Word embeddings are considered as a type of representation used in natural language processing (NLP) to capture the meaning of words in a numerical form. They are essentially a way of representing words as dense vectors of real numbers, where each dimension in the vector represents a different aspect of the word’s meaning.

Word embeddings are used in natural language processing (NLP) as a technique to represent words in a numerical format. It involves mapping each word in a vocabulary to a high-dimensional vector, where each dimension of the vector corresponds to a latent feature or characteristic of the word. The embedding vectors learn from large amounts of textual data, and are optimized such that semantically similar words are located close to each other in the vector space.
Word embeddings are generated using algorithms that are trained on large corpora of text data. These algorithms learn to assign each word in the corpus a unique vector representation that captures the word’s meaning based on its context in the text. Words that appear in similar contexts will have similar vector representations, while words that appear in different contexts will have dissimilar vector representations.
Word embeddings have become an important tool in NLP because they allow models to work with text data in a way that is more similar to how humans understand language. By representing words as vectors, models can more easily identify patterns and relationships in text data, and can make better predictions about things like sentiment analysis, text classification, and machine translation.
In word embeddings, a dimension refers to a feature or attribute of a word that is represented as a numerical value. Each dimension in a word embedding vector captures a different aspect of the word’s meaning, such as its syntactic or semantic properties. For example, a word embedding might represent “king” as a vector in a high-dimensional space where one dimension might correspond to “royalty”, another to “male gender”, and yet another to “power”. The value of each dimension in the vector represents the degree to which that aspect is present in the word’s meaning.
The Word2Vec models have two variants: the skip-gram model and the continuous bag-of-words (CBOW) model. In the skip-gram model, the goal is to predict the surrounding words given a central word, while in the CBOW model, the central word is predicted given the surrounding words. These models are trained on large amounts of text data, such as Wikipedia or news articles, and the resulting embeddings capture the semantic meaning of words based on their co-occurrence patterns in the corpus.
The WordEmbeddings and Word2Vec annotators in Spark NLP are both used to create word embeddings from text data, but there are some differences between their approach to the problem.
The WordEmbeddings annotator is a general-purpose annotator that can be used to create word embeddings using various pretrained models. It can also be used to train custom word embedding models on user-specific datasets. The WordEmbeddings annotator supports different configurations and hyperparameters, making it a flexible tool for creating word embeddings.
On the other hand, the Word2Vec annotator is a specific annotator that may be used to create word embeddings using the Word2Vec algorithm. This algorithm creates word embeddings by predicting the context words of a target word or by predicting the target word given its context words. The Word2Vec annotator in Spark NLP provides options for configuring the size of the embedding vectors, the window size, and other hyperparameters of the Word2Vec algorithm.
Please check our similar post about “Embeddings with Transformers” for BERT family embeddings.
In this post, you will learn how to use word embeddings of Spark NLP.
Spark NLP has multiple approaches for generating word embeddings. In this article, we will discuss:
- Using
WordEmbeddings, an annotator that prepares data into a format that is processable by Spark NLP. - Using
Word2Vecannotator for generating word embeddings using the Word2Vec algorithm.
Let us start with a short Spark NLP introduction and then discuss the details of word embeddings with some solid results.
Introduction to Spark NLP
Spark NLP is an open-source library maintained by John Snow Labs. It is built on top of Apache Spark and Spark ML and provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment.
Since its first release in July 2017, Spark NLP has grown in a full NLP tool, providing:
- A single unified solution for all your NLP needs
- Transfer learning and implementing the latest and greatest SOTAalgorithms and models in NLP research
- The most widely used NLP library in industry (5 years in a row)
- The most scalable, accurate and fastest library in NLP history
Spark NLP comes with 17,800+ pretrained pipelines and models in more than 250+ languages. It supports most of the NLP tasks and provides modules that can be used seamlessly in a cluster.
