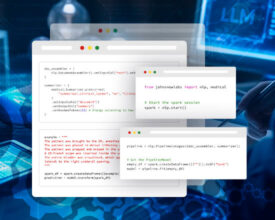
John Snow Labs, the award-winning Healthcare AI and NLP company, announced the latest major release of its Spark NLP library – Spark NLP 5 – featuring the highly anticipated support...
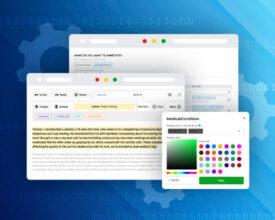
The realm of Natural Language Processing has been growing exponentially, bringing about a host of advancements that are pushing the boundaries of technology and its application. The NLP Lab, a...
In this post we show how to use Healthcare NLP to summarize clinical jargon in layman terms at Scale on Spark using the Summarizer annotator. Introduction Reading clinical notes when...
The latest version of Legal NLP comes with a new classification model on Law Stack Exchange questions and Named-Entity Recognition on Subpoenas, which will raise the efficiency of NLP for...

































































 See More
See More