Patient Journey Intelligence
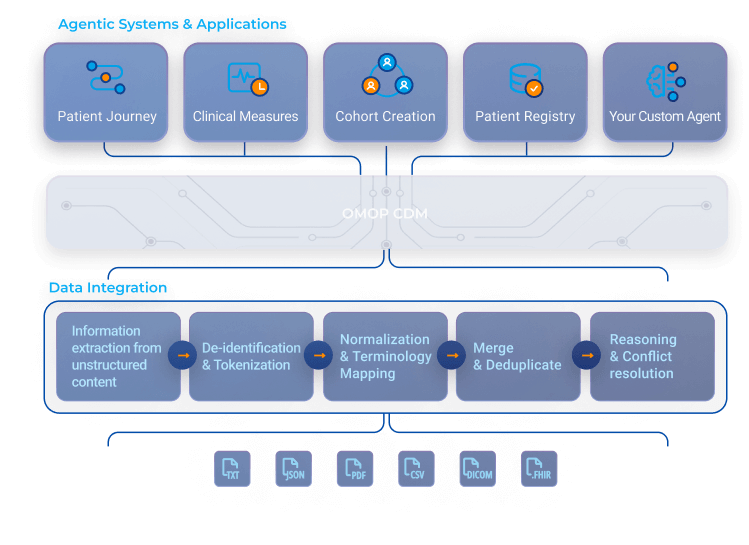
Messy In. Trusted out. Ingest any multimodal patient data (PDFs, notes, FHIR, DICOM, EHR). Get a unified, de-identified OMOP dataset with normalized data, resolved conflicts, and built-in confidence and provenance.
Unified Foundation for Secondary Use. Power cohort building, AI agents, patient registries, and clinical research on top of trusted, enriched, standardized patient records.