



























































Medical Data De-identification
- Simple process & setup
- Automatically de-identify structured data, unstructured data, documents, PDF files, and images in compliance with HIPAA, GDPR, or custom needs
- Trusted by 5 of 8 Top Pharma Companies
>99%Accuracy on real-world documents
Accuracy:
99.19correctly de-identified sentences
Performance:
2.46hours
to de-identify 500K patient notes.
Live Test with Your Medical Data
The Data De-identification Software
Read the blog post “Accurate PHI De-identification”
1
Analyze

- Risk analysis
- Legal requirements review
- HIPAA Safe Harbor, HIPAA Expert Determination
- CCPA
- GDPR pseudoanonymization, GDPR anonymization
- Quality assurance strategy & process

2
Identify

- ID, name, email, patient ID, SSN, credit card, address, birthday, phone, URL, license number
- Physician name, hospital name, profession, employer, affiliation
- Racial or ethnic origin, religion, political or union affiliation, biometric or genetic data, sexual practice or orientation
3
Measure
- Cleanroom AI Platform (on-site)
- Annotation tool
- Active learning
- Accuracy Measurement & agreement processes
- Correct sampling
- Multi-lingual
4
De-identify
We support:
- Tabular (headers, values)
- Text (NER, text matching)
- PDF: Text or Scanned
- Images(OCR & metadata)
- DICOM (OCR & metadata)
So you can:
- Replace (or delete a field)
- Mask (hash identifiers or shift dates)
- Obfuscate (name, locations, organizations)
- Generalize (disease codes, dates, addresses)

5
Monitor
- Ongoing measurement & model improvement
- Missed sensitive data
- Incident response
- GDPR & CCPA requests
- Emergency unblinding
- Audits
De-identification Tools with Full range of features
| John Snow Labs’ De-identification solutions | AWS Medical Comprehend | Microsoft Presidio | Google DLP | |
|---|---|---|---|---|
| De-dentification tool | ||||
| End-to-end service | ||||
| Available also as a standalone library | ||||
| Established new state of the art accuracy in peer reviewed publication | ||||
| Real world reference with >99% correctly recognized PHI | ||||
| Scanned PDF | Integrated | Separate service | Separate service | |
| DICOM | Integrated | Separate service | Separate service | |
| Obfuscation | ||||
| Software with Multilingual support | ||||
| Built on big data framework | ||||
| Possible to fine tune standard pre-trained models | ||||
| Data does not leave your premise | ||||
| Works in air gap insulated server with no internet access |
- Entities available out of box:
ACCOUNT, AGE, BIOID, CITY, CONTACT, COUNTRY, DATE. DEVICE, DLN, DOCTOR, EMAIL, FAX, HEALTHPLAN, HOSPITAL, ID, IDNUM, IPADDR, LICENSE, LOCATION, LOCATION-OTHER, MEDICALRECORD, NAME, ORGANIZATION, PATIENT, PHONE, PLATE, PROFESSION, SSN, STREET, STATE, URL, USERNAME, VIN, ZIP
- Easy to add other entities.
- Works with virtually any input – text, scanned PDF, DICOM, docx, pptx.
Data De-identification software in Action

De-identify
structured data
structured data
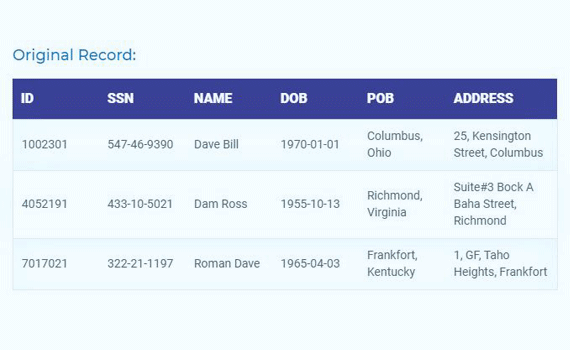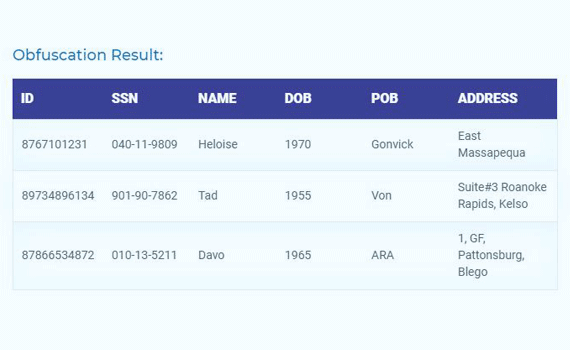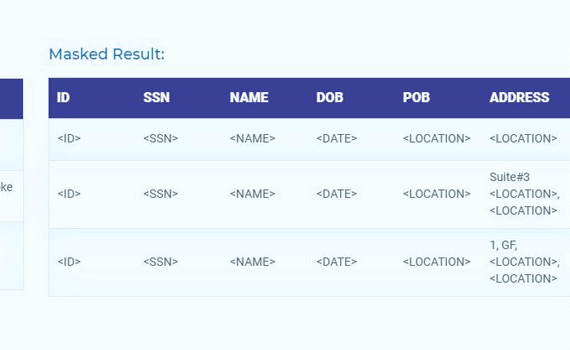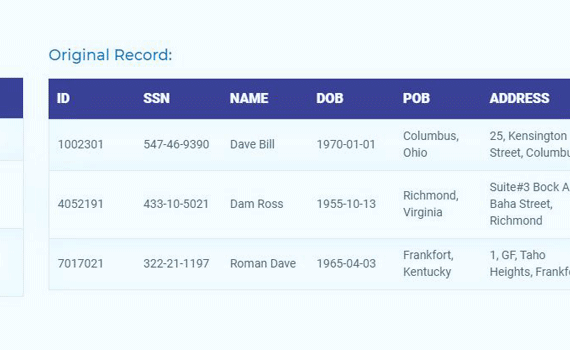
Tools to De-identify PHI (Protected Health Information) from structured datasets automatically while enforcing GDPR and HIPAA compliance and maintaining linkage of clinical data across files.



