions based on the sentiments expressed by their target audience. With its ability to process and understand the sequential nature of textual data, the LSTM-based sentiment analysis model holds immense potential for various applications, ranging from market research and brand management to customer satisfaction analysis and product development.
Let’s evaluate models with LangTest
LangTest provides a comprehensive framework for testing sentiment analysis models across various libraries and APIs. Developers can seamlessly evaluate the performance of sentiment analysis models from John Snow Labs, Hugging Face, Spacy, OpenAI, Cohere, AI21, Hugging Face Inference API, and Azure-OpenAI based LLMs. With a rich set of functionalities, LangTest supports testing both binary and multiclass sentiment classifiers. For instance, a developer can assess the accuracy, robustness, and bias of a sentiment analysis model by applying LangTest’s suite of 50+ out-of-the-box tests.
!pip install langtest==1.9.0
from langtest import Harness
harness = Harness(task="text-classification",
model={'model': model, "hub": "custom"},
data={'data_source': './data/imdb.csv'})
One illustrative example involves testing a sentiment analysis model’s ability to discern nuanced emotions in user reviews. Using LangTest with a PyTorch-based sentiment classifier, developers can evaluate the model’s performance in accurately identifying sentiments like joy, disappointment, or frustration within a diverse set of customer feedback. The library’s modular design allows for tailored testing, ensuring that the sentiment analysis model not only provides accurate predictions but also exhibits robustness across different linguistic styles and potential biases present in the training data. This flexibility makes LangTest an invaluable tool for developers seeking to enhance the reliability and effectiveness of sentiment analysis models in real-world applications.
The configuration specifies default test parameters, such as a minimum pass rate of 0.65, and introduces robustness tests, such as uppercase, lowercase, add_contraction, lowercase …etc each with their respective minimum pass rates of 0.7. This customization enables developers to fine-tune the evaluation process, ensuring a comprehensive assessment of model performance across various linguistic nuances and cases.
harness.configure(
{
'tests': {
'defaults': {'min_pass_rate': 0.65},
'robustness': {
'uppercase': {'min_pass_rate': 0.80},
'lowercase':{'min_pass_rate': 0.80},
'titlecase':{'min_pass_rate': 0.80},
'add_typo':{'min_pass_rate': 0.80},
'dyslexia_word_swap':{'min_pass_rate': 0.80},
'add_abbreviation':{'min_pass_rate': 0.80},
'add_slangs':{'min_pass_rate': 0.80},
'add_speech_to_text_typo':{'min_pass_rate': 0.80},
'add_ocr_typo':{'min_pass_rate': 0.80},
'adjective_synonym_swap':{'min_pass_rate': 0.80},
'adjective_antonym_swap':{'min_pass_rate': 0.80}
}
}}
)
harness.generate().run().report()
The report reveals a transformative journey in the performance of our sentiment analysis model, notably seen in the robustness tests. Initially, certain tests, such as dyslexia_word_swap, add_abbreviation, add_slangs, add_ocr_typo, adjective_synonym_swap, and adjective_antonym_swap, experienced a failure to meet the 95% minimum pass rate.
