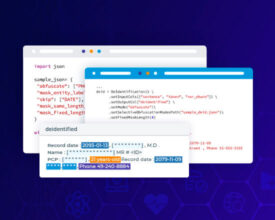
PHI De-Identification with State-of-the-Art NLP De-identification for natural language processing in healthcare is a critical procedure for safeguarding Protected Health Information (PHI) within clinical notes, wherein the data is anonymized...
What Is Driving the Need for AI-Powered Chronic Care Monitoring? Six in ten Americans live with at least one chronic condition1. This growing burden translates into rising healthcare costs, increasing...
The healthcare industry is approaching a defining moment. Artificial intelligence (AI), once a futuristic promise, is now becoming foundational to hospital operations. As AI capabilities evolve and regulatory frameworks mature,...
What is driving the adoption of robotics in hospital logistics? Hospitals are rapidly deploying robotics to alleviate staffing shortages and improve operational efficiency. With a market valued between $1.5 and $3.9 billion...
What is multimodal de-identification and why is it necessary in healthcare? Healthcare data is inherently multimodal. It spans unstructured clinical notes, structured lab results, scanned PDFs, DICOM medical images, and...





























 Demos
Demos
































 See More
See More