De-identify free text
documents
documents
De-identify free text documents by either masking or obfuscating PHI using out-of-the-box, high-accuracy Spark NLP Healthcare models.

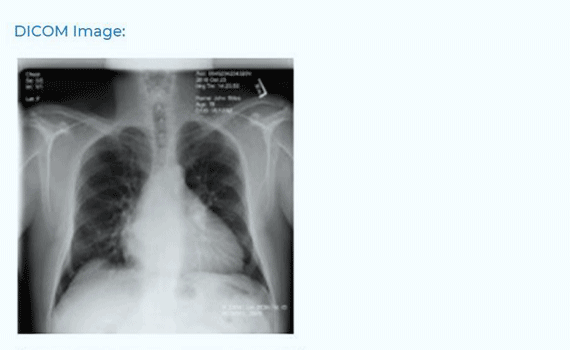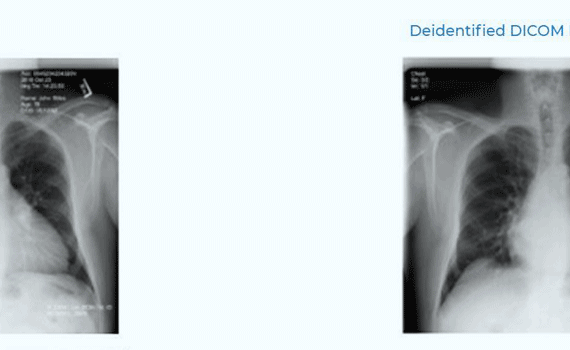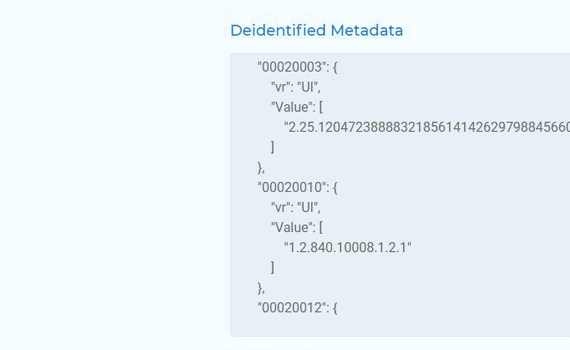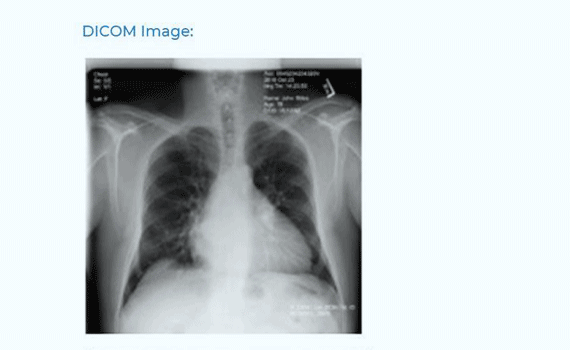
De-identify DICOM
documents
documents
De-identify DICOM documents by masking PHI information on the image and by either masking or obfuscating PHI from the metadata.


De-identify PDF documents – HIPAA Compliance
De-identify PDF documents using HIPAA guidelines by masking PHI information using out of the box Spark NLP and Spark OCR models.

De-identify PDF documents – GDPR Compliance
De-identify PDF documents using GDPR guidelines by anonymizing PHI information using out of the box Spark NLP and Spark OCR models.

