



























































Stemming and lemmatization are vital techniques in NLP for transforming words into their base or root forms. Spark NLP provides powerful capabilities for stemming and lemmatization, enabling researchers and practitioners to improve the quality of their NLP tasks and extract more meaningful insights from text data. By following the implementation steps outlined in this article, you can seamlessly incorporate stemming and lemmatization into your NLP pipelines using Spark NLP. Leverage the benefits of Spark NLP’s scalability, language support, and integration with Apache Spark to boost your NLP results and unlock the full potential of your text analysis endeavors.

Introduction
Natural Language Processing (NLP) tasks often involve the need to transform words into their root forms for better analysis and understanding. Stemming and lemmatization are two essential techniques used to achieve this goal. In this article, we will explore how Spark NLP, a powerful Python library built on Apache Spark, provides efficient stemming and lemmatization capabilities. We will delve into the benefits of using stemming and lemmatization, discuss the implementation details with Spark NLP, and highlight how these techniques can significantly enhance your NLP results.
The Importance of Stemming and Lemmatization in NLP
Stemming and lemmatization play a crucial role in NLP by reducing words to their base or root forms. These techniques normalize the text, allowing for more accurate analysis, information retrieval, and language understanding. By reducing inflected or derived words to their base forms, stemming and lemmatization helps identify common word forms and improve the quality of NLP tasks such as information retrieval, sentiment analysis, topic modeling, and more.
Stemming is a natural language processing (NLP) technique that involves reducing words to their base or root form, known as the “stem.” The stem is a shorter representation of a word that encompasses its core meaning. Stemming aims to remove prefixes, suffixes, and inflections from words, allowing variations of a word to be treated as the same root word. This process helps in reducing vocabulary size, normalizing text, and improving text analysis tasks such as information retrieval, text classification, and sentiment analysis. Stemming algorithms apply a set of rules or heuristics to identify and remove affixes, resulting in the stem form of a word. However, stemming does not always produce valid or meaningful words, as it focuses on linguistic reduction rather than semantic accuracy.
Please note that different stemming algorithms may produce different stems for the same word, and some stems may not be actual valid words in the language. Stemming aims to reduce words to their core form for analysis purposes, sacrificing semantic accuracy for linguistic normalization.
Lemmatization is a natural language processing (NLP) technique that involves reducing words to their base or dictionary form, known as the “lemma.” Unlike stemming, which simply removes affixes from words to derive a root form, lemmatization takes into account the word’s part of speech and context to determine its canonical form. The resulting lemma represents the base meaning of the word and is a valid word found in a dictionary. Lemmatization aims to normalize words while preserving their semantic integrity, making it a more linguistically accurate approach compared to stemming. By transforming words into their lemmas, lemmatization helps improve text analysis, information retrieval, and language understanding tasks in NLP.
In lemmatization, the resulting lemma represents the canonical or base form of a word, considering its part of speech and context. Lemmatization provides linguistically valid and meaningful lemmas, which can enhance the accuracy of text analysis and language processing tasks.
