
























































Named Entity Recognition: What Does It Mean
Suppose we have a bio of various candidates and our task is to categorize the data. We need a working model to categorize name, organization, and job profile for finding the relevant candidate from a job portal.
Consider an example of a bio: “Rose has been working at Google as a Data Scientist”.
It is easy for an HR person to understand the details about Rose’s profile, i-e., her name, job, and organization. But what if there are hundreds and thousands of records to checkout for the best matching candidate? Here comes the use of Named Entity Recognition (NER).
The named entity recognition algorithm will process the single sentence from Rose’s bio as:
Rose [name] has been working at Google [organization] as a Data Scientist [job profile].
NER in NLP
An entity refers to a word or a series of words that refers to the same thing. We can identify and classify named entities in text, such as name, organization, designation, experience, location, time, etc. to make recommendations or predictions. Named Entity Recognition (NER) is an NLP approach that finds and extracts entities from unstructured textual documents. It is also called Entity Extraction, Chunking, or Identification. For instance, NER can recommend solutions based on news articles about a particular organization.
We can also use it to extract investment signals from news headlines. Banks and NBFCs (Non-Banking Financial Companies) use NER to extract key information from customer data.
NLP Named Entity Recognition provides them the following benefits:
- Derive better insights about customers
- Analyze credit reports
- Income verification
- Analyze investment portfolios

NER can also be used for the following tasks.
- Content Classification – NER models search key elements from a phrase, sentence, or a paragraph. They help during online searches to find entities like name, location, events, organization, etc from voluminous amounts of articles.
- Content Recommendation – Content recommendation systems have deep learning models that understand the user requirements and recommend content without the user telling the system.
- Data Annotation – It is done via labeling the data. It includes processes such as text analysis, data extraction, indexing, etc.
How does Named Entity Recognition work?
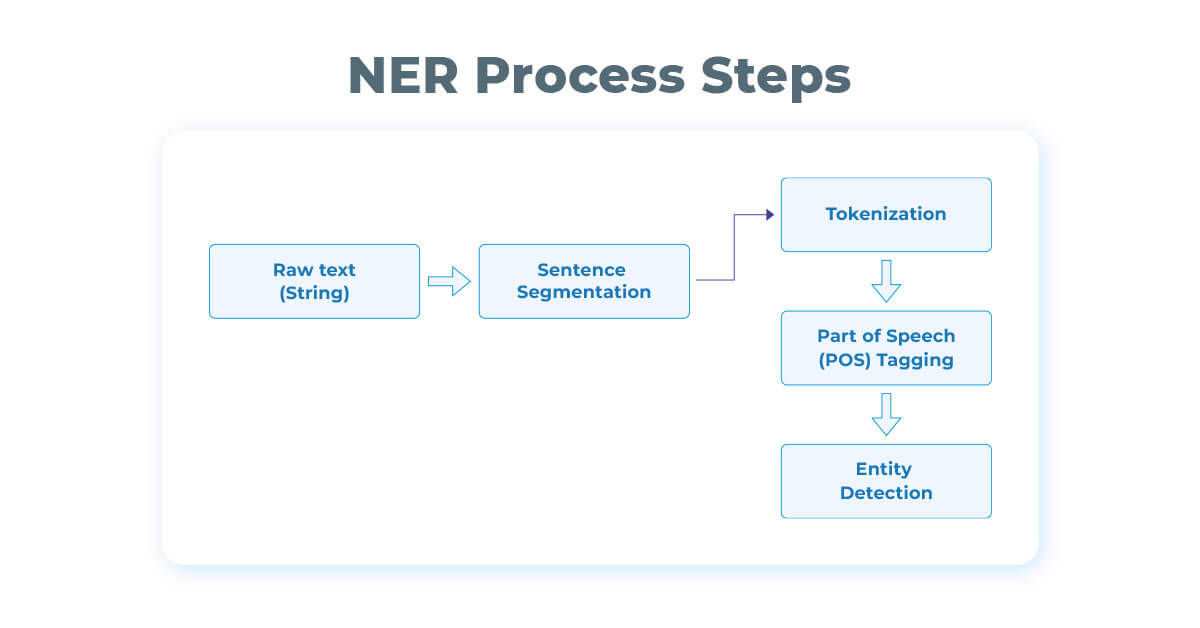
Entity Recognition is the technique of identifying Named Entities from raw text and arranging them into sub groups. Let’s discuss the basic steps involved in NER.
Sentence Segmentation
In the Sentence Segmentation stage, the raw text is divided into its component sentences. The purpose of this step is to assign sentence boundaries and split the text whenever punctuation marks or periods are detected.
Word Tokenization
Tokenization is the most important step to proceed with NLP because we need to identify the words that constitute a string of characters before processing a natural language. Word Tokenization helps in text interpretation by analyzing the words present in it.
Part of Speech Tagging (POS) describes the characteristic structure of lexical terms within a text or sentence. It assigns up a word in a text to a corresponding Part of Speech tag according to its context. With the help of POS tags, we can make assumptions about the text semantics.
Entity Detection
Entity Detection is the last step that completes the purpose of NER. It is the technique of identifying key entities/elements from text and classifying them into predefined categories.
The figure below depicts the NER working.
Applications of Named Entity Recognition
Named Entity Recognition has applications in various domains like:
- Legal
- Finance
- Healthcare and Pharma, etc.
Let’s discuss the top use cases of NER in these domains.
NER in Legal
In the legal domain, named entities of interest can include:
- Judges
- Case parties
- Case numbers
- Court names
- References to laws, etc.
The notable use cases of NER in the Legal space are given below.
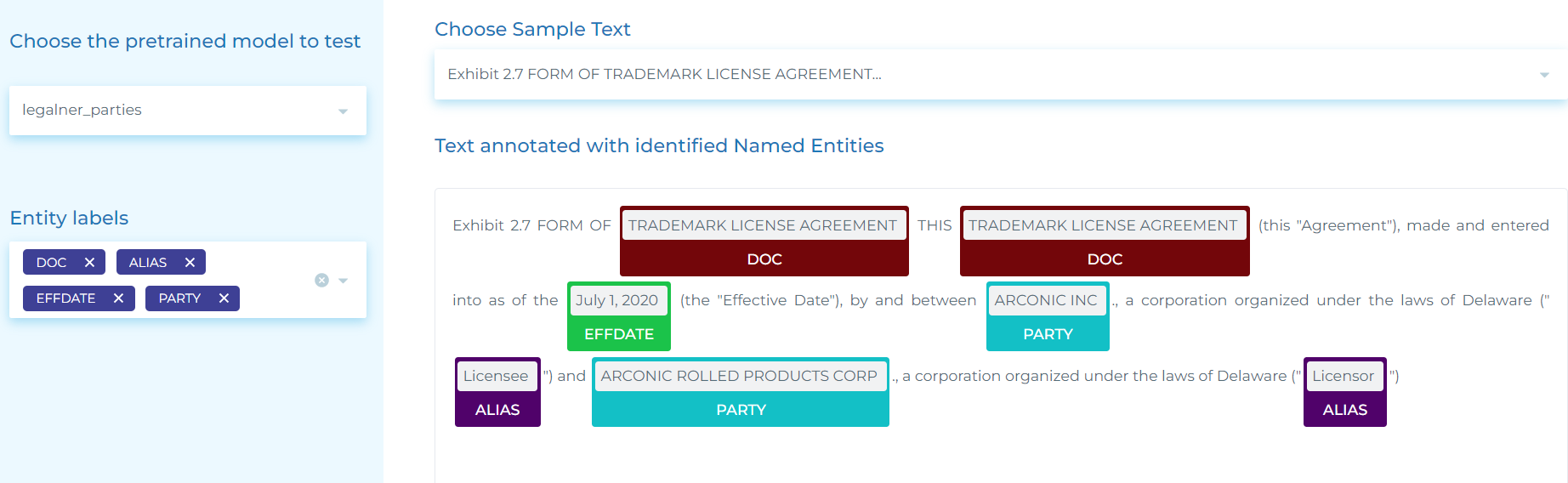
- Extracting DOC (Document Type), PARTY (entity signing a contract), ALIAS (the way a company is named later on in the document) and EFFDATE (Effective Date of the contract).