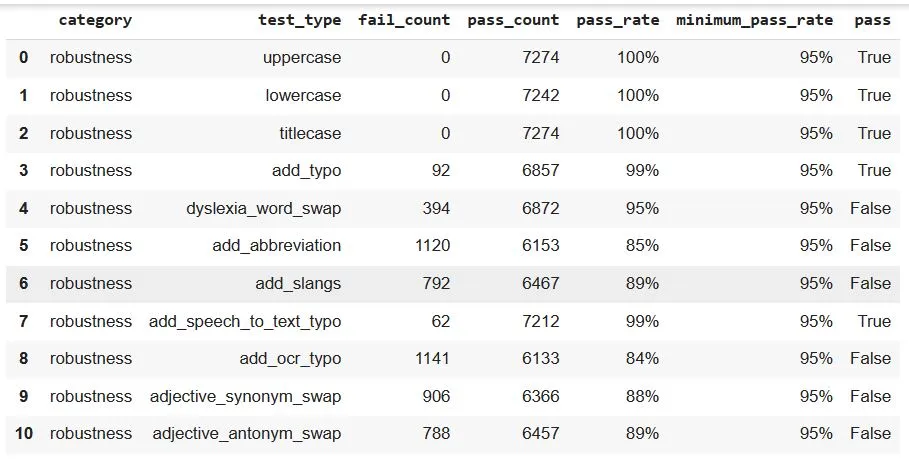
However, a significant enhancement is observed following augmentation by harness.augment(). The dyslexia_word_swap test, for instance, demonstrated a notable improvement, with the failure count reduced from 394 to 292, resulting in a commendable 96% pass rate. Similarly, tests like add_abbreviation, add_slangs, add_ocr_typo, adjective_synonym_swap, and adjective_antonym_swap all witnessed a positive shift, now surpassing the 95% minimum pass rate. This augmentation-driven success reaffirms the effectiveness of our approach, showcasing the model’s ability to adapt and excel in the face of diverse linguistic challenges. These results underscore the importance of dynamic testing and continuous refinement in optimizing the robustness of our sentiment analysis model.
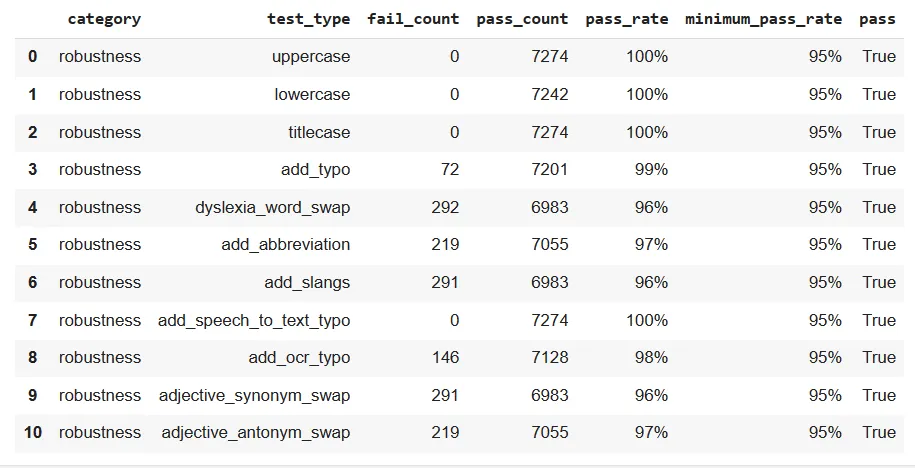
after augmentation
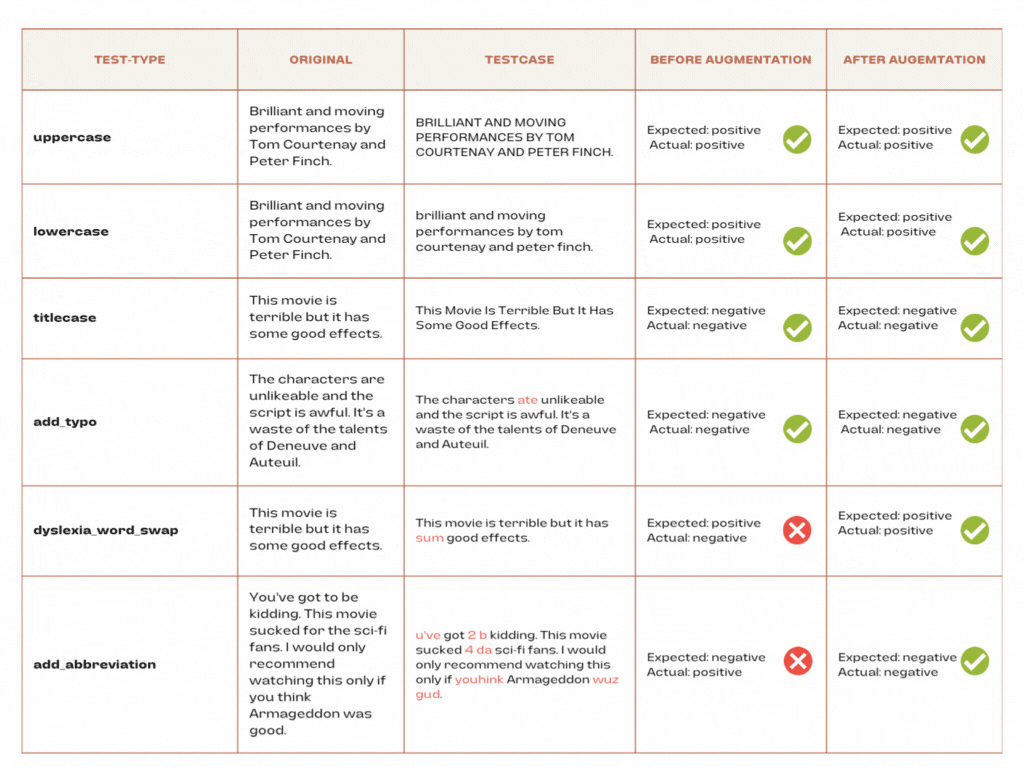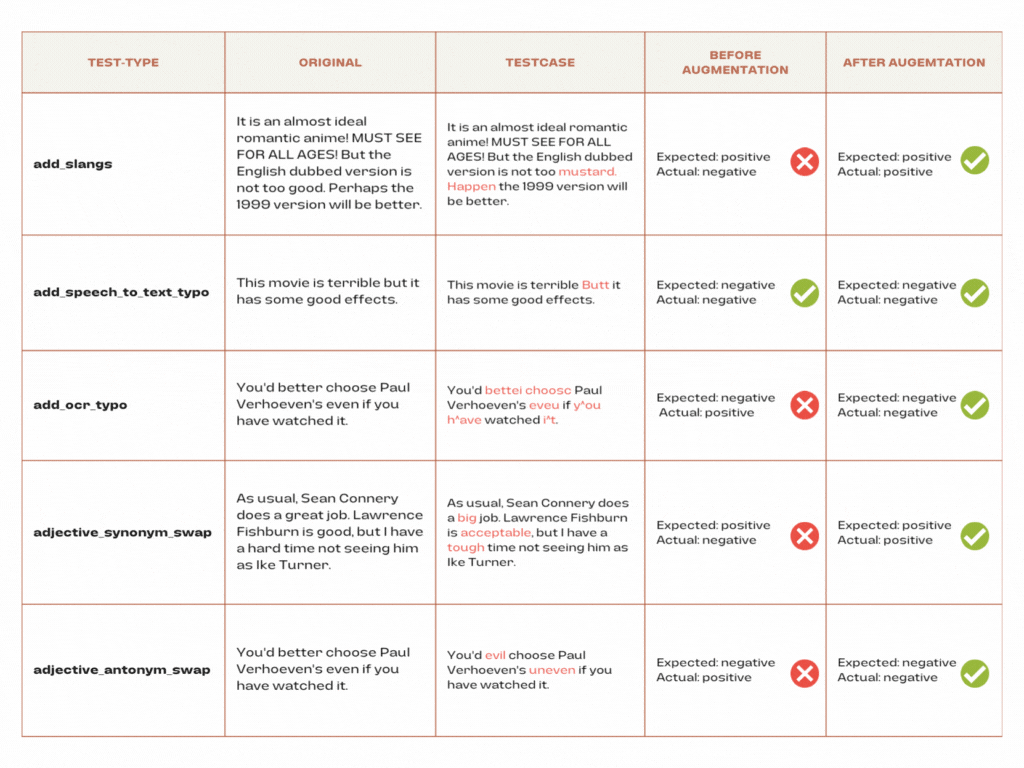
Conclusion
In summary, the robustness testing results for our sentiment analysis model initially revealed its robust nature, showcasing consistently high pass rates exceeding the 95% minimum threshold across diverse linguistic challenges. However, a more nuanced exploration of specific robustness tests uncovered areas for improvement, with tests like dyslexia_word_swap and add_abbreviation failing to meet the minimum pass rate. The subsequent application of harness.augment proved instrumental in resolving these challenges. Notably, dyslexia_word_swap exhibited a significant enhancement, with the fail count reduced from 394 to 292, achieving an impressive 96% pass rate. This augmentation-driven success extended to other tests like add_abbreviation, add_slangs, add_ocr_typo, adjective_synonym_swap, and adjective_antonym_swap, all surpassing the 95% minimum pass rate.