Let’s see some examples of words and their stems and lemmas:
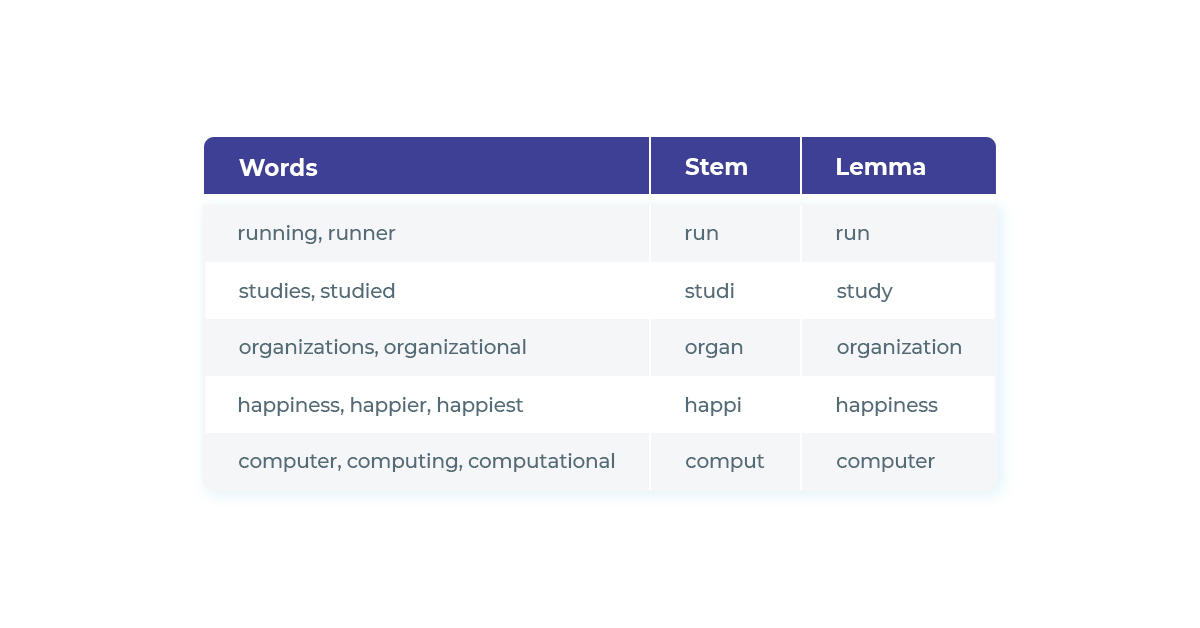
Examples of stems and lemmas
In Spark NLP, the implemented algorithm for Stemmer is Porter’s algorithm, while for lemmatization is an approach that uses dictionaries of lemmas and the associated words.
Stemming and Lemmatization with Python
Certainly! Here is an updated summary of Python libraries that implement stemming and lemmatization techniques, including Spark NLP, along with their corresponding websites:
- NLTK (Natural Language Toolkit): NLTK is a comprehensive library for NLP tasks, including stemming and lemmatization. It offers various stemmers (e.g., Porter, Snowball) and WordNet – based lemmatizer.
- spaCy: spaCy is a powerful NLP library that supports lemmatization. It provides a rule-based lemmatizer that considers the context and part of speech of words using edit trees or look-up tables based on Part-of-Speech tags.
- Gensim: Gensim is primarily known for topic modeling, but it also offers stemming capabilities using the Porter stemming algorithm. It provides a simple interface for stemming words and documents.
- Stanford CoreNLP: Stanford CoreNLP is a suite of NLP tools that includes a lemmatizer. It offers robust lemmatization capabilities and supports multiple languages.
- Spark NLP: Spark NLP is a powerful library built on Apache Spark for natural language processing. It provides efficient stemming and lemmatization annotators, along with other NLP functionalities.
In this article, we focus on using Spark NLP, which contains the capability to perform both Stemming (for English) and Lemmatization (pretrained models for more than sixty different languages).
Implementing Stemming and Lemmatization with Spark NLP
Spark NLP provides comprehensive support for stemming and lemmatization through its annotators, making it easier to incorporate these techniques into your NLP pipelines. Let’s explore the steps to implement stemming and lemmatization using Spark NLP:
1. Setting up Spark NLP
Ensure that you have Spark NLP installed by executing the following command:
pip install spark-nlp
Import the required classes and objects and start a spark session:
import sparknlp from sparknlp.annotator import Stemmer, LemmatizerModel from sparknlp.base import DocumentAssembler, Pipeline spark = sparknlp.start()
2. Loading and Preprocessing Text Data
Load your text data into a Spark DataFrame. Make sure the text column is named appropriately, such as “text”:
data = [("1", "I am loving Spark NLP's capabilities."),
("2", "The cats are playing in the garden.")]
df = spark.createDataFrame(data, ["id", "text"])
3. Applying Stemming and Lemmatization Annotators
Initialize the Stemmer and LemmatizerModel annotators and specify the input and output columns:
stemmer = Stemmer().setInputCols(["token"]).setOutputCol("stem")
lemmatizer = (
LemmatizerModel.pretrained().setInputCols(["token"]).setOutputCol("lemma")
)
We used the LemmatizerModel annotator that automatically downloads a pretrained model that is ready to be used (default model is “lemma_antbnc” for English language, but other models are available at the NLP Models Hub). Stemmer is rule-based, so there is no pretrained models.
