

























































Overall, de-identification in today’s data-driven world is a critical practice that helps balance the benefits of AI and big data with the need for privacy and compliance, facilitating both technological innovation and protection of individual rights.
De-identification is extremely important, for several key reasons:
- Privacy Protection: With the vast amount of personal data collected by businesses and governments, protecting individual privacy is critical. De-identification helps safeguard personal information, ensuring that individuals cannot be identified from the data sets used in analysis and research.
- Regulatory Compliance: Many regions around the world have strict regulations governing the use of personal data, such as the General Data Protection Regulation (GDPR) in Europe and the Health Insurance Portability and Accountability Act (HIPAA) in the United States. De-identification is often a necessary step to comply with these legal requirements, helping organizations avoid hefty fines and legal issues.
- Enhanced Data Utility: By de-identifying data, organizations can use sensitive datasets for analytics and research without compromising individual privacy. This is particularly important in fields like healthcare, where anonymized data can be used to advance medical research and improve patient care outcomes without exposing personal health information.
- Public Trust: Effective de-identification techniques build public trust in how organizations handle data. When individuals know that their personal information is treated with care and used responsibly, they are more likely to trust and engage with businesses and services.
- Innovation and Research: De-identification enables the safer use of large-scale data analytics and machine learning across various domains, including public health, urban planning, and personalized medicine. This can lead to innovations that might not be possible if stringent data privacy constraints blocked access to data.
With Generative AI Lab, sensitive data is de-identified by removing or obscuring personal identifiers from datasets to prevent the identification of individuals, thereby mitigating privacy risks while still allowing valuable data to be used for research and analysis and for training AI models that are safe, robust, and fair.
The workflow is simple, Generative AI Lab provides an intuitive user interface combined with advanced features to allow applying best practice over the data.
Key de-identification features of Generative AI Lab include:
- De-identification Projects
- Export of de-identified dataset or documents
- Import de-identified data for further processing and AI model training or tunning
Generative AI Lab supports the following comprehensive de-identification types:
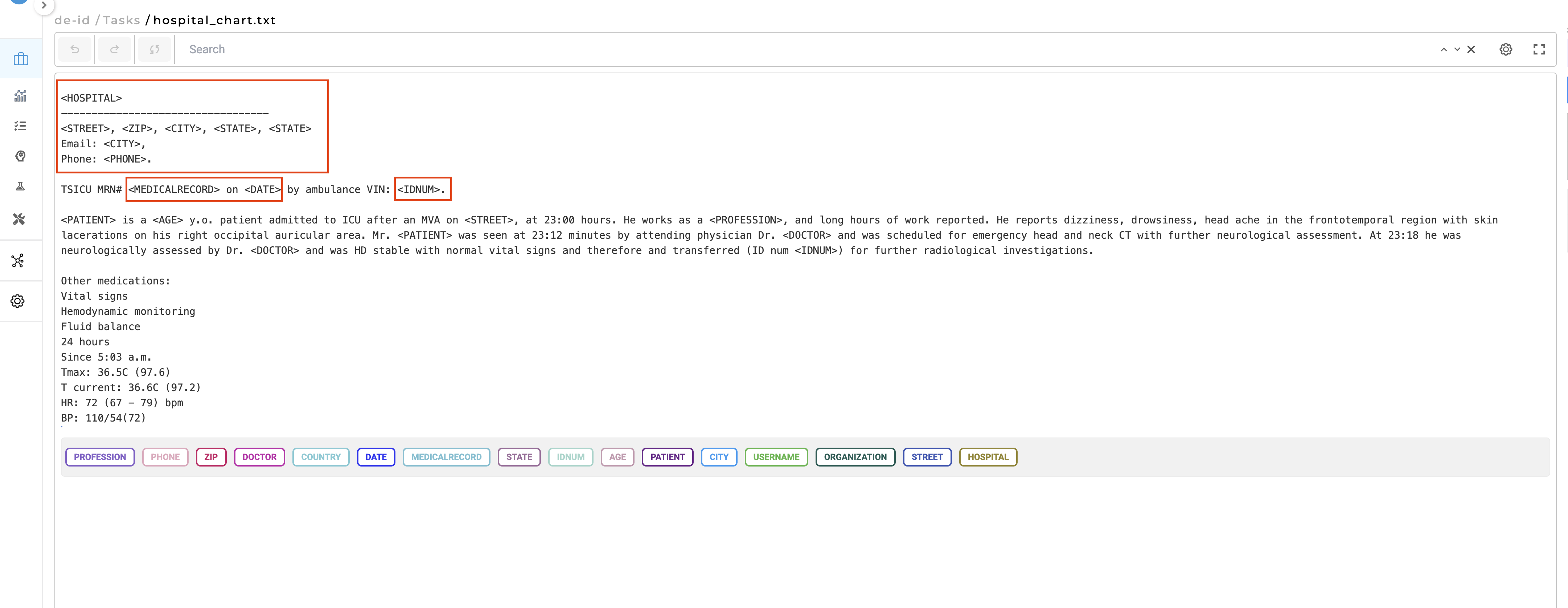
- Mask with Entity Labels: this method replaces identified tokens with their corresponding label names.