- Automatic identification of entities such as Organization, Jurisprudence, Legislation, Person, Location and Time, etc., in legal text.

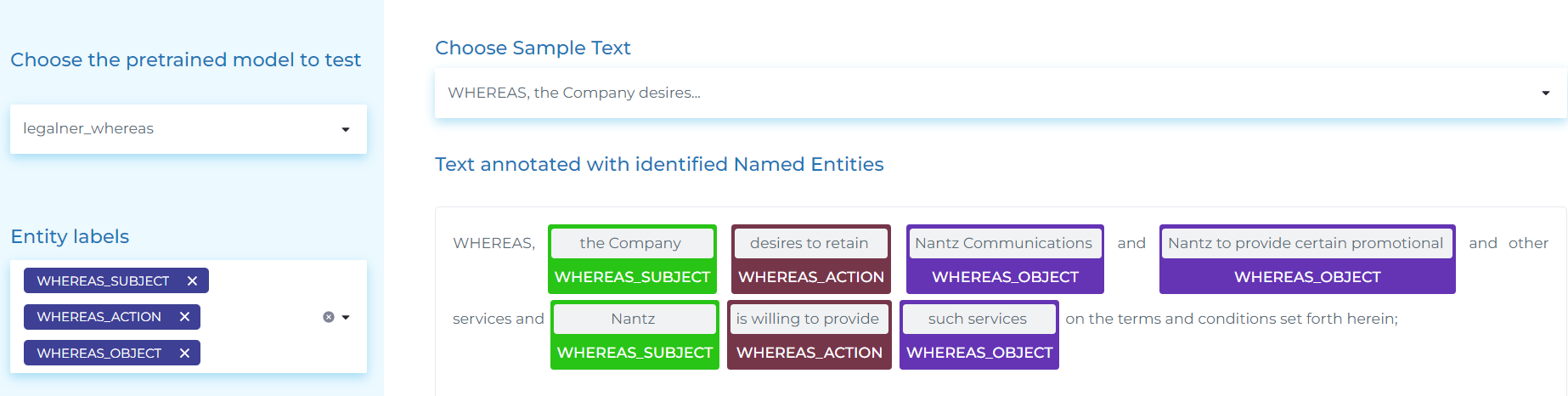
- Detecting Whereas clauses and extracting entities from them, i-e., the SUBJECT, the ACTION and the OBJECT.
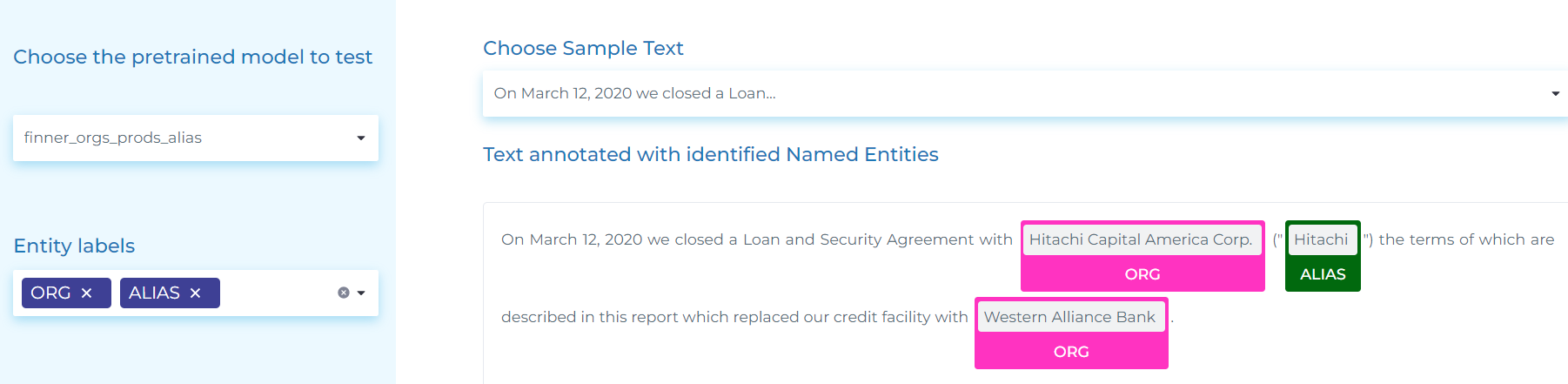
- Identifying ORG (Companies), their ALIAS (other names the company uses in the contract/agreement) and company PRODUCTS.
