


























































In this article, we will explore the significance of table extraction and demonstrate the application of John Snow Labs’ NLP library with visual features installed for this purpose. We will delve into the key components within the John Snow Labs NLP pipeline that facilitate table extraction. Additionally, we will explore the utilization of John Snow Lab’s One Liner Call for streamlined table extraction procedures.
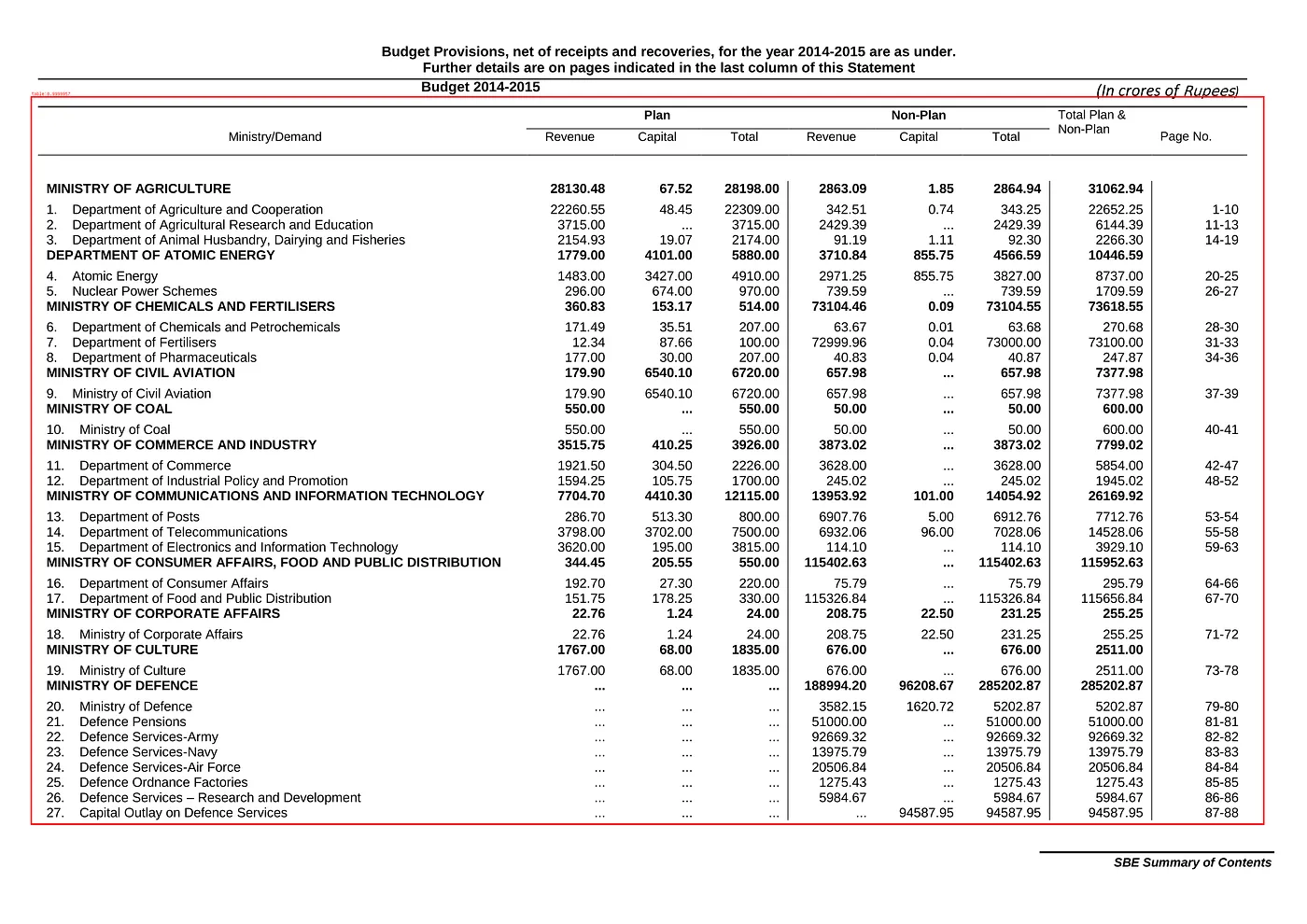
Results for Image Table Detection using Visual NLP
Introduction: Why is Table Extraction so crucial?