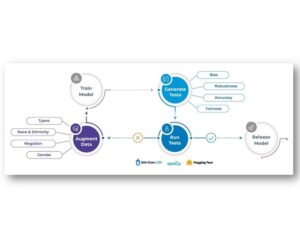
Spark NLP processes the data using Pipelines, structure that contains all the steps to be run on the input data:
Spark NLP pipelines
Each step contains an annotator that performs a specific task such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
An annotator in Spark NLP is a component that performs a specific NLP task on a text document and adds annotations to it. An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. For example, a named entity recognizer annotator might identify and tag entities such as people, organizations, and locations in a text document, while a sentiment analysis annotator might classify the sentiment of the text as positive, negative, or neutral.
Setup
To install Spark NLP in Python, simply use your favorite package manager (conda, pip, etc.). For example:
pip install spark-nlp pip install pyspark
For other installation options for different environments and machines, please check the official documentation.
Then, simply import the library and start a Spark session:
import sparknlp # Start Spark Session spark = sparknlp.start()
WordEmbeddings
The WordEmbeddings annotator in Spark NLP is an NLP tool that is used to create word embeddings from text data. The WordEmbeddings annotator in Spark NLP allows users to create word embeddings using pretrained models or by training their own models on custom datasets. It supports various pre-trained word embedding models. For available pretrained embeddings please see the John Snow Labs Models Hub.
The default model for the WordEmbeddings annotator is glove_100d. GloVe (Global Vectors) is a model for distributed word representation. This is achieved by mapping words into a meaningful space where the distance between words is related to semantic similarity. It is developed as an open-source project at Stanford and was launched in 2014.
There are various Glove embeddings in the John Snow Labs Models Hub, multilingual and 100 to 300 dimensions.
Spark NLP has the pipeline approach and the pipeline will include the necessary stages.
# Import the required modules and classes
from sparknlp.base import DocumentAssembler, Pipeline
from sparknlp.annotator import (
Tokenizer,
WordEmbeddingsModel,
)
# Step 1: Transforms raw texts to `document` annotation
documentAssembler = DocumentAssembler() \
.setInputCol('text') \
.setOutputCol('document')
# Step 2: Tokenization
tokenizer = Tokenizer() \
.setInputCols(['document']) \
.setOutputCol('token')
# Step 3: Generate the Embeddings
embeddings = WordEmbeddingsModel\
.pretrained('glove_100d', 'en')\
.setInputCols(["token", "document"])\
.setOutputCol("embeddings")
# Define the pipeline
pipeline = Pipeline() \
.setStages([
documentAssembler,
tokenizer,
embeddings])
# Create a dataframe with the sample text
sample_text = "Brilliant individuals strive for constant self-improvement."
data = spark.createDataFrame([[sample_text]]).toDF("text")
# Fit the dataframe to the pipeline and then transform to produce the embeddings
model = pipeline.fit(data)