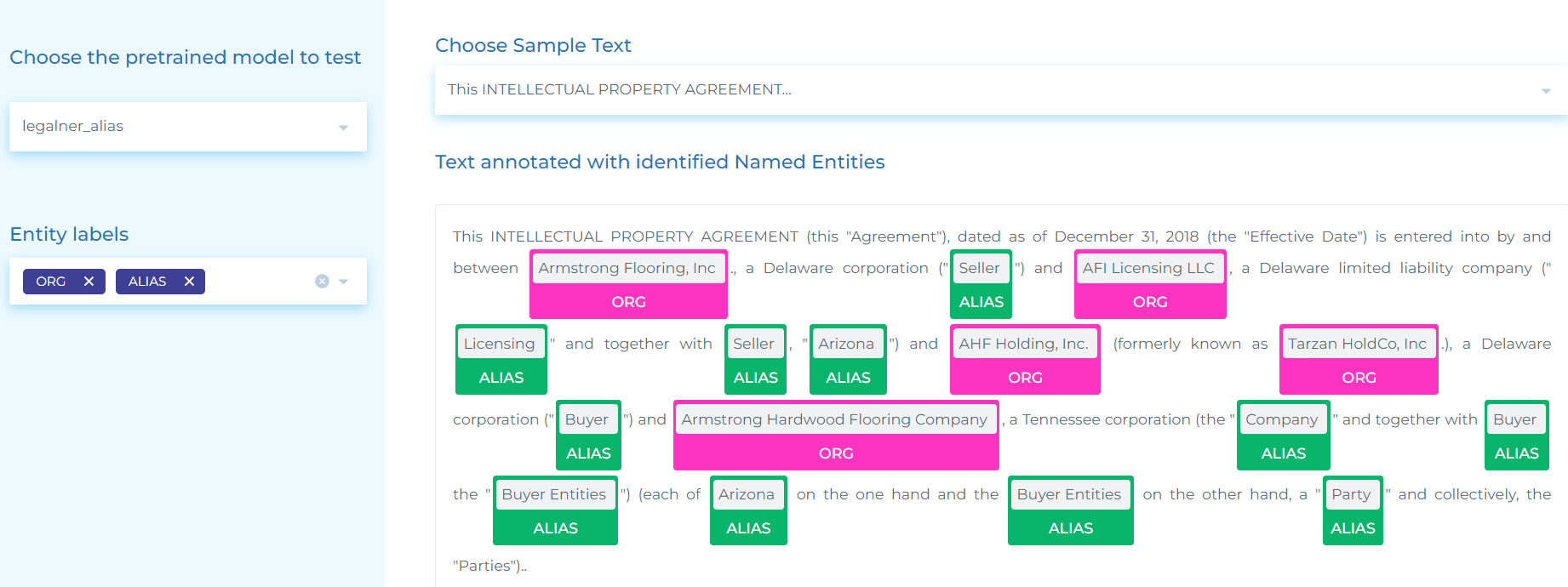
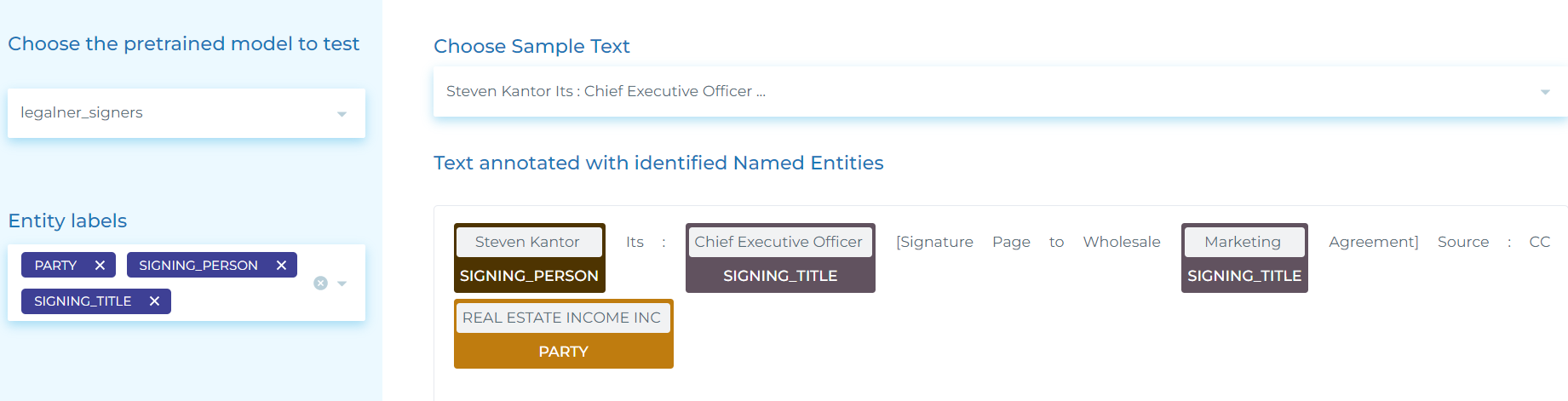
- Extracting SIGNING_PERSON (People signing a document), SIGNING_TITLE (the roles of those people in the company) and PARTY (Organizations).
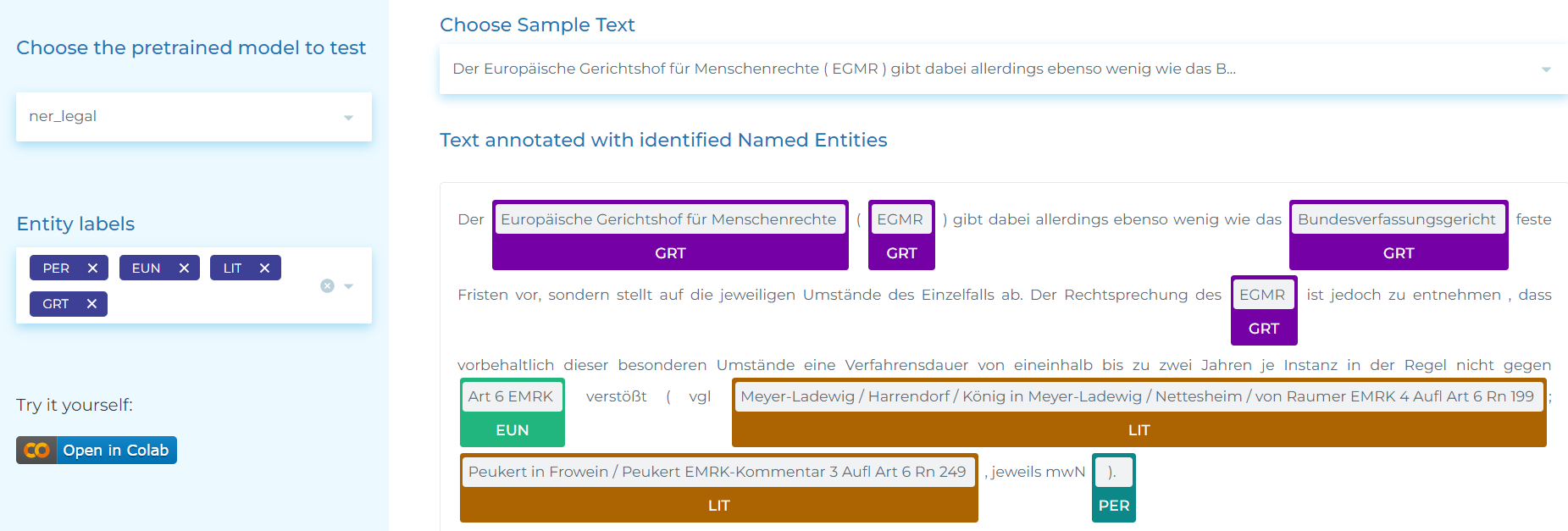
- Automatically identifying entities such as persons, judges, lawyers, countries, cities, landscapes, organizations, courts, trademark laws, contracts, etc. in German legal text.
- Extracting law and money entities from legal texts.
NLP Named Entity Recognition Tools for Finance
Named Entity Recognition is used for NLP in finance market as well. Finance firms use NER to analyze interest rates and loan prepayments periods after data extraction.
Below are the notable use cases of Named Entity Recognition with NLP for financial documents.
- Extracting financial entities from annual reports, as Expenses, Loses, Profit declines or increases, etc.