Table recognition is a crucial aspect of OCR because it allows for structured data extraction from unstructured sources. Tables often contain valuable information organized systematically. By recognizing tables, OCR can convert this data into a format easily manipulatable and analyzable, such as a spreadsheet or a database. This opens up possibilities for data analysis, machine learning, and other data-driven tasks. Without table recognition, important context could be lost, and the value of the data significantly reduced. Therefore, table recognition plays a vital role in maximizing the utility of OCR.
How does Visual NLP come into action?
Visual NLP’s ImageTableDetector, ImageTableCellDetector, and ImageCellsToTextTable classes now enable you to extract tables from images as pandas data frames in a single line of code.
What are the components that will be used for Table Extraction?
ImageTableDetector
In a Visual NLP pipeline, various transformations are sequentially linked, with the output of one stage serving as the input for the subsequent stage. These stages, also known as annotators, form the foundation of your pipeline. This section will concentrate on these aspects.
The ImageTableDetector is a deep-learning model that identifies tables within images. It leverages the CascadeTabNet architecture, which includes the Cascade mask Region-based Convolutional Neural Network High-Resolution Network (Cascade mask R-CNN HRNet). This state-of-the-art model, developed by Visual NLP, is transformer-based and has been optimized by John Snow Labs for accuracy, speed, and scalability.
ImageTableCellDetector
The ImageTableCellDetector detects cells in a table image. It’s based on an image processing algorithm that detects horizontal and vertical lines.
ImageCellsToTextTable
The ImageCellsToTextTable runs OCR for cell regions on the image, and returns recognized text to outputCol as a TableContainer structure.
Implementation: How do we use Visual NLP for Table Extraction?
from johnsnowlabs import nlp, visual
import pandas as pd
binary_to_image = visual.BinaryToImage()
binary_to_image.setOutputCol("image")