result = model.transform(data)
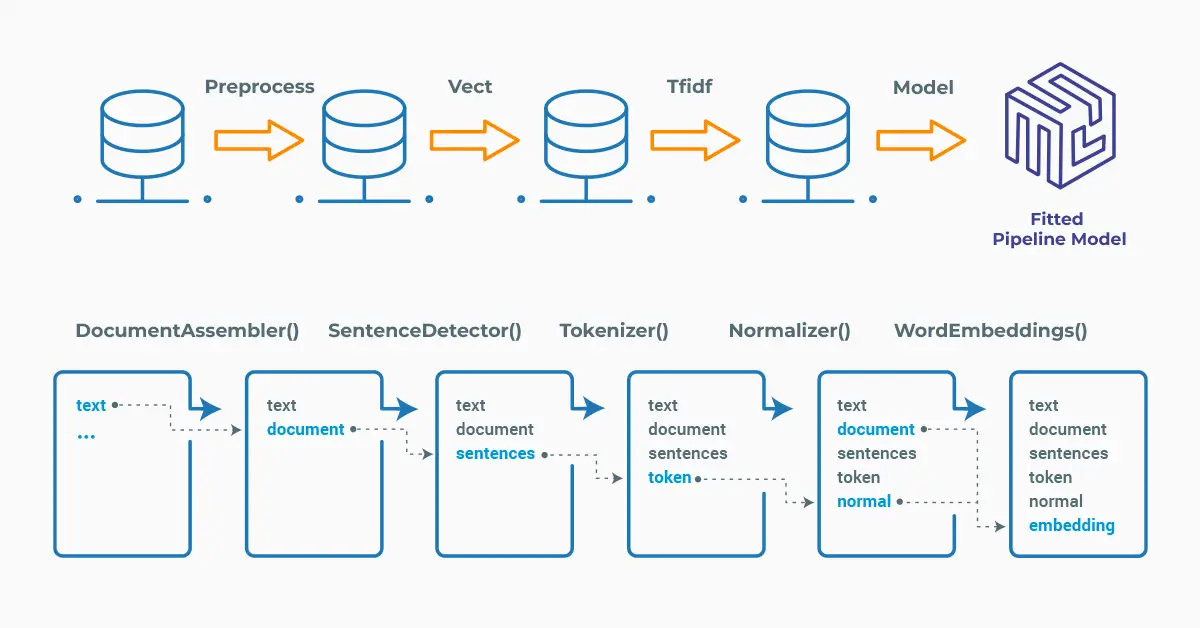
Now, we will explode the results to get a nice dataframe of the tokens and the corresponding word embeddings:
import pyspark.sql.functions as F
result_df = result.select(F.explode(F.arrays_zip(result.token.result,
result.embeddings.embeddings)).alias("cols")) \
.select(F.expr("cols['0']").alias("token"),
F.expr("cols['1']").alias("word_embeddings"))
result_df.show(truncate=100)

Dataframe showing the tokens and their corresponding embeddings.
Light Pipeline
As an alternative, let’s use LightPipeline here to observe the embeddings. LightPipeline is a Spark NLP specific Pipeline class equivalent to the Spark ML Pipeline. The difference is that its execution does not hold to Spark principles, instead it computes everything locally (but in parallel) in order to achieve fast results when dealing with small amounts of data.
Check this post to learn more about this class.
from sparknlp.base import LightPipeline light_model_emb = LightPipeline(pipelineModel = model, parse_embeddings=True) annotate_results_emb = light_model_emb.annotate(sample_text) list(zip(annotate_results_emb['token'], annotate_results_emb['embeddings']))

LightPipeline results showing all the embeddings (100 dimension) for the tokens
One-liner alternative
In October 2022, John Snow Labs released the open-source johnsnowlabs library that contains all the company products, open-source and licensed, under one common library. This simplified the workflow especially for users working with more than one of the libraries (e.g., Spark NLP + Healthcare NLP). This new library is a wrapper on all John Snow Lab’s libraries, and can be installed with pip:
pip install johnsnowlabs
Please check the official documentation for more examples and usage of this library. To run a named entity recognition model with one line of code, we can simply:
# Import the NLP module which contains Spark NLP and NLU libraries
from johnsnowlabs import nlp
glove_df = nlp.load('en.embed.glove.100d').predict(
'Brilliant individuals strive for constant self-improvement.')
glove_df
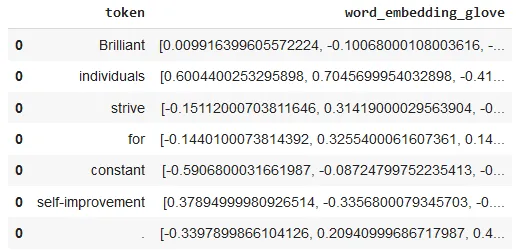
After using the one-liner model, the result shows the tokens and their corresponding embeddings
The one-liner is based on default models for each NLP task. Depending on your requirements, you may want to use the one-liner for simplicity or customizing the pipeline to choose specific models that fit your needs.
NOTE: when using only the johnsnowlabs library, make sure you initialize the spark session with the configuration you have available. Since some of the libraries are licensed, you may need to set the path to your license file. If you are only using the open-source library, you can start the session with spark = nlp.start(nlp=False). The default parameters for the start function includes using the licensed Healthcare NLP library with nlp=True, but we can set that to False and use all the resources of the open-source libraries such as Spark NLP, Spark NLP Display, and NLU.