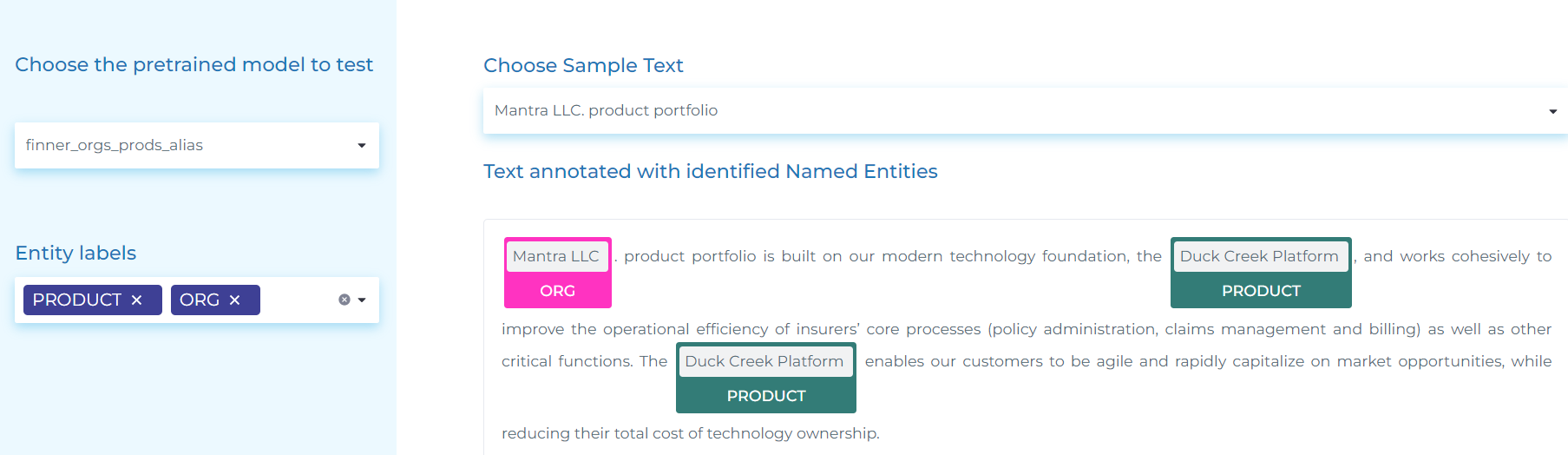
- Extracting ORG (Organization names) and PRODUCT (Product names).
- Extracting information like Company Name, Trading symbols, Stock markets, Addresses, Phones, Stock types and values, IRS, CFN, etc. from the first page of 10-K filings.
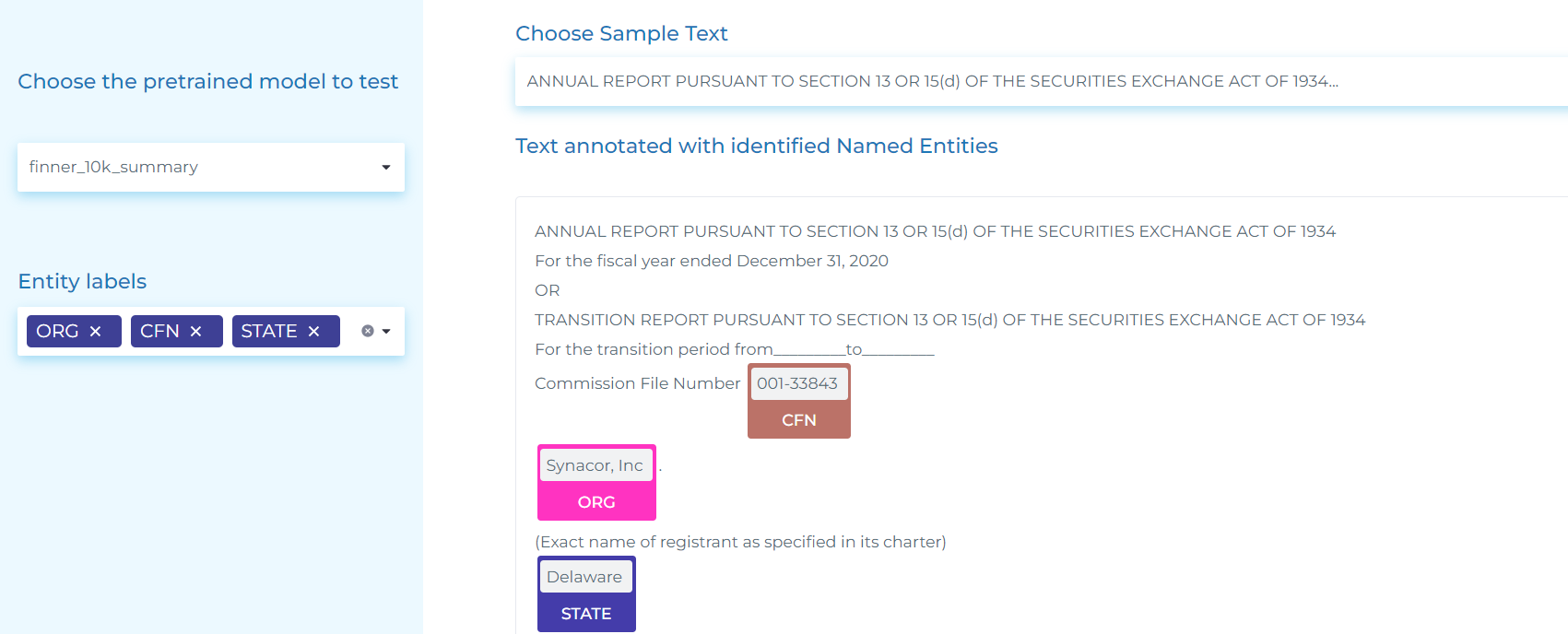
- Identifying ORG (Companies), their ALIAS (other names the company uses in financial reports) and company PRODUCTS.
NER tools in Healthcare and Pharma
Below are the applications of Named Entity Recognition in Healthcare and Pharma.
- Detecting COVID-related clinical terminology.