binary_to_image.setImageType(visual.ImageType.TYPE_3BYTE_BGR)
# Detect tables on the page using pretrained model
# It can be finetuned for have more accurate results for more specific documents
table_detector = visual.ImageTableDetector.pretrained("general_model_table_detection_v2", "en", "clinical/ocr")
table_detector.setInputCol("image")
table_detector.setOutputCol("region")
# Draw detected region's with table to the page
draw_regions = visual.ImageDrawRegions()
draw_regions.setInputCol("image")
draw_regions.setInputRegionsCol("region")
draw_regions.setOutputCol("image_with_regions")
draw_regions.setRectColor(visual.Color.red)
# Extract table regions to separate images
splitter = visual.ImageSplitRegions()
splitter.setInputCol("image")
splitter.setInputRegionsCol("region")
splitter.setOutputCol("table_image")
splitter.setDropCols("image")
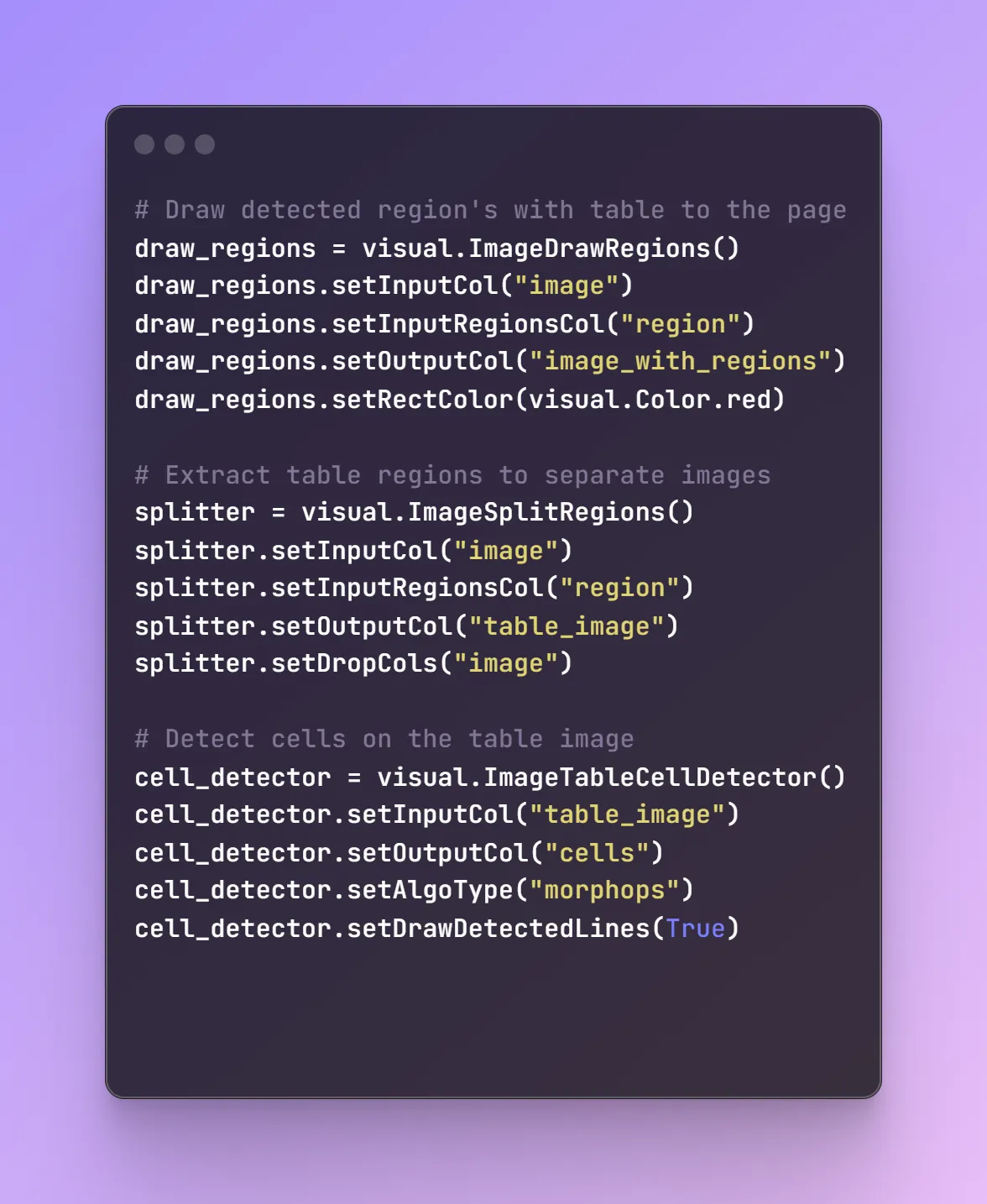
# Detect cells on the table image
cell_detector = visual.ImageTableCellDetector()
cell_detector.setInputCol("table_image")
cell_detector.setOutputCol("cells")
cell_detector.setAlgoType("morphops")
cell_detector.setDrawDetectedLines(True)
# Extract text from the detected cells
table_recognition = visual.ImageCellsToTextTable()
table_recognition.setInputCol("table_image")
table_recognition.setCellsCol('cells')
table_recognition.setMargin(3)
table_recognition.setStrip(True)
table_recognition.setOutputCol('table')
# Erase detected table regions
fill_regions = visual.ImageDrawRegions()
fill_regions.setInputCol("image")
fill_regions.setInputRegionsCol("region")
fill_regions.setOutputCol("image_1")
fill_regions.setRectColor(visual.Color.white)
fill_regions.setFilledRect(True)
# OCR
ocr = visual.ImageToText()
ocr.setInputCol("image_1")
ocr.setOutputCol("text")
ocr.setOcrParams(["preserve_interword_spaces=1", ])
ocr.setKeepLayout(True)
ocr.setOutputSpaceCharacterWidth(8)
pipeline_table = PipelineModel(stages=[
binary_to_image,
table_detector,
draw_regions,
fill_regions,
splitter,
cell_detector,
table_recognition,
ocr
])
tables_results = pipeline_table.transform(df).cache()
Confused?
Don’t worry. Let me explain what is happening in the pipeline.
