
























































What is Clinical Data Abstraction
Creating large-scale structured datasets containing precise clinical information on patient itineraries is a vital tool for medical care providers, healthcare insurance companies, hospitals, medical research, clinical guideline creation, and real-world evidence. Clinical data abstraction refers to the process of finding and recording relevant administrative and clinical data pieces. This NLP clinical solution collects data for administrative coding tasks, quality improvement, patient registry functions, and clinical research.
The end goal of clinical data abstraction is to obtain equivalent structured counterparts that are easier to understand and act upon. Clinical data abstraction is a standard process in many hospitals and healthcare facilities, which requires enormous amounts of specialized work to extract data from noisy and unstructured sources. Historically, there have been three major barriers to automating this process.
Healthcare Data Abstraction: The Three Barriers
To begin with, each project has its own sets of rules for what, how, and when data should be extracted and normalized. Second, the information is frequently derived from natural language documents or a combination of structured, imaging, and document sources. Thirdly, near-perfect precision is necessary for medical decision-making. Thus, the models that attain 90% accuracy, for example, are just insufficient.
The automated clinical data abstraction process
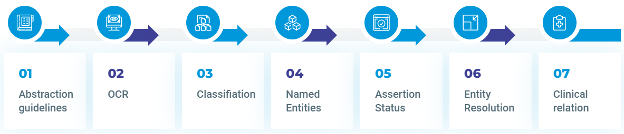
In general, clinical NLP abstraction projects follow these generic steps:
If the personal information is not important, the data de-identification step is included after the NLP OCR step. The personal information is removed and the subsequent steps deal with the data without any personally identifiable information (PII).
1. Abstraction Guidelines
We create clinical data abstraction guidelines during this step, describing in detail which information should be abstracted. For example, in a clinical text, guidelines specify, among others, diseases, tests, treatments for extraction; comorbidities; the time range of the interest; if family history is taken into account; how to record differential diagnosis; how to extract suspected allergies.
Risk analysis needs to be conducted if a de-identification step is present in the abstraction pipeline. Each potential piece of personal information is examined and a proper way of removal is decided. It may result in masking, obfuscation, generalization, etc. We have described the possibilities in detail in this previous article ‘Accurate Medical Data De-Identification With John Snow Labs’ De-Identification Service‘.
Abstraction guidelines are also a marker of how a healthcare provider organizes the abstraction function, viz-a-viz, the best practices.
2. OCR
The first step of document processing is usually a conversion of scanned PDFs to text information. The documentation can also include DICOM or other medical images, where both metadata and text information shown on the image needs to be converted to plain text. The OCR engine needs to be enterprise-level, i.e., robust, accurate, and scalable for large volumes of data.
3. Classification
The clinical data abstraction steps usually depend on the type of document. That is, different information is extracted from the Radiology report than from Discharge Summary or Lab Report. The classification step automatically determines the document type from the document’s content.
Even if the document type is specified externally, it is advantageous to check the document type with the automatic classifier to avoid errors due to the input data.
4. Named Entities in Clinical Data Abstraction based on NLP
One of the most important tasks in NLP is named-entity recognition. Named entity recognition is a natural language processing technology that automatically scans full documents, extracts fundamental elements from the text, and categorizes them. For example, if you choose radiology samples, you will use specialist taxonomy that includes labels such as body parts or medical devices measuring test results, imaging procedures, etc.
This is the initial stage of obtaining structured data from the natural language text content.