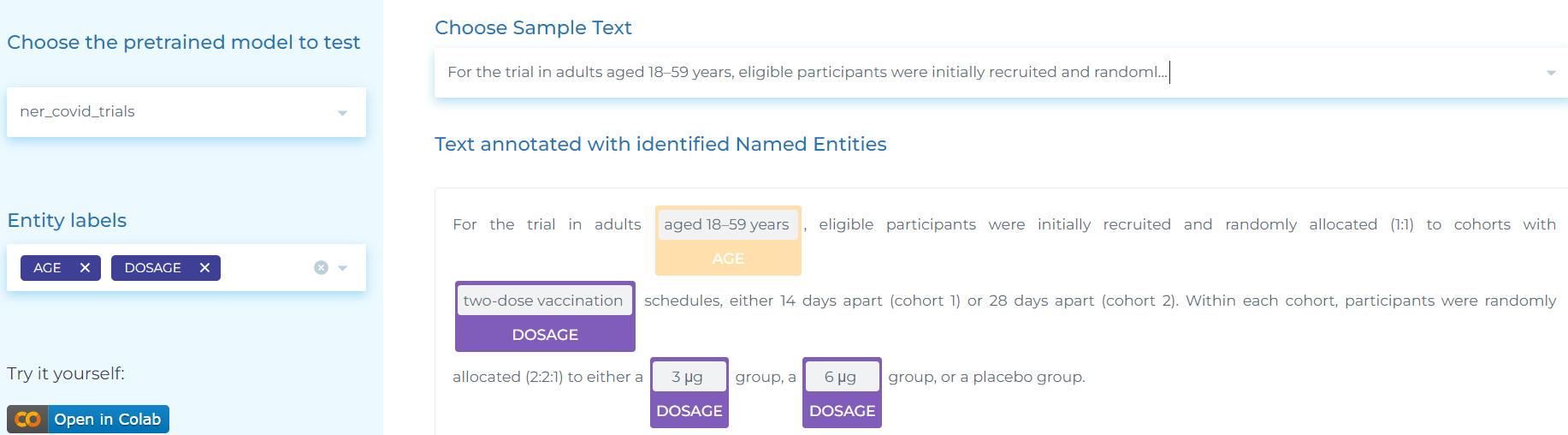
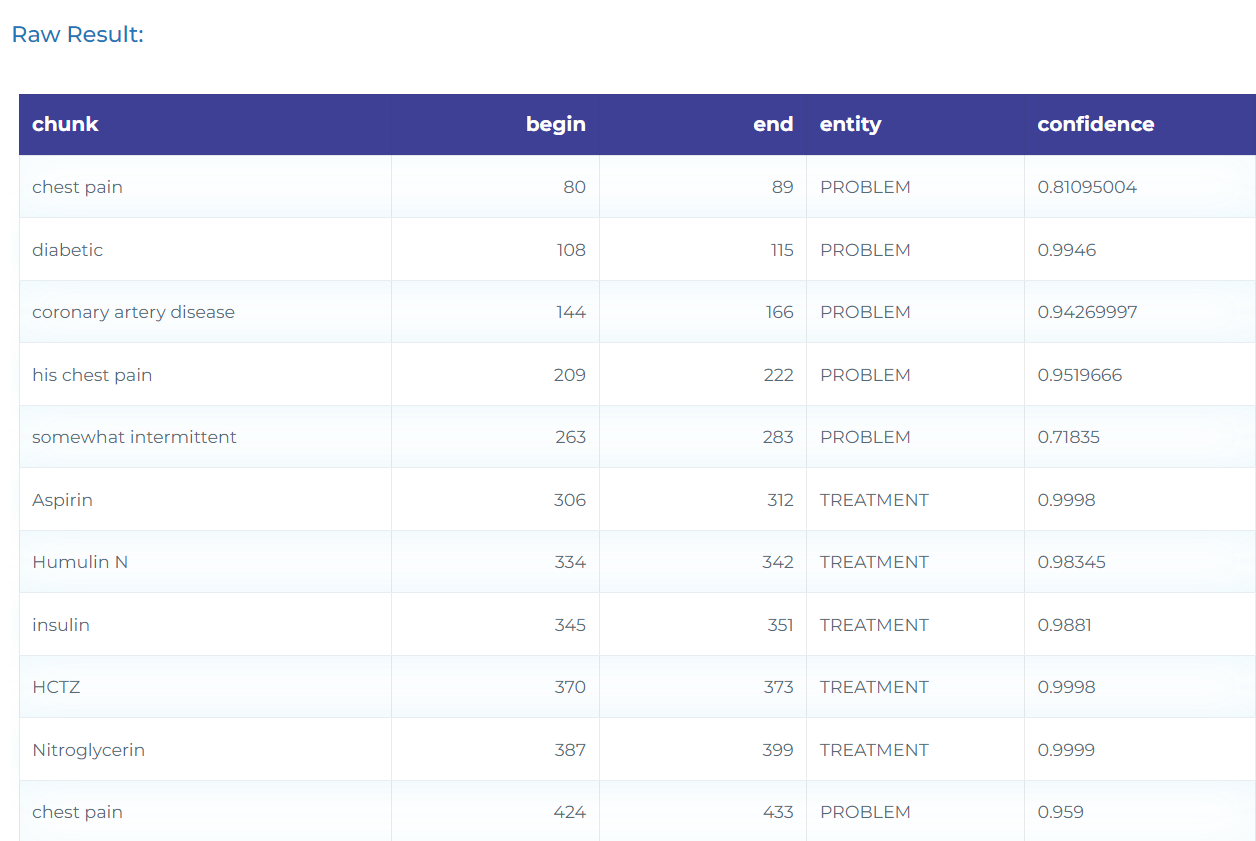
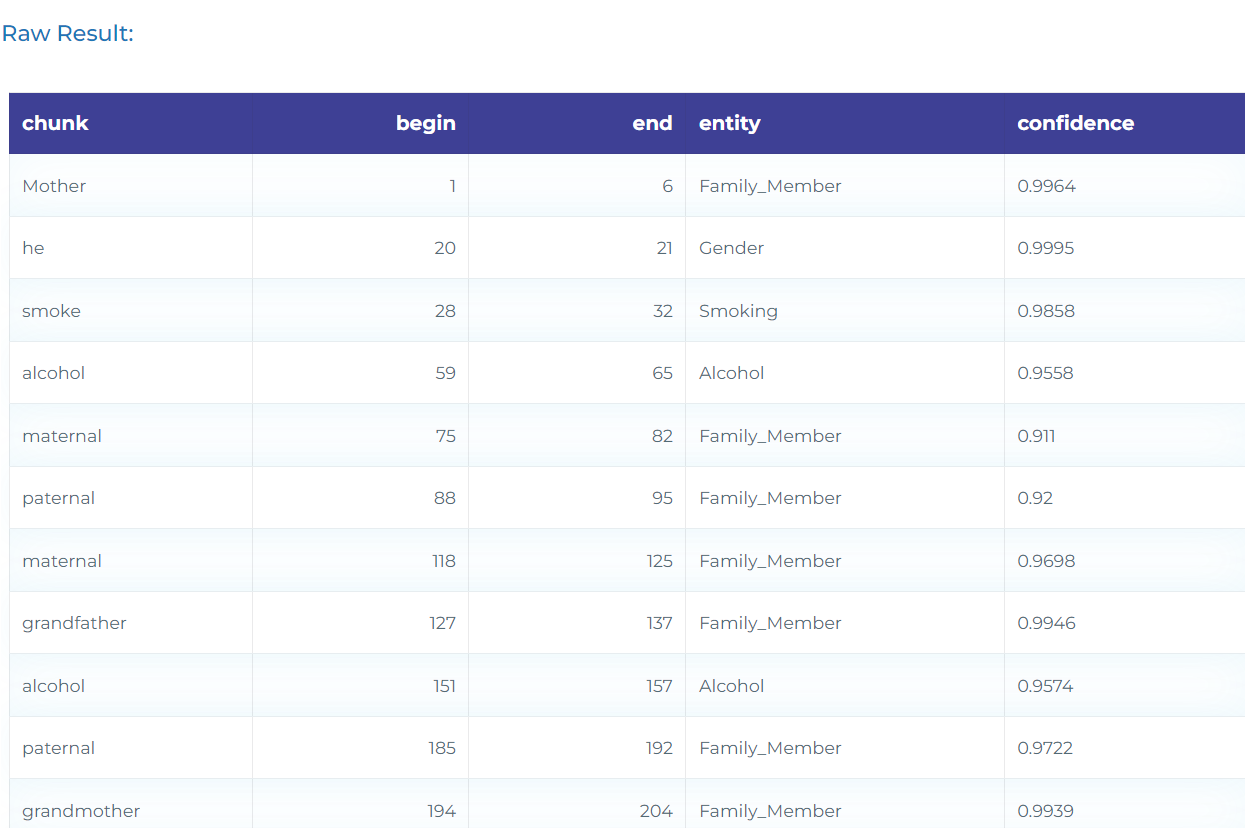
- Detecting clinical entities in text. For instance, the below NER deep learning model automatically detects more than 50 clinical entities.

- Detecting adverse reactions of drugs in reviews, tweets, and medical text.
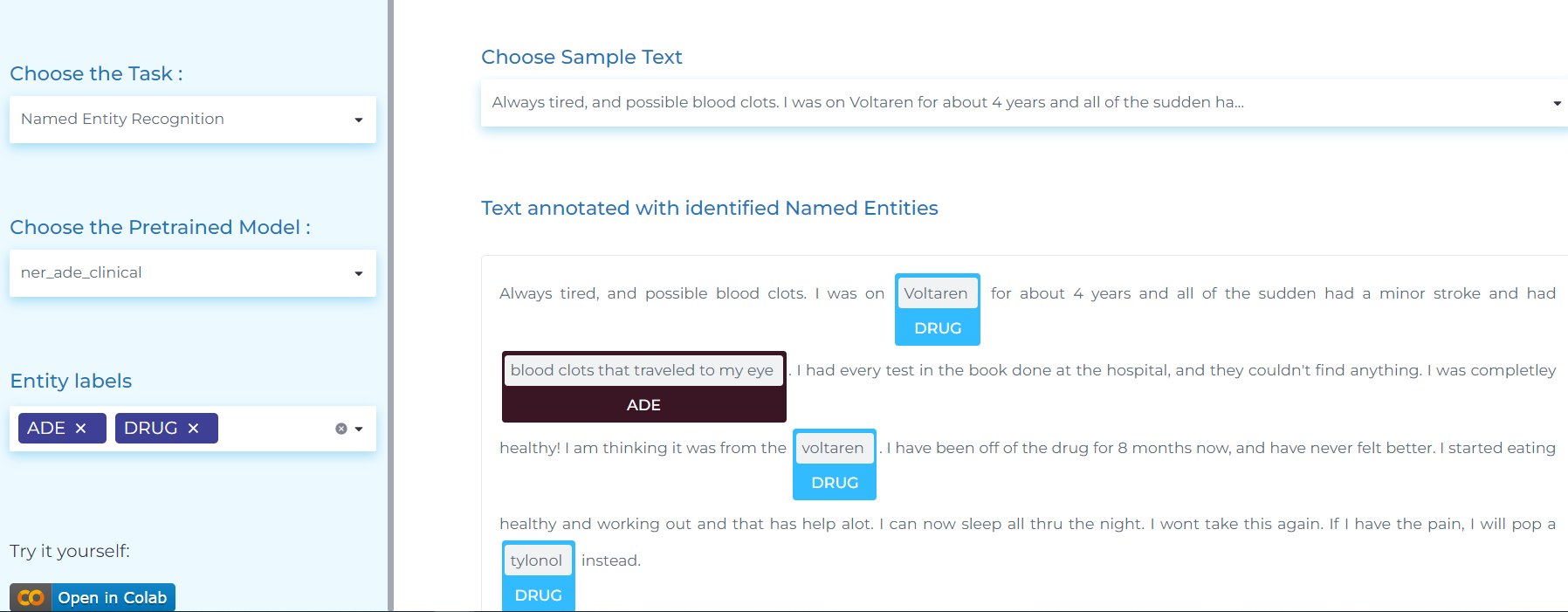
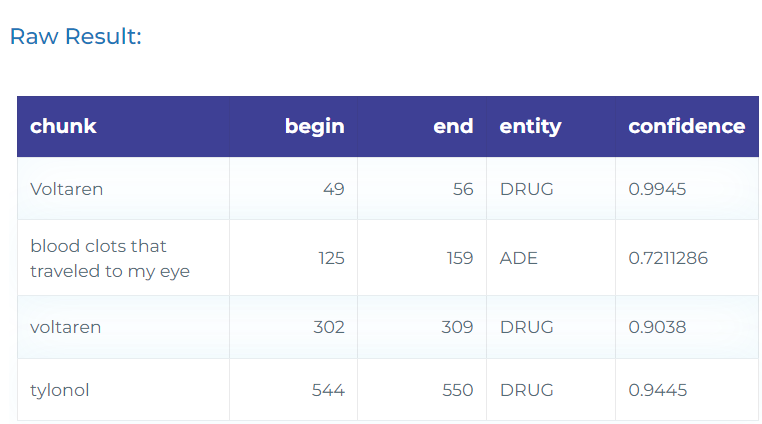
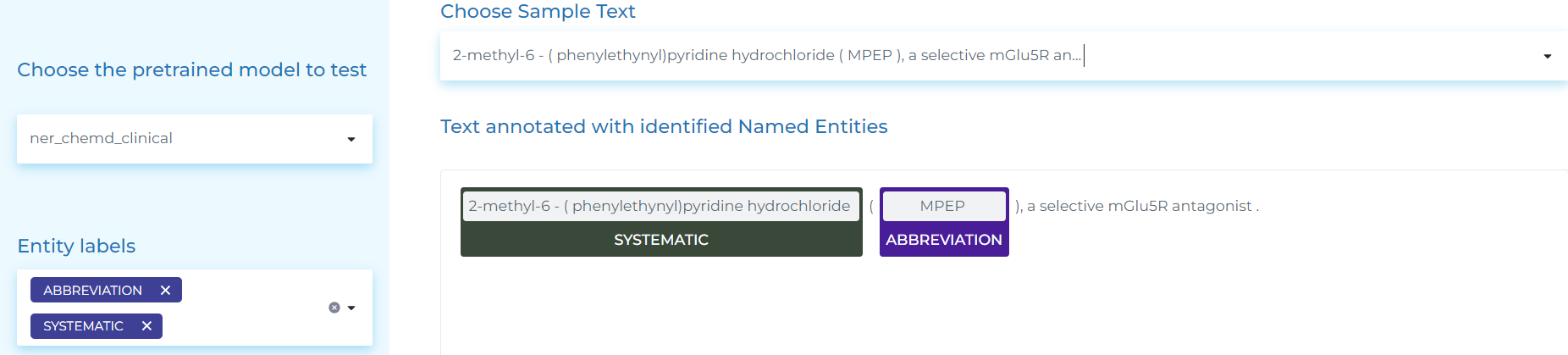
- Extracting names of chemicals, drugs and their abbreviations.
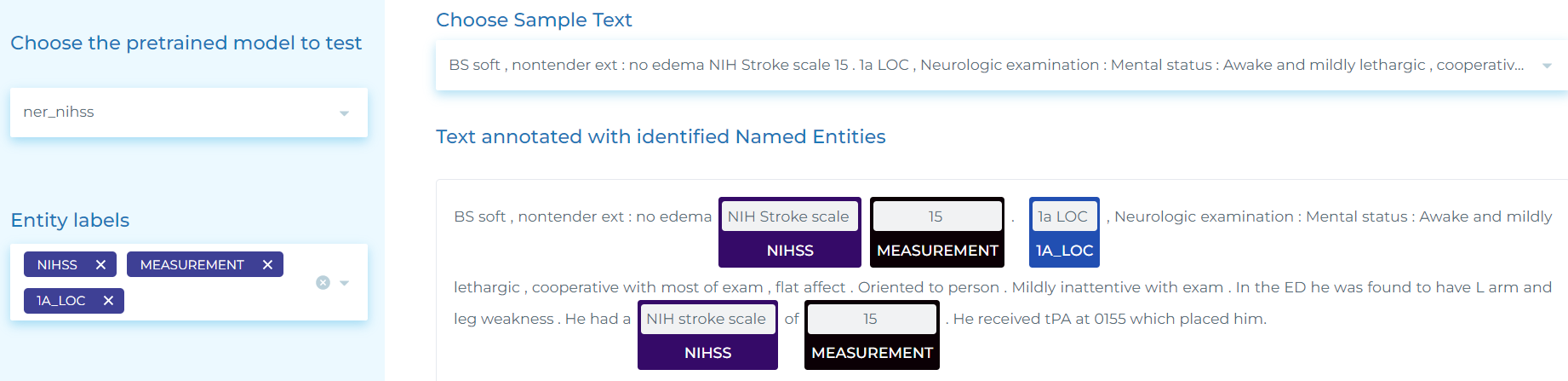
- Extracting neurologic deficits related to NIH Stroke Scale (NIHSS).
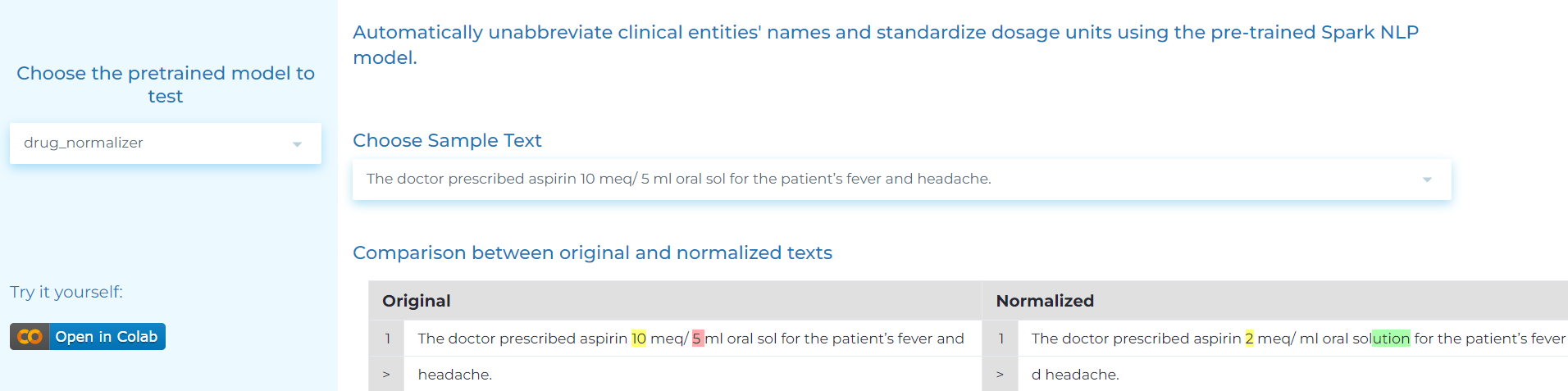
- Normalizing medication-related phrases such as dosage, form and strength, as well as abbreviations in text and named entities.
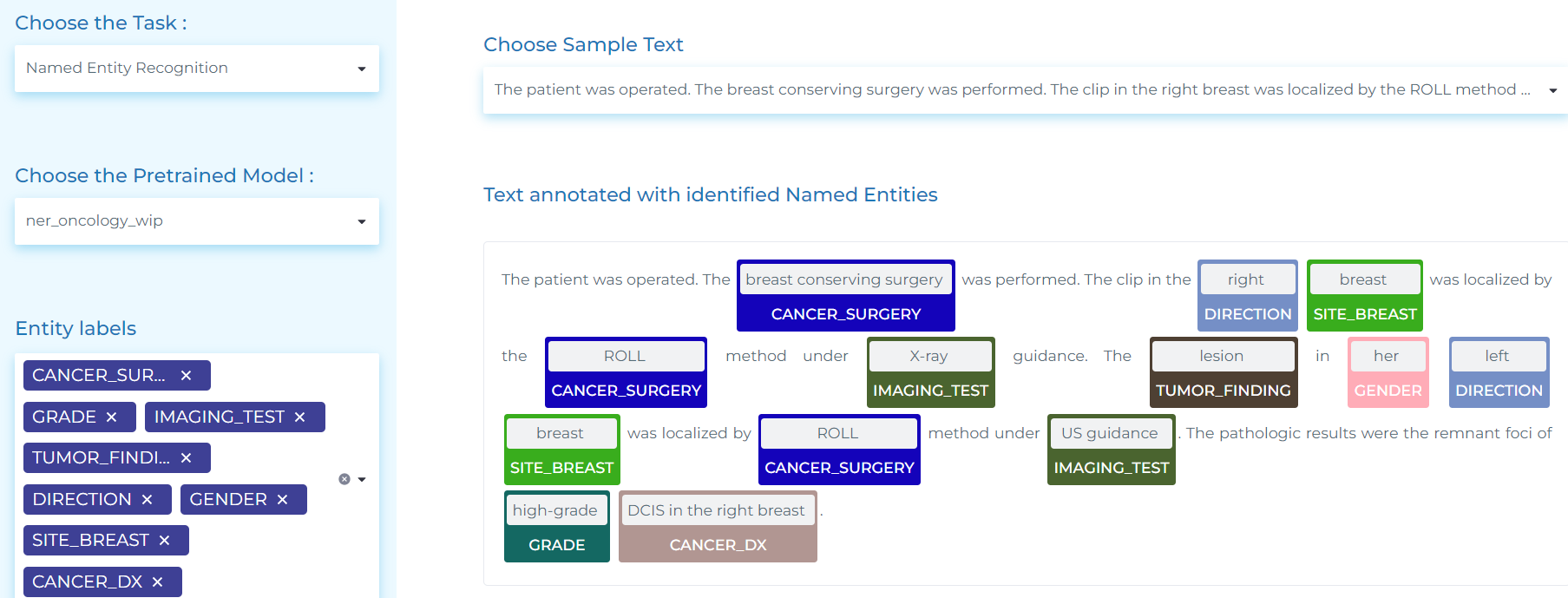
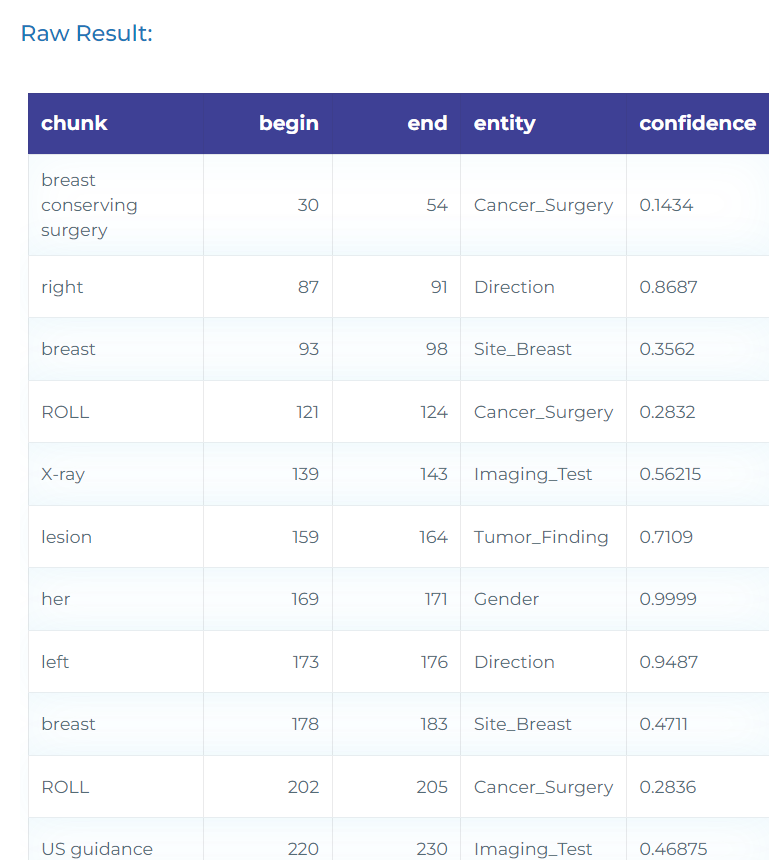
- Exploring oncological terms.
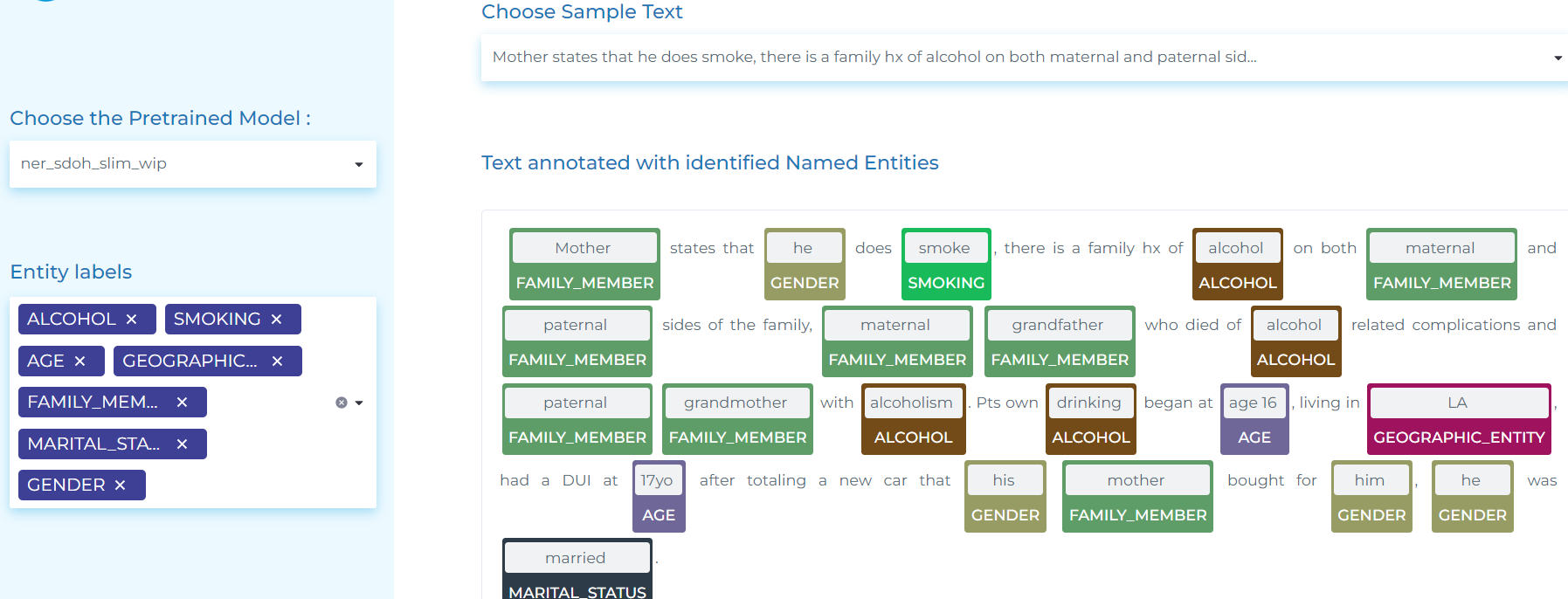
- Detecting social determinants of health entities.
Challenges of NLP Named Entity Recognition
We know that Named Entity Recognition has a number of benefits, such as:
- Relevant information extraction
- Determining relationships between text data and entities
- Improving the accuracy of NLP tasks
- Identifying and classifying named entities in text
- Creating summaries of blogs, research papers, articles, etc.
But the performance of NER is challenged by certain limiting factors mentioned below.
Text Ambiguity
Text ambiguity can be of two types:
- Lexical Ambiguity – It is the presence of two or more possible meanings within a single word.
- Syntactic Ambiguity – It is the presence of two or more possible meanings with a single sentence or sequence of words.

In short, text ambiguity appears when a word or sequence of words have multiple meanings within a sentence.
Word Abbreviations
In Natural Language Processing, it is a tedious task to label abbreviated words for identification and expand them to original words. NER performance gets affected as these words can not be classified to their correct entity accordingly. Text preprocessing steps have to be added to handle this issue.
Lack of Resources
Languages like Punjabi, Bengali, Urdu, Arabian, Hindi, etc are resource-poor languages. So, it can be quite challenging for NER models to identify word entities when textual information resources lack.
Conclusion
The highly specific jargon in legal, financial, and medical documents, paired with the sheer amounts of text these industries generate present a massive opportunity for natural language processing to help automate, simplify, and optimize operations. John Snow Lab’s Finance, Legal, and Healthcare NLP provide current state-of-the-art accuracy, a broad set of out-of-the-box models for common use cases, and ease of use building them into production systems.
Financial Named Entity Recognition NLP models extract information like Company Name, Trading symbols, Stock markets, Addresses, Phones, ORG (Organization names) and PRODUCT (Product names), etc.
Legal NLP NER models detect Whereas clauses and extract entities from them, extract law and money entities from legal texts, etc.
Healthcare NLP NER models detect clinical entities in text, extract names of chemicals and drugs, explore oncological terms, etc.
Get started here to enjoy the live demos and see which of our models best apply to your use case.
Read also related articles on the topic:
Named Entity Recognition Python
Explore how our team uses NLP libraries in real NLP use cases.