For example, in the sentence “John Davies is a 62 y.o. patient admitted to ICU after an MVA,” where ‘John Davies’ is labeled as ‘Patient’ and ’62’ as ‘Age’, the de-identified text would appear as: “<Patient> is a <Age> y.o. patient admitted to ICU after an MVA.”
- Mask with Characters: Here, all characters in the identified tokens are replaced with asterisks (). Using the previous example, if ‘John Davies’ was labeled as ‘Patient’ and ’62’ as ‘Age’, the de-identified text would read: “*** ****** is a ** y.o. patient admitted to ICU after an MVA.” This approach maintains the same character count as the original text.
- Mask with Fixed Length Characters: Identified tokens are replaced with a fixed number of asterisks (). For the same text, the result would be: “ **** is a **** y.o. patient admitted to ICU after an MVA.”
- Obfuscation: This method substitutes identified tokens with fictitious equivalents. In the example given, the obfuscated text would become: “Mark Doe is a 48 y.o. patient admitted to ICU after an MVA.”
Each of these methods provide different levels of anonymity, allowing users to choose the best option based on their specific needs for privacy and data utility.
Workflow and configuration of de-identification projects with Generative AI Lab
There are a few easy steps required when de-identification is used:
1. Project Creation
When setting up a new project, first define the project name and configure the general settings. Then, at the bottom of the Project Setup page, enable the de-identification feature and choose your preferred method of anonymization.
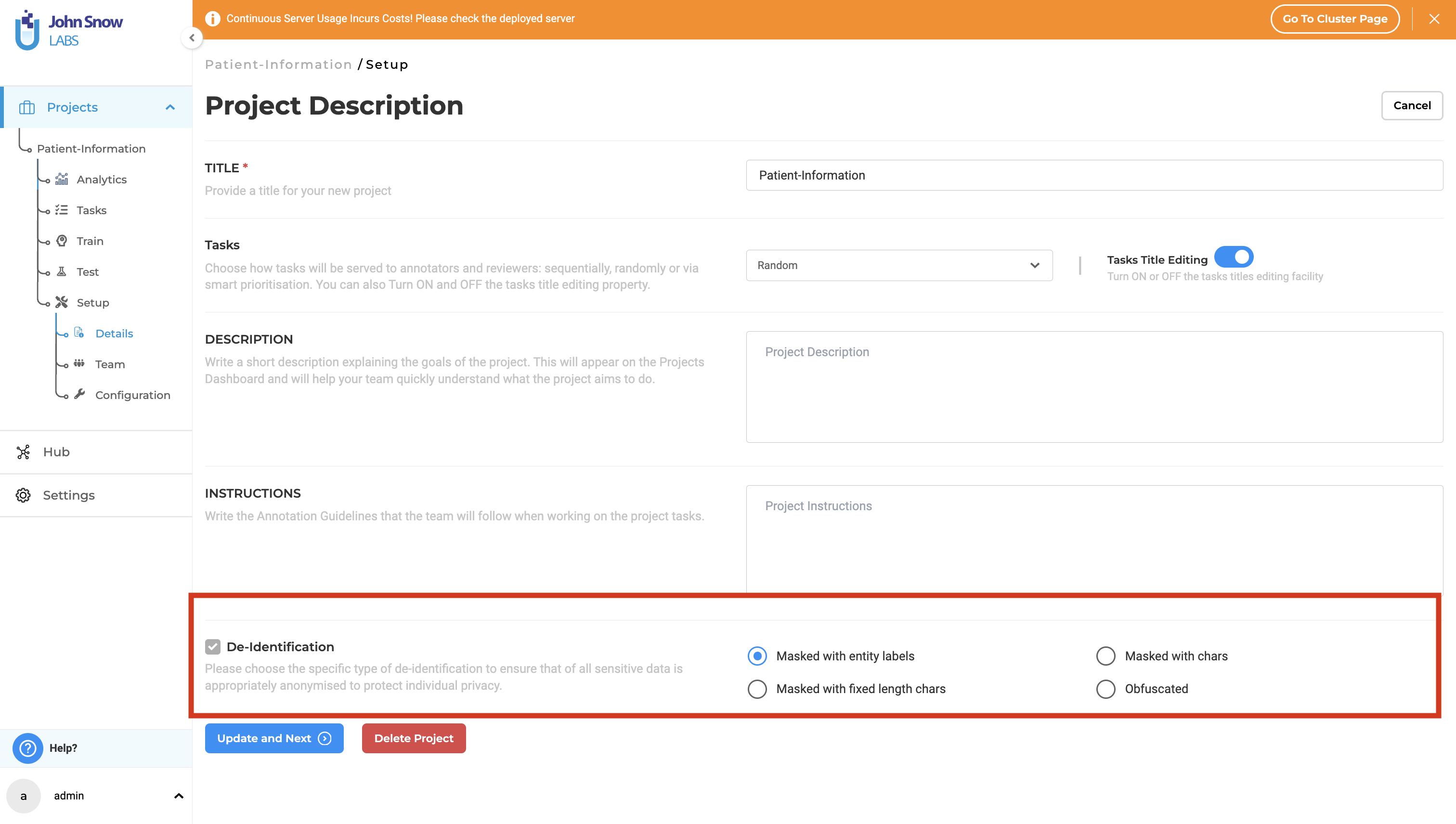
2. Project Configuration
Configure your project to utilize sensitive labels from existing Named Entity Recognition (NER) Models, Rules, and Prompts. Additionally, you have the option to create custom labels for manually annotating the entities you wish to anonymize in your documents.
When selecting pre-annotation resources for your project, take care to ensure that essential downstream data is not mistakenly identified and removed. For example, if you pre-annotate documents using models, rules, or prompts that detect diseases, these labels will be anonymized upon export, making them inaccessible to the end users of the documents.
To prevent such issues, use pre-trained or custom de-identification models and enhance them with rules and prompts that are specifically designed for your unique document identifiers. Furthermore, you can selectively maintain certain labels from each model in your project settings. For instance, if retaining age information is critical for your end-users, you can choose not to anonymize this label so that it remains visible in the exported documents.