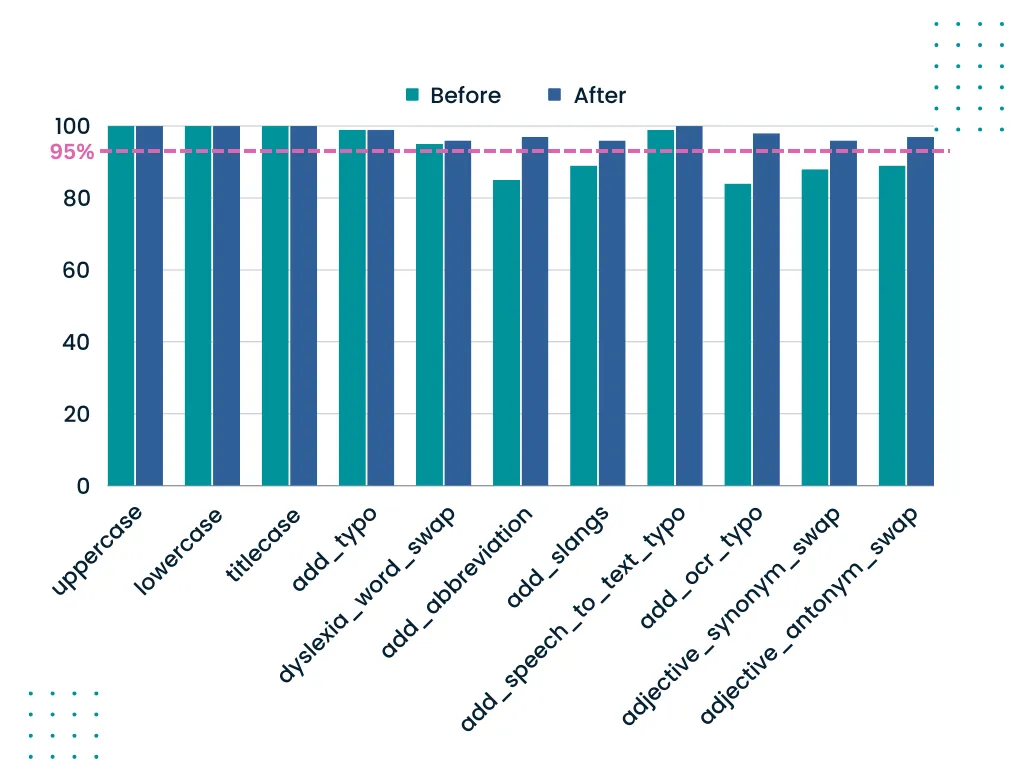
Delving into the specifics of the robustness tests, our model not only showcased proficiency in synonym and antonym swaps but demonstrated an adaptive prowess, addressing shortcomings identified through dynamic testing. This iterative refinement process positions our sentiment analysis model as a reliable tool for extracting meaningful insights from text in dynamic contexts. The LangTest results, combined with the resolution-driven augmentation, affirm the model’s ability to navigate the intricacies of natural language, providing developers and stakeholders with a dependable solution for extracting valuable sentiment-related information from textual data in real-world applications.
References
Large Movie Review Dataset v1.0
Gopalakrishnan, K., & Salem, F. M. (2020). Sentiment Analysis Using Simplified Long Short-term Memory Recurrent Neural Networks. ArXiv. /abs/2005.03993
Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. (2011). Learning Word Vectors for Sentiment Analysis. The 49th Annual Meeting of the Association for Computational Linguistics (ACL 2011).