4. Building the Pipeline
Create a pipeline that includes the necessary stages for tokenization, stemming, and lemmatization:
document_assembler = (
DocumentAssembler().setInputCol("text").setOutputCol("document")
)
tokenizer = Tokenizer().setInputCols(["document"]).setOutputCol("token")
pipeline = Pipeline(
stages=[document_assembler, tokenizer, stemmer, lemmatizer]
)
5. Applying the Pipeline to the Data
Fit the pipeline to your data and transform it to obtain the stemmed and lemmatized results:
model = pipeline.fit(df) result = model.transform(df)
The resulting DataFrame will contain the stemmed and lemmatized versions of the original text.
6. Analyzing and Utilizing the Results
Extract the transformed text from the DataFrame and utilize the stemmed and lemmatized versions for further analysis or downstream NLP tasks:
result.selectExpr("lemma.result as lemma", "stem.result as stem").show(
truncate=False
)
+------------------------------------------+-----------------------------------------+ |lemma |stem | +------------------------------------------+-----------------------------------------+ |[I, be, love, Spark, NLP's, capability, .]|[i, am, love, spark, nlp', capabl, .] | |[The, cat, be, play, in, the, garden, .] |[the, cat, ar, playe, in, the, garden, .]| +------------------------------------------+-----------------------------------------+
stemmed_results = result.select("stem.result").collect()
lemmatized_results = result.select("lemma.result").collect()
for row in stemmed_results:
stemmed_text = row[0]
# Perform analysis or utilize the stemmed text
for row in lemmatized_results:
lemmatized_text = row[0]
# Perform analysis or utilize the lemmatized text
To use the stems and lemmas in other tasks, they can be obtained with simple spark manipulations like:
You can now leverage the stemmed or lemmatized text for tasks like sentiment analysis, topic modeling, clustering, or any other NLP analysis that benefits from normalized text representations.
Benefits of Spark NLP Stemming and Lemmatization
Using Spark NLP’s stemming and lemmatization techniques offers several benefits:
- Improved Analysis: Stemming and lemmatization reduce words to their base forms, allowing for more accurate analysis and identification of common word forms.
- Scalability: Spark NLP leverages the power of Apache Spark, enabling distributed processing of large-scale text data for efficient stemming and lemmatization.
- Seamless Integration: Spark NLP’s annotators seamlessly integrate into NLP pipelines, ensuring a smooth and streamlined workflow for preprocessing and analysis.
Conclusion
Stemming and lemmatization are vital techniques in NLP for transforming words into their base or root forms. Spark NLP provides powerful capabilities for stemming and lemmatization, enabling researchers and practitioners to improve the quality of their NLP tasks and extract more meaningful insights from text data.
By following the implementation steps outlined in this article, you can seamlessly incorporate stemming and lemmatization into your NLP pipelines using Spark NLP. Leverage the benefits of Spark NLP’s scalability, language support, and integration with Apache Spark to boost your NLP results and unlock the full potential of your text analysis endeavors.
References
- Porter, M. F. (1980). An algorithm for suffix stripping. Program: electronic library and information systems, 14(3), 130-137.
- Official implementations of the Porter Stemming Algorithm (tartarus.org)
- Spark NLP — Annotators: Lemmatizer
- Spark NLP — Annotators: Stemmer
- spark-nlp-workshop/open-source-nlp at master · JohnSnowLabs/spark-nlp-workshop · GitHub