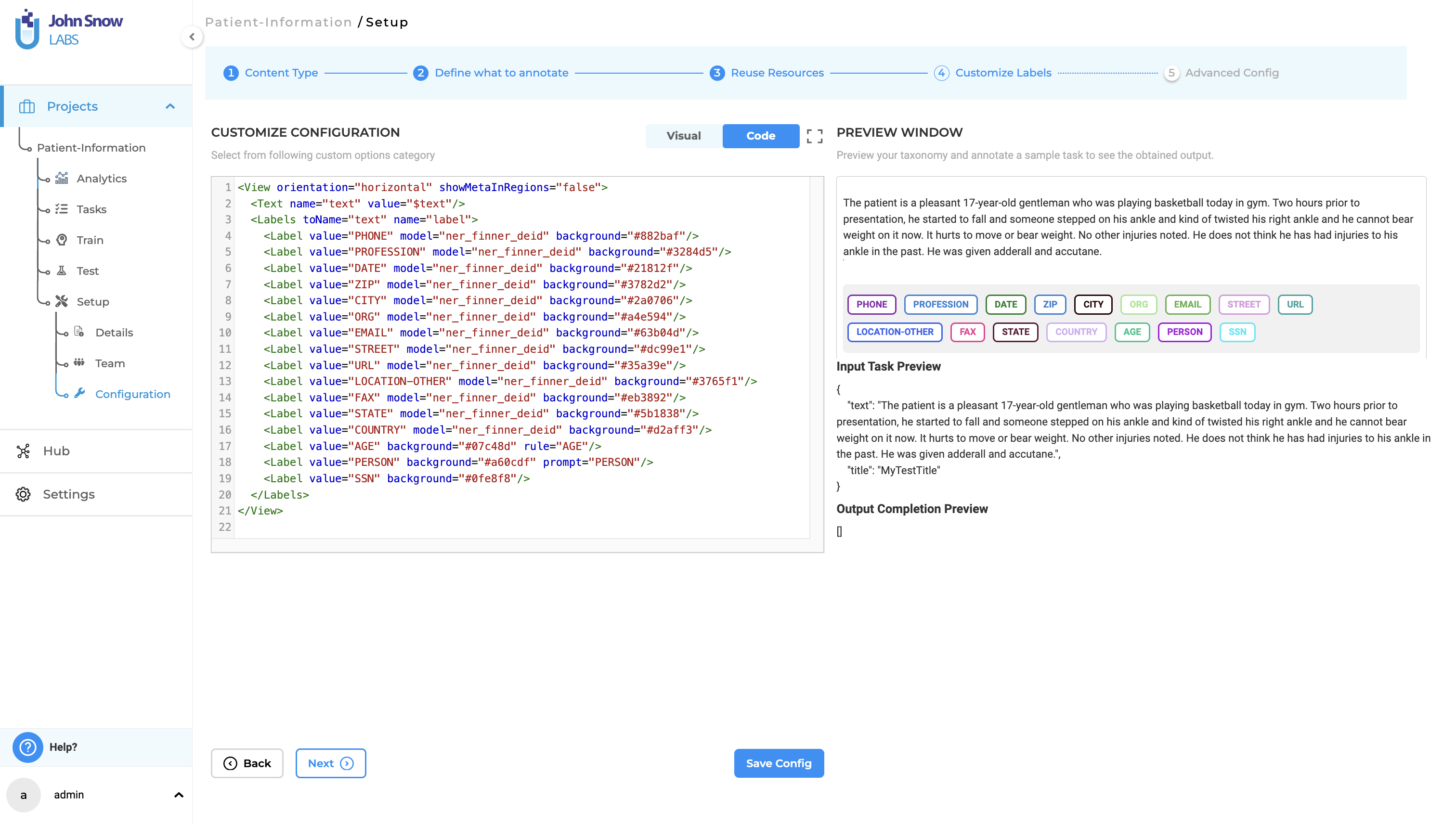
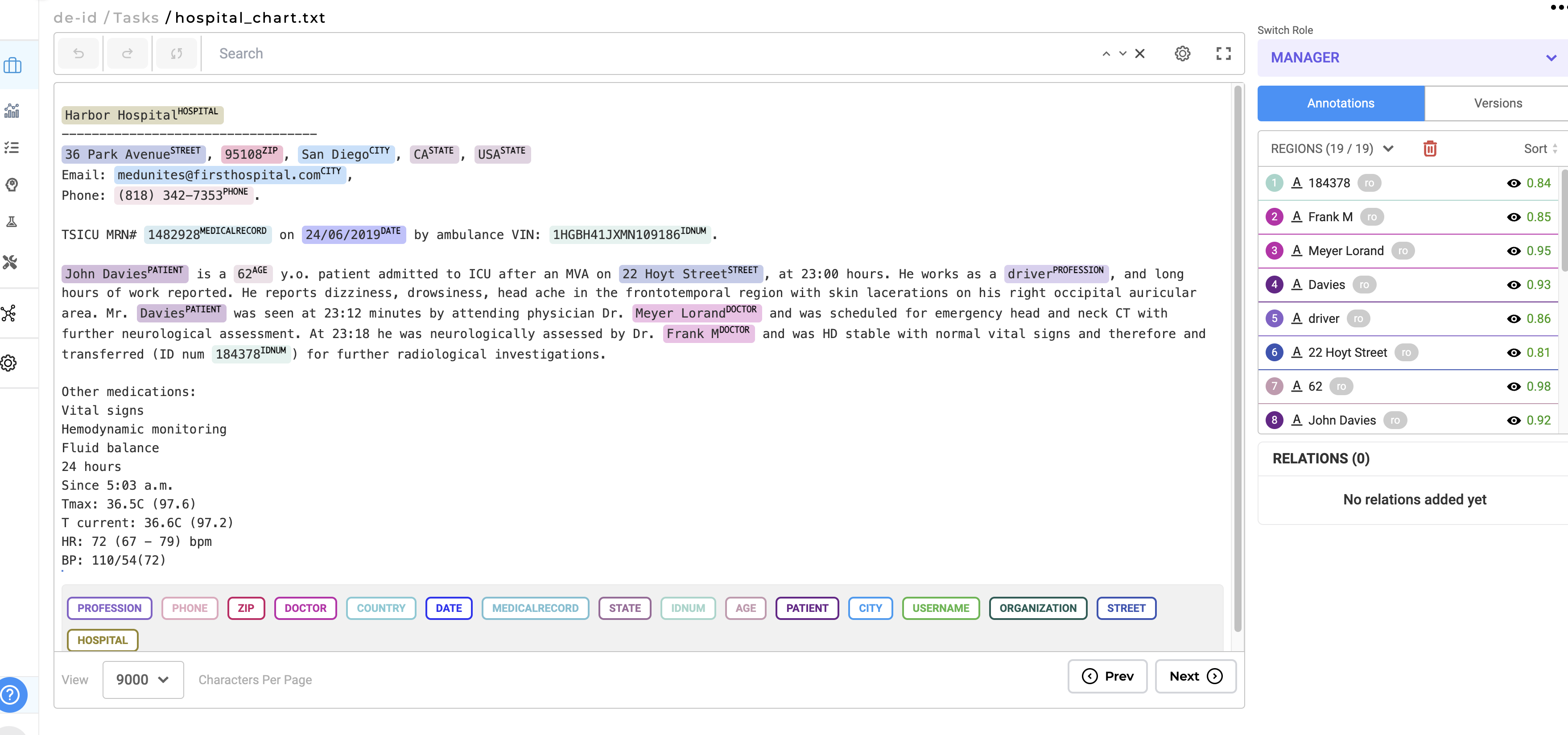
3. Pre-annotate your documents
Once your project is established and tasks are imported, activate the pre-annotation feature to automatically pinpoint sensitive information. Implement a review process where your team examines the pre-annotations through the standard annotation workflow. During this review, make manual adjustments or annotations to any sensitive sections as needed. It’s crucial to ensure that all sensitive information is accurately identified and labeled to guarantee effective de-identification.
4. Export De-identified Documents
Once the labeling process is finished, move forward with exporting the de-identified documents. On the export page, make sure to select the “Export with De-identification” option to produce documents that have been anonymized.
During the export phase, de-identification is carried out according to the anonymization method chosen during the project setup. This de-identification setting can be modified at any time as needed.