Word2Vec
Word2Vec annotator in Spark NLP enables the creation of word embeddings using the Word2Vec algorithm. The Word2Vec annotator in Spark NLP takes in a corpus of text and generates dense vector representations for each word in the vocabulary. For available pretrained models please see the Models Hub.
Let’s run the pipeline and produce the word embeddings using the pretrained model:
# Import the required modules and classes
from sparknlp.base import DocumentAssembler, Pipeline
from sparknlp.annotator import (
Tokenizer,
WordEmbeddingsModel,
Word2VecModel
)
# Step 1: Transforms raw texts to `document` annotation
documentAssembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
# Step 2: Tokenization
tokenizer = Tokenizer() \
.setInputCols(["document"]) \
.setOutputCol("token")
# Step 3: Produce Word2Vec Embeddings
embeddings = Word2VecModel.pretrained() \
.setInputCols(["token"]) \
.setOutputCol("embeddings")
# Define the pipeline
pipeline = Pipeline().setStages([
documentAssembler,
tokenizer,
embeddings
])
# Create a dataframe with the sample sentence
sample_text = "Brilliant individuals strive for constant self-improvement."
data = spark.createDataFrame([[sample_text]]).toDF("text")
# Fit the dataframe to the pipeline and then transform to produce the embeddings
model = pipeline.fit(data)
result = model.transform(data)
At the end of the code snippet above, we transformed the sample dataframe to get predictions. Let’s explode the results and see the embeddings:
import pyspark.sql.functions as F
result_df = result.select(F.explode(F.arrays_zip(result.token.result,
result.embeddings.embeddings)).alias("cols")) \
.select(F.expr("cols['0']").alias("token"),
F.expr("cols['1']").alias("word_embeddings"))
result_df.show(truncate=100)

Light Pipeline
Once again, let’s use LightPipeline here to observe the embeddings produced by the Word2VecModel annotator.
Notice that, this model produces embeddings of 300 dimensions, whereas Glove model in the previous WordEmbeddings annotator produced vectors of 100 dimensions. This will be a huge vector, so I just show the embeddings for the first word (‘Brilliant’) of the sample text.
light_model_w2v = LightPipeline(pipelineModel = model, parse_embeddings=True) annotate_results_w2v = light_model_w2v.annotate(sample_text) list(zip(annotate_results_w2v['token'], annotate_results_w2v['embeddings']))

LightPipeline results showing all the embeddings (300 dimension) for the first token —’ Brilliant’
One-liner alternative
We already installed the John Snow Lab’s library and imported the nlp module, so just run the code below to get the Word2Vec embeddings:
nlp.load("en.embed.word2vec.gigaword").predict(
"Brilliant individuals strive for constant self-improvement.")
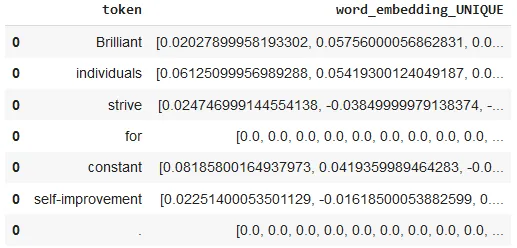
After using the one-liner model, the result shows the tokens and their corresponding embeddings
For additional information, please consult the following references:
- Documentation : WordEmbeddings, Word2Vec.
- Python Docs : WordEmbeddings, Word2Vec.
- Scala Docs : WordEmbeddings, Word2Vec.
- For extended examples of usage, see the Spark NLP Workshop repository.
Conclusion
In this article, we tried to get you familiar with the basics of word embeddings. WordEmbeddings and Word2Vec are very useful annotators used in Spark NLP to represent words as dense vectors in high-dimensional spaces. Spark NLP provides several pretrained word embedding models that can be used to analyze and process text data efficiently. With Spark NLP, users can leverage these pretrained models or train their own custom word embeddings on their specific data to improve the accuracy and performance of their NLP models.
In summary, word embeddings are considered a powerful tool in NLP that can help algorithms understand language in a more nuanced and human-like way.