Let us break it down:
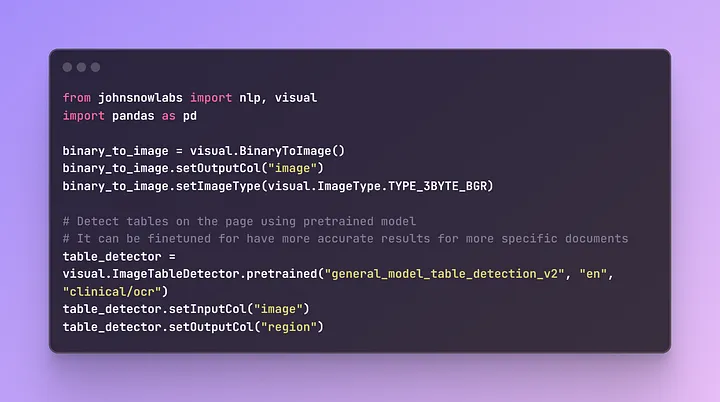
The binary_to_imageobject is created to convert binary data into an image format and configures the output column as “image” with a specified image type.
Next, the code loads a pre-trained model for table detection (general_model_table_detection_v2) provided by John Snow Labs Visual NLP Library. This model is applied to identify tables within images. The input column is set as “image,” and the output column is set as “region.”
draw_regions: It draws red rectangles around detected table regions in the image, making them easily visible.
splitter: This separates the detected table regions into individual images, improving our ability to analyze each table separately.
cell_detector: It focuses on the extracted table images to detect individual cells within them, making them visually identifiable, and optionally outlines the cell boundaries for clarity.
table_recognition: Extracts text from the detected cells, considering a margin of 3 pixels and stripping any extraneous characters for clean data extraction.
fill_regions: Erases the detected table regions from the original image, filling them with a charming white color to ensure no interference with subsequent processing steps.
OCR: Performs Optical Character Recognition (OCR) on the modified image to extract text, preserving interword spaces and maintaining layout integrity with a character width of 8.
Finally, these steps are arranged into a pipeline using PipelineModel, transforming the input DataFrame to yield charming results.
Now, Let’s try to use this pipeline to extract some tables:
First, Let’s load an image and then use the pipeline we have created to predict it.
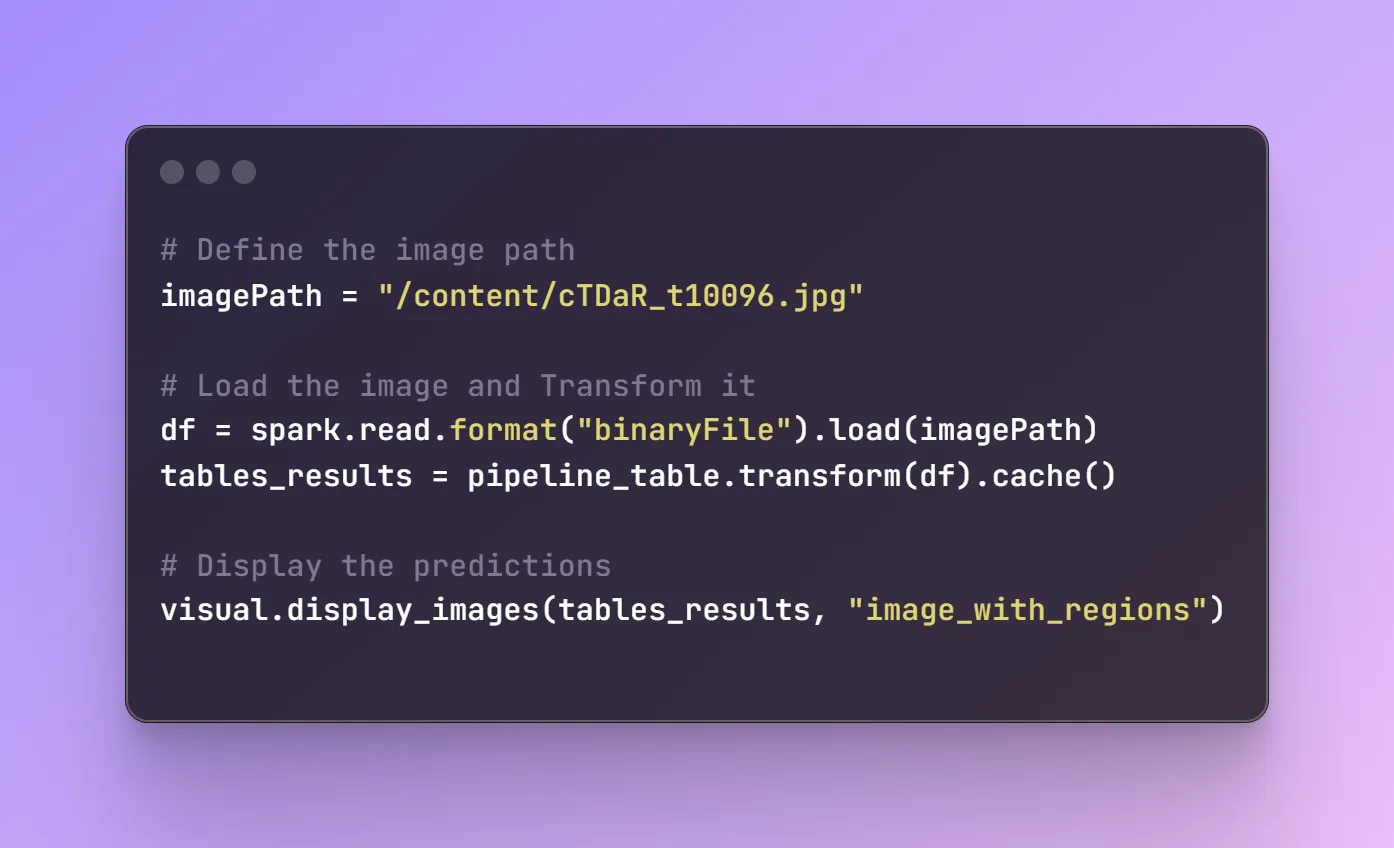
We get the following output:
Original Image Vs Predicted Image
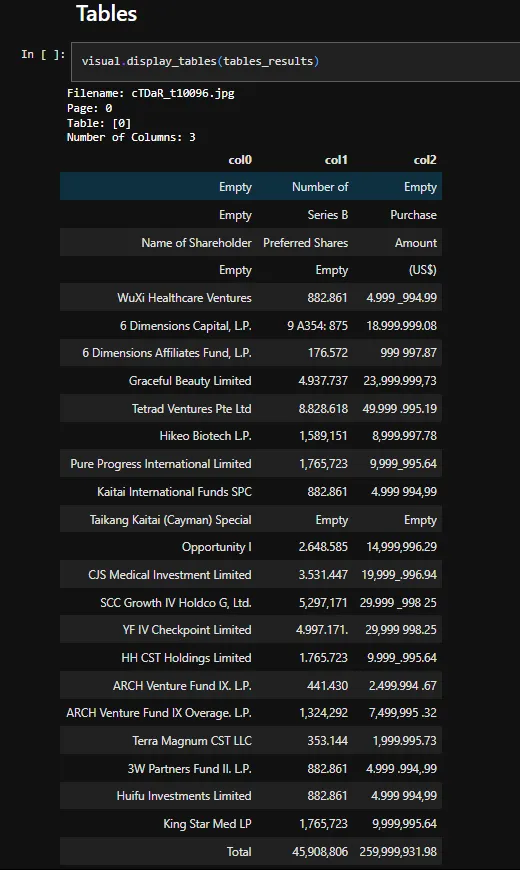
Text Generated
Voila! We’ve just mastered table extraction using John Snow Labs with Visual features. It’s all about constructing a pipeline and stacking one component on top of another.
Now, let’s delve into what sets John Snow Labs apart!
Summary
In this blog post, we’ve embarked on an in-depth exploration of constructing a pipeline for table extraction utilizing John Snow Labs NLP with visual features installed. We’ve observed the potency of the tools offered by John Snow Labs, which streamline this process and empower us to execute intricate tasks. In our subsequent post, we’ll demonstrate how these operations can be accomplished with a single line of code, thanks to John Snow Labs. Stay tuned!