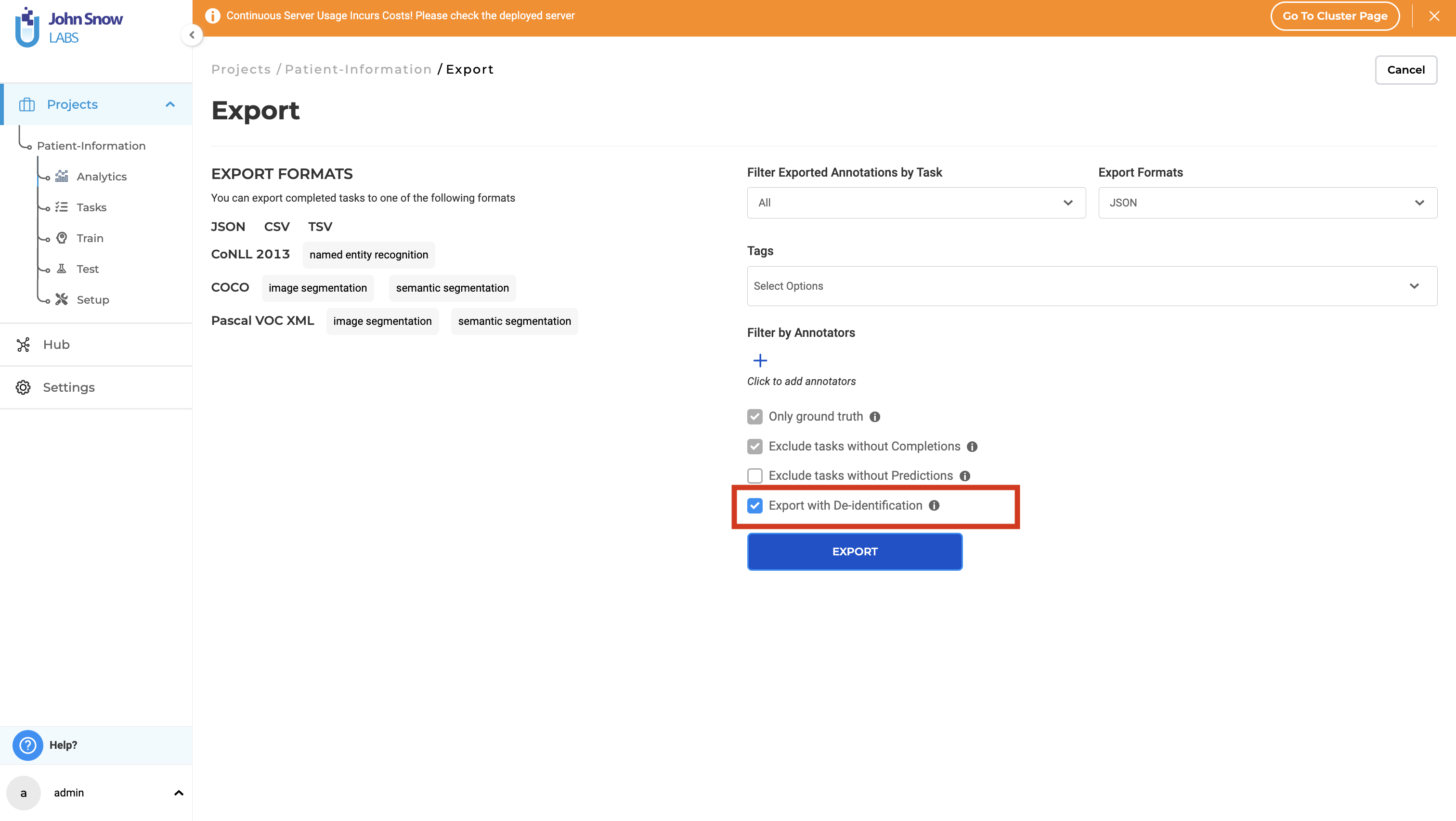
Pre-annotations alone are not sufficient for exporting de-identified data. Only “starred” completions are considered during the export of de-identified tasks. This means that each task intended for de-identified export must be validated by a human user, with at least one completion marked with a star by an annotator, reviewer, or manager.
In instances where multiple submissions exist from various annotators, the de-identification process will prioritize the “starred” completion from the highest priority user as specified on the Teams page. This ensures that de-identification is based on the most relevant and prioritized annotations.
5. Import and Train AI model
Once exported, the tasks can be re-imported into any text-based project for further data extraction if necessary or if you wish to utilize them for model training or tuning.
Getting Started is Easy
Generative AI Lab is a text annotation tool that can be deployed in a couple of clicks using either Amazon or Azure cloud providers, or installed on-premise with a one-line Kubernetes script.
Get started here: https://nlp.johnsnowlabs.com/docs/en/alab/install