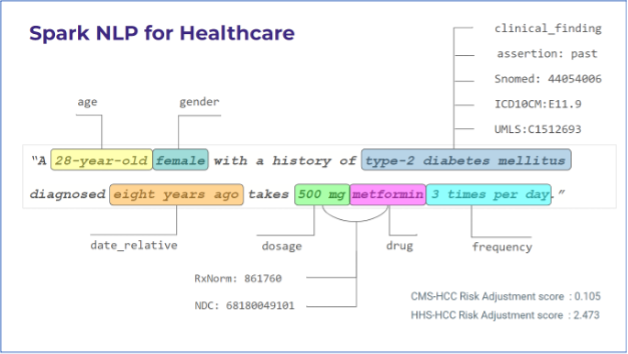
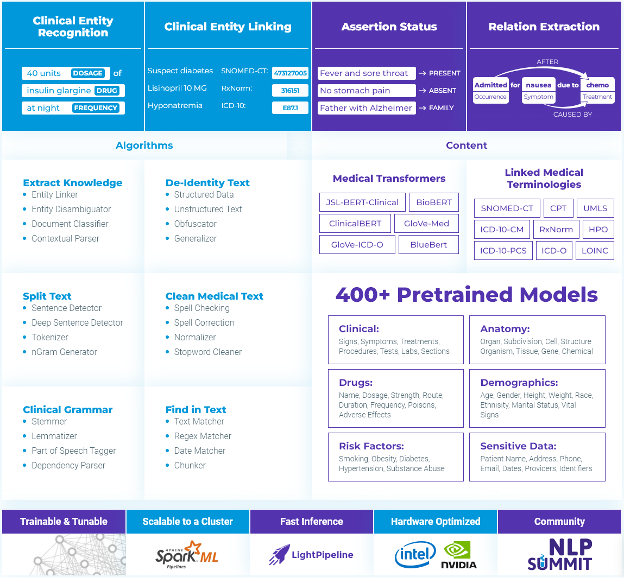
5. Assertion status
The goal of assertion extraction is to categorize assertions about given medical concepts in the present; absent, or possible in the patient; conditionally present in the patient under certain conditions; hypothetically present in the patient at some future point; mentioned in the patient report but associated with someone else formats. For e.g., the sentence “No alopecia noted” extracts alopecia as a problem, but with “Absent” assertion status.
6. Entity Resolution
Entity resolution is the mapping of extracted entities to selected taxonomy, e.g., ICD-10, ICDO, SNOMED, RxNORM, etc. Often, mapping needs to take into account the context of the sentence, e.g., there is another code of “CT” and “CT of abdomen”.

7. Clinical Relation
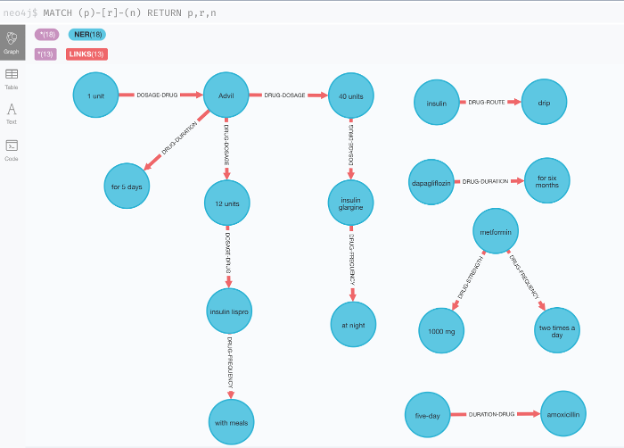
Information is not unidimensional. If organized in a knowledge graph, it adds additional information to the extracted data. The extracted information during clinical data abstraction can be augmented by extracting temporal relations (earlier-later-overlapping), posology relations (drug-adverse effect, drug-form/frequency/route, etc.), clinical relations (test-problem-treatment, treatment-improvements/deterioration of illness, etc.), admission discharge, the interaction of drugs, genes, etc.
The extracted information can be saved in a standard (SQL-like) or graph database.
Conclusion
Modern methods of medical records abstraction, such as NLP/AI, can increase the efficiency and effectiveness of data abstraction across registries through automation. Clinical natural language processing can improve the value proposition for hospitals interested in participating in current and future registries. This strategy has the potential to reduce the stress and cost of human data abstraction, increase hospitals’ access to data, and unlock the true potential for quality improvement and clinical data extraction.
All the examples above can be delivered with Spark NLP for Health and Spark OCR. The Solution can be delivered in a range of options:
- We can provide clinical data abstraction as a service.
- We license Spark NLP for Healthcare and Spark OCR and provide professional services to build a solution.
- We provide license and support, allowing the customer to build the solution.
Why us?
- Spark NLP is an award-winning software, the most widely used NLP software in the industry
- Currently holding 14 top positions for the most accurate methods in “papers with code”
- It was developed for enterprise stability, speed, and scalability.




