Spark NLP is a Python library that integrates transformer-based models, such as BERT, RoBERTa, and GPT, for efficient and accurate Named Entity Recognition (NER). By using Spark NLP, you can...
Spark NLP offers a powerful Python library for scalable text analysis tasks, and its NGramGenerator annotator simplifies n-gram generation. By following best practices, including setting up Spark NLP, loading and...
The latest version of Legal NLP, 1.15 introduces numerous additional features to the existing collection of 926+ models and 125+ Language Models from previous releases of the library. Let’s examine...
The latest version of Finance NLP, 1.15, introduces numerous additional features to the existing collection of 926+ models and 125+ Language Models from previous releases of the library. Let’s examine...
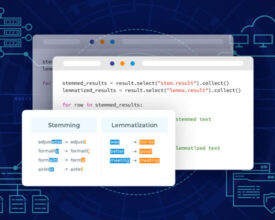
Stemming and lemmatization are vital techniques in NLP for transforming words into their base or root forms. Spark NLP provides powerful capabilities for stemming and lemmatization, enabling researchers and practitioners...




































































 See More
